 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Data-Efficient Visual Transfer Learning
Apr 17, 2025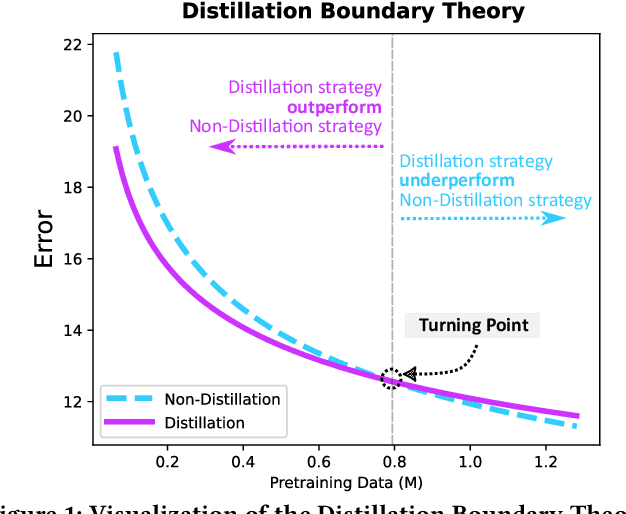
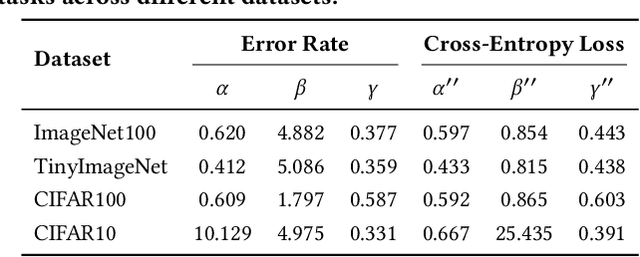
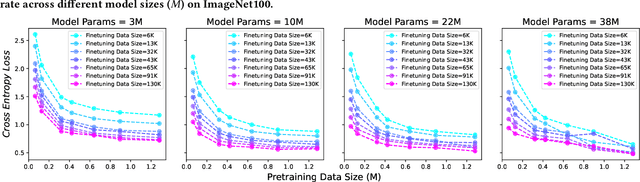
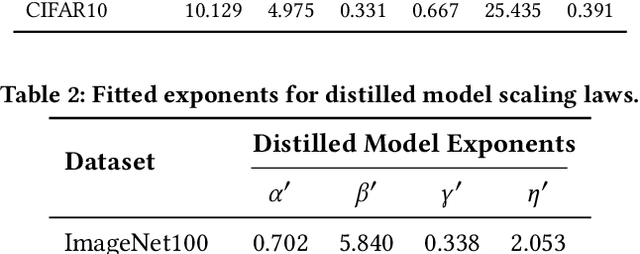
Current scaling laws for visual AI models focus predominantly on large-scale pretraining, leaving a critical gap in understanding how performance scales for data-constrained downstream tasks. To address this limitation, this paper establishes the first practical framework for data-efficient scaling laws in visual transfer learning, addressing two fundamental questions: 1) How do scaling behaviors shift when downstream tasks operate with limited data? 2) What governs the efficacy of knowledge distillation under such constraints? Through systematic analysis of vision tasks across data regimes (1K-1M samples), we propose the distillation boundary theory, revealing a critical turning point in distillation efficiency: 1) Distillation superiority: In data-scarce conditions, distilled models significantly outperform their non-distillation counterparts, efficiently leveraging inherited knowledge to compensate for limited training samples. 2) Pre-training dominance: As pre-training data increases beyond a critical threshold, non-distilled models gradually surpass distilled versions, suggesting diminishing returns from knowledge inheritance when sufficient task-specific data becomes available. Empirical validation across various model scales (2.5M to 38M parameters) and data volumes demonstrate these performance inflection points, with error difference curves transitioning from positive to negative values at critical data thresholds, confirming our theoretical predictions. This work redefines scaling laws for data-limited regimes, bridging the knowledge gap between large-scale pretraining and practical downstream adaptation, addressing a critical barrier to understanding vision model scaling behaviors and optimizing computational resource allocation.