 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroWorld: Empowering Multimodal Large Language Models to Bridge the Microscopic Domain Gap with Multimodal Attribute Graph
May 11, 2026Multimodal large language models (MLLMs) show remarkable potential for scientific reasoning, yet their performance in specialized domains such as microscopy remains limited by the scarcity of domain-specific training data and the difficulty of encoding fine-grained expert knowledge into model parameters. To bridge the gap, we introduce MicroWorld, a framework that constructs a multimodal attributed property graph (MAPG) from large-scale scientific image--caption corpora and leverages it to augment MLLM reasoning at inference time without any domain-specific fine-tuning. MicroWorld extracts biomedical entities and relations via scispaCy or LLM-based triplet mining, aligns images and entities in a shared embedding space using Qwen3-VL-Embedding, and assembles a knowledge graph comprising approximately 111K nodes and 346K typed edges spanning eight relation categories. At inference time, a graph-augmented retrieval pipeline matches query entities to the MAPG and injects structured knowledge context into the MLLM prompt. On the MicroVQA benchmark, MicroWorld improves the reasoning performance of Qwen3-VL-8B-Instruct by 37.5%, outperforming GPT-5 by 13.0% to achieve a new state-of-the-art. Furthermore, it yields a 6.0% performance gain on the MicroBench benchmark. Extensive experiments demonstrate the enhanced generalization capability introduced by MicroWorld. A qualitative case study further reveals both the mechanisms through which structured knowledge improves reasoning and the failure modes that point to promising future directions. Code and data are available at https://github.com/ieellee/MicroWorld.
MicroVQA++: High-Quality Microscopy Reasoning Dataset with Weakly Supervised Graphs for Multimodal Large Language Model
Nov 14, 2025Multimodal Large Language Models are increasingly applied to biomedical imaging, yet scientific reasoning for microscopy remains limited by the scarcity of large-scale, high-quality training data. We introduce MicroVQA++, a three-stage, large-scale and high-quality microscopy VQA corpus derived from the BIOMEDICA archive. Stage one bootstraps supervision from expert-validated figure-caption pairs sourced from peer-reviewed articles. Stage two applies HiCQA-Graph, a novel heterogeneous graph over images, captions, and QAs that fuses NLI-based textual entailment, CLIP-based vision-language alignment, and agent signals to identify and filter inconsistent samples. Stage three uses a MultiModal Large Language Model (MLLM) agent to generate multiple-choice questions (MCQ) followed by human screening. The resulting release comprises a large training split and a human-checked test split whose Bloom's level hard-sample distribution exceeds the MicroVQA benchmark. Our work delivers (i) a quality-controlled dataset that couples expert literature with graph-based filtering and human refinement; (ii) HiCQA-Graph, the first graph that jointly models (image, caption, QA) for cross-modal consistency filtering; (iii) evidence that careful data construction enables 4B-scale MLLMs to reach competitive microscopy reasoning performance (e.g., GPT-5) and achieve state-of-the-art performance among open-source MLLMs. Code and dataset will be released after the review process concludes.
MM-Skin: Enhancing Dermatology Vision-Language Model with an Image-Text Dataset Derived from Textbooks
May 09, 2025Medical vision-language models (VLMs) have shown promise as clinical assistants across various medical fields. However, specialized dermatology VLM capable of delivering professional and detailed diagnostic analysis remains underdeveloped, primarily due to less specialized text descriptions in current dermatology multimodal datasets. To address this issue, we propose MM-Skin, the first large-scale multimodal dermatology dataset that encompasses 3 imaging modalities, including clinical, dermoscopic, and pathological and nearly 10k high-quality image-text pairs collected from professional textbooks. In addition, we generate over 27k diverse, instruction-following vision question answering (VQA) samples (9 times the size of current largest dermatology VQA dataset). Leveraging public datasets and MM-Skin, we developed SkinVL, a dermatology-specific VLM designed for precise and nuanced skin disease interpretation. Comprehensive benchmark evaluations of SkinVL on VQA, supervised fine-tuning (SFT) and zero-shot classification tasks across 8 datasets, reveal its exceptional performance for skin diseases in comparison to both general and medical VLM models. The introduction of MM-Skin and SkinVL offers a meaningful contribution to advancing the development of clinical dermatology VLM assistants. MM-Skin is available at https://github.com/ZwQ803/MM-Skin
Scaling Laws for Data-Efficient Visual Transfer Learning
Apr 17, 2025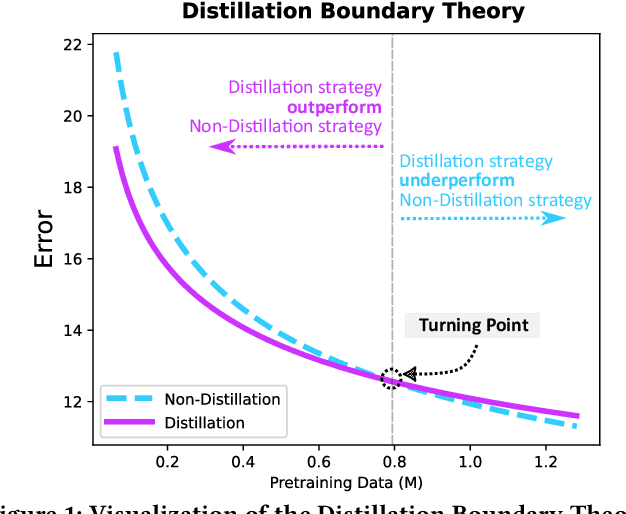
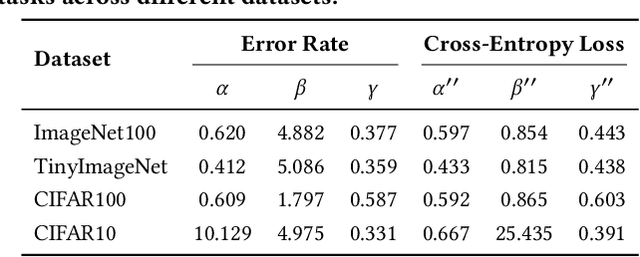
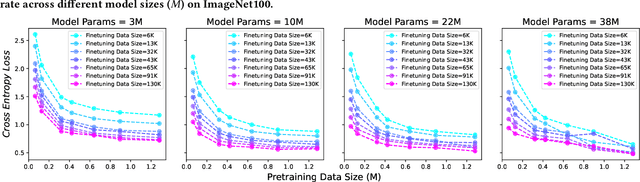
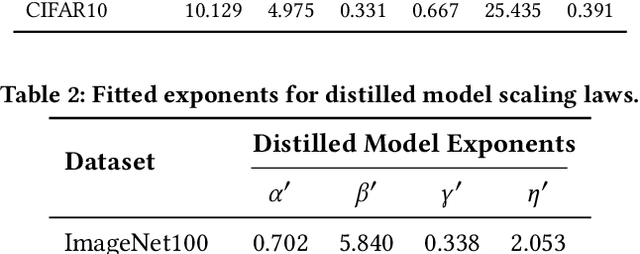
Current scaling laws for visual AI models focus predominantly on large-scale pretraining, leaving a critical gap in understanding how performance scales for data-constrained downstream tasks. To address this limitation, this paper establishes the first practical framework for data-efficient scaling laws in visual transfer learning, addressing two fundamental questions: 1) How do scaling behaviors shift when downstream tasks operate with limited data? 2) What governs the efficacy of knowledge distillation under such constraints? Through systematic analysis of vision tasks across data regimes (1K-1M samples), we propose the distillation boundary theory, revealing a critical turning point in distillation efficiency: 1) Distillation superiority: In data-scarce conditions, distilled models significantly outperform their non-distillation counterparts, efficiently leveraging inherited knowledge to compensate for limited training samples. 2) Pre-training dominance: As pre-training data increases beyond a critical threshold, non-distilled models gradually surpass distilled versions, suggesting diminishing returns from knowledge inheritance when sufficient task-specific data becomes available. Empirical validation across various model scales (2.5M to 38M parameters) and data volumes demonstrate these performance inflection points, with error difference curves transitioning from positive to negative values at critical data thresholds, confirming our theoretical predictions. This work redefines scaling laws for data-limited regimes, bridging the knowledge gap between large-scale pretraining and practical downstream adaptation, addressing a critical barrier to understanding vision model scaling behaviors and optimizing computational resource allocation.
Non-Uniform Class-Wise Coreset Selection: Characterizing Category Difficulty for Data-Efficient Transfer Learning
Apr 17, 2025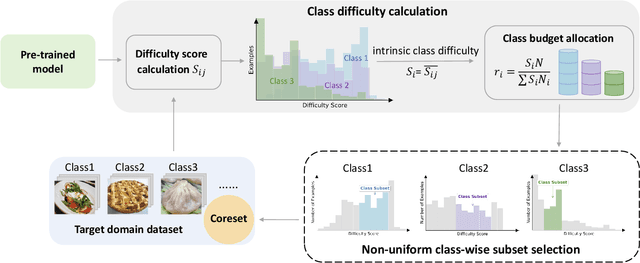
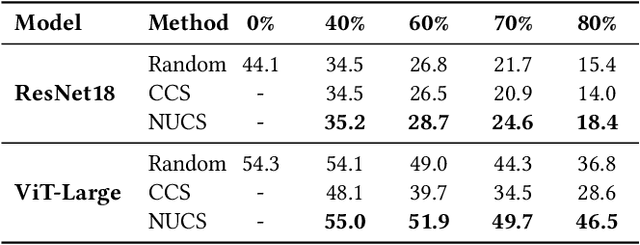
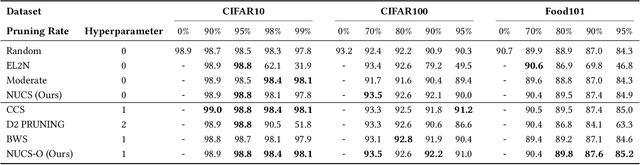
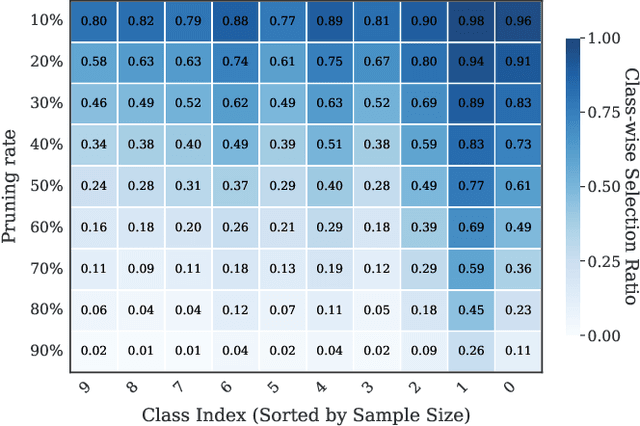
As transfer learning models and datasets grow larger, efficient adaptation and storage optimization have become critical needs. Coreset selection addresses these challenges by identifying and retaining the most informative samples, constructing a compact subset for target domain training. However, current methods primarily rely on instance-level difficulty assessments, overlooking crucial category-level characteristics and consequently under-representing minority classes. To overcome this limitation, we propose Non-Uniform Class-Wise Coreset Selection (NUCS), a novel framework that integrates both class-level and instance-level criteria. NUCS automatically allocates data selection budgets for each class based on intrinsic category difficulty and adaptively selects samples within optimal difficulty ranges. By explicitly incorporating category-specific insights, our approach achieves a more balanced and representative coreset, addressing key shortcomings of prior methods. Comprehensive theoretical analysis validates the rationale behind adaptive budget allocation and sample selection, while extensive experiments across 14 diverse datasets and model architectures demonstrate NUCS's consistent improvements over state-of-the-art methods, achieving superior accuracy and computational efficiency. Notably, on CIFAR100 and Food101, NUCS matches full-data training accuracy while retaining just 30% of samples and reducing computation time by 60%. Our work highlights the importance of characterizing category difficulty in coreset selection, offering a robust and data-efficient solution for transfer learning.
Multi-Modality Deep Network for JPEG Artifacts Reduction
May 04, 2023



In recent years, many convolutional neural network-based models are designed for JPEG artifacts reduction, and have achieved notable progress. However, few methods are suitable for extreme low-bitrate image compression artifacts reduction. The main challenge is that the highly compressed image loses too much information, resulting in reconstructing high-quality image difficultly. To address this issue, we propose a multimodal fusion learning method for text-guided JPEG artifacts reduction, in which the corresponding text description not only provides the potential prior information of the highly compressed image, but also serves as supplementary information to assist in image deblocking. We fuse image features and text semantic features from the global and local perspectives respectively, and design a contrastive loss built upon contrastive learning to produce visually pleasing results. Extensive experiments, including a user study, prove that our method can obtain better deblocking results compared to the state-of-the-art methods.
Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution
Jul 21, 2022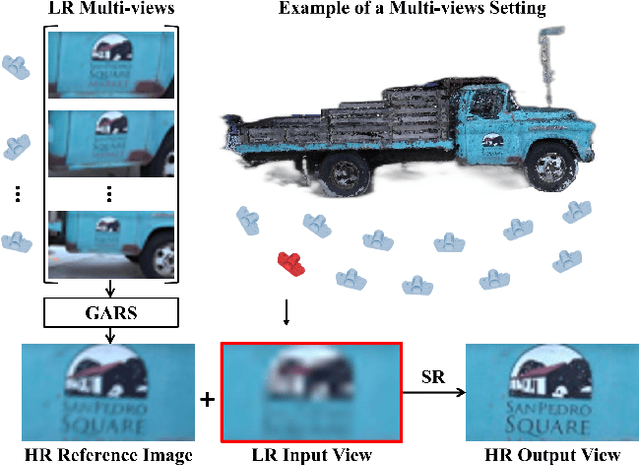
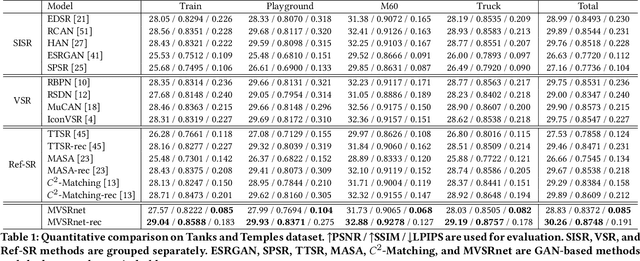

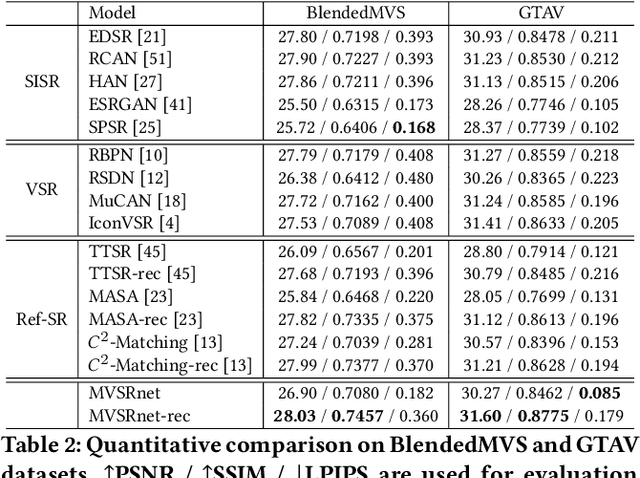
Recent multi-view multimedia applications struggle between high-resolution (HR) visual experience and storage or bandwidth constraints. Therefore, this paper proposes a Multi-View Image Super-Resolution (MVISR) task. It aims to increase the resolution of multi-view images captured from the same scene. One solution is to apply image or video super-resolution (SR) methods to reconstruct HR results from the low-resolution (LR) input view. However, these methods cannot handle large-angle transformations between views and leverage information in all multi-view images. To address these problems, we propose the MVSRnet, which uses geometry information to extract sharp details from all LR multi-view to support the SR of the LR input view. Specifically, the proposed Geometry-Aware Reference Synthesis module in MVSRnet uses geometry information and all multi-view LR images to synthesize pixel-aligned HR reference images. Then, the proposed Dynamic High-Frequency Search network fully exploits the high-frequency textural details in reference images for SR. Extensive experiments on several benchmarks show that our method significantly improves over the state-of-the-art approaches.
Perception-Oriented Stereo Image Super-Resolution
Jul 14, 2022Recent studies of deep learning based stereo image super-resolution (StereoSR) have promoted the development of StereoSR. However, existing StereoSR models mainly concentrate on improving quantitative evaluation metrics and neglect the visual quality of super-resolved stereo images. To improve the perceptual performance, this paper proposes the first perception-oriented stereo image super-resolution approach by exploiting the feedback, provided by the evaluation on the perceptual quality of StereoSR results. To provide accurate guidance for the StereoSR model, we develop the first special stereo image super-resolution quality assessment (StereoSRQA) model, and further construct a StereoSRQA database. Extensive experiments demonstrate that our StereoSR approach significantly improves the perceptual quality and enhances the reliability of stereo images for disparity estimation.
Rethinking Super-Resolution as Text-Guided Details Generation
Jul 14, 2022

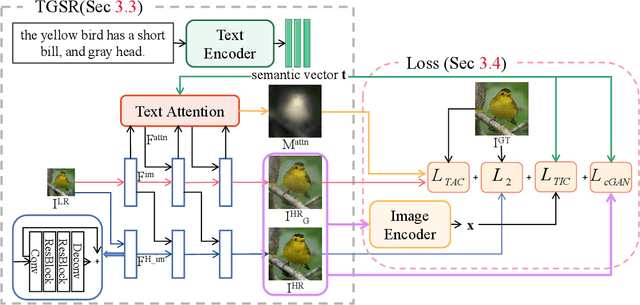
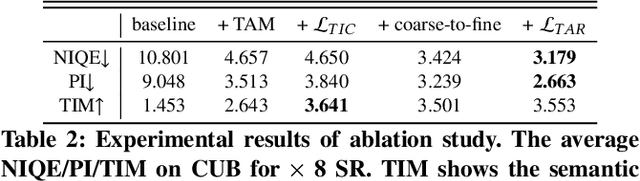
Deep neural networks have greatly promoted the performance of single image super-resolution (SISR). Conventional methods still resort to restoring the single high-resolution (HR) solution only based on the input of image modality. However, the image-level information is insufficient to predict adequate details and photo-realistic visual quality facing large upscaling factors (x8, x16). In this paper, we propose a new perspective that regards the SISR as a semantic image detail enhancement problem to generate semantically reasonable HR image that are faithful to the ground truth. To enhance the semantic accuracy and the visual quality of the reconstructed image, we explore the multi-modal fusion learning in SISR by proposing a Text-Guided Super-Resolution (TGSR) framework, which can effectively utilize the information from the text and image modalities. Different from existing methods, the proposed TGSR could generate HR image details that match the text descriptions through a coarse-to-fine process. Extensive experiments and ablation studies demonstrate the effect of the TGSR, which exploits the text reference to recover realistic images.