 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Disentangling of Facial Representations with 3D-aware Latent Diffusion Models
Paper and Code
Sep 15, 2023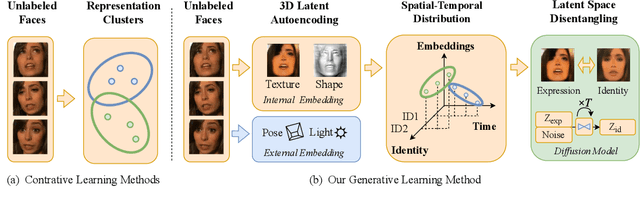
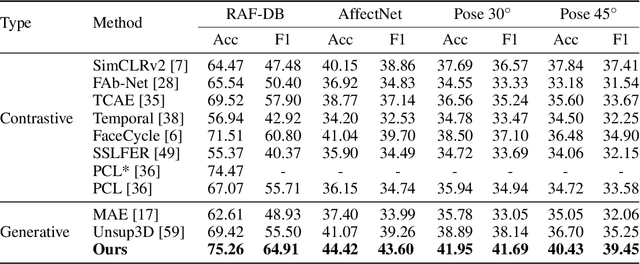
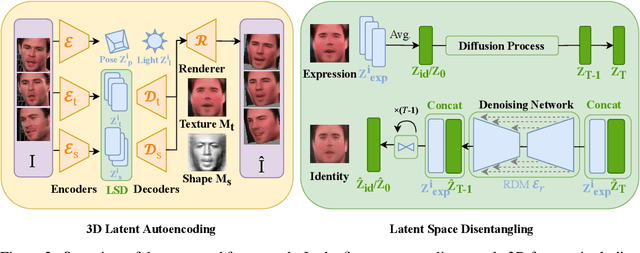
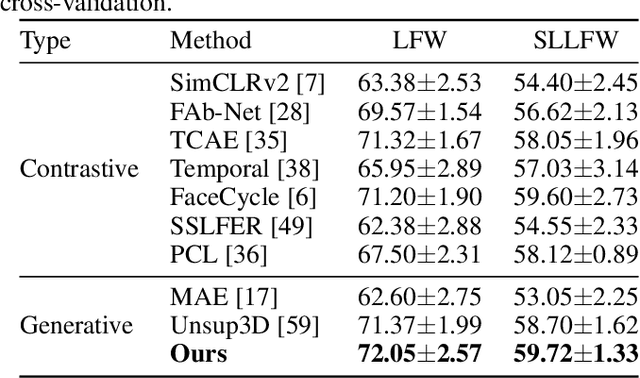
Unsupervised learning of facial representations has gained increasing attention for face understanding ability without heavily relying on large-scale annotated datasets. However, it remains unsolved due to the coupling of facial identities, expressions, and external factors like pose and light. Prior methods primarily focus on 2D factors and pixel-level consistency, leading to incomplete disentangling and suboptimal performance in downstream tasks. In this paper, we propose LatentFace, a novel unsupervised disentangling framework for facial expression and identity representation. We suggest the disentangling problem should be performed in latent space and propose the solution using a 3D-ware latent diffusion model. First, we introduce a 3D-aware autoencoder to encode face images into 3D latent embeddings. Second, we propose a novel representation diffusion model (RDM) to disentangle 3D latent into facial identity and expression. Consequently, our method achieves state-of-the-art performance in facial expression recognition and face verification among unsupervised facial representation learning models.