 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Spatial-Frequency Fusion Mamba for Multi-Modal Image Fusion
Feb 04, 2026Multi-Modal Image Fusion (MMIF) aims to combine images from different modalities to produce fused images, retaining texture details and preserving significant information. Recently, some MMIF methods incorporate frequency domain information to enhance spatial features. However, these methods typically rely on simple serial or parallel spatial-frequency fusion without interaction. In this paper, we propose a novel Interactive Spatial-Frequency Fusion Mamba (ISFM) framework for MMIF. Specifically, we begin with a Modality-Specific Extractor (MSE) to extract features from different modalities. It models long-range dependencies across the image with linear computational complexity. To effectively leverage frequency information, we then propose a Multi-scale Frequency Fusion (MFF). It adaptively integrates low-frequency and high-frequency components across multiple scales, enabling robust representations of frequency features. More importantly, we further propose an Interactive Spatial-Frequency Fusion (ISF). It incorporates frequency features to guide spatial features across modalities, enhancing complementary representations. Extensive experiments are conducted on six MMIF datasets. The experimental results demonstrate that our ISFM can achieve better performances than other state-of-the-art methods. The source code is available at https://github.com/Namn23/ISFM.
Stabilizing Diffusion Posterior Sampling by Noise--Frequency Continuation
Jan 30, 2026Diffusion posterior sampling solves inverse problems by combining a pretrained diffusion prior with measurement-consistency guidance, but it often fails to recover fine details because measurement terms are applied in a manner that is weakly coupled to the diffusion noise level. At high noise, data-consistency gradients computed from inaccurate estimates can be geometrically incongruent with the posterior geometry, inducing early-step drift, spurious high-frequency artifacts, plus sensitivity to schedules and ill-conditioned operators. To address these concerns, we propose a noise--frequency Continuation framework that constructs a continuous family of intermediate posteriors whose likelihood enforces measurement consistency only within a noise-dependent frequency band. This principle is instantiated with a stabilized posterior sampler that combines a diffusion predictor, band-limited likelihood guidance, and a multi-resolution consistency strategy that aggressively commits reliable coarse corrections while conservatively adopting high-frequency details only when they become identifiable. Across super-resolution, inpainting, and deblurring, our method achieves state-of-the-art performance and improves motion deblurring PSNR by up to 5 dB over strong baselines.
Training LLMs with Fault Tolerant HSDP on 100,000 GPUs
Jan 30, 2026Large-scale training systems typically use synchronous training, requiring all GPUs to be healthy simultaneously. In our experience training on O(100K) GPUs, synchronous training results in a low efficiency due to frequent failures and long recovery time. To address this problem, we propose a novel training paradigm, Fault Tolerant Hybrid-Shared Data Parallelism (FT-HSDP). FT-HSDP uses data parallel replicas as units of fault tolerance. When failures occur, only a single data-parallel replica containing the failed GPU or server is taken offline and restarted, while the other replicas continue training. To realize this idea at scale, FT-HSDP incorporates several techniques: 1) We introduce a Fault Tolerant All Reduce (FTAR) protocol for gradient exchange across data parallel replicas. FTAR relies on the CPU to drive the complex control logic for tasks like adding or removing participants dynamically, and relies on GPU to perform data transfer for best performance. 2) We introduce a non-blocking catch-up protocol, allowing a recovering replica to join training with minimal stall. Compared with fully synchronous training at O(100K) GPUs, FT-HSDP can reduce the stall time due to failure recovery from 10 minutes to 3 minutes, increasing effective training time from 44\% to 80\%. We further demonstrate that FT-HSDP's asynchronous recovery does not bring any meaning degradation to the accuracy of the result model.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
RSATalker: Realistic Socially-Aware Talking Head Generation for Multi-Turn Conversation
Jan 15, 2026Talking head generation is increasingly important in virtual reality (VR), especially for social scenarios involving multi-turn conversation. Existing approaches face notable limitations: mesh-based 3D methods can model dual-person dialogue but lack realistic textures, while large-model-based 2D methods produce natural appearances but incur prohibitive computational costs. Recently, 3D Gaussian Splatting (3DGS) based methods achieve efficient and realistic rendering but remain speaker-only and ignore social relationships. We introduce RSATalker, the first framework that leverages 3DGS for realistic and socially-aware talking head generation with support for multi-turn conversation. Our method first drives mesh-based 3D facial motion from speech, then binds 3D Gaussians to mesh facets to render high-fidelity 2D avatar videos. To capture interpersonal dynamics, we propose a socially-aware module that encodes social relationships, including blood and non-blood as well as equal and unequal, into high-level embeddings through a learnable query mechanism. We design a three-stage training paradigm and construct the RSATalker dataset with speech-mesh-image triplets annotated with social relationships. Extensive experiments demonstrate that RSATalker achieves state-of-the-art performance in both realism and social awareness. The code and dataset will be released.
TCDE: Topic-Centric Dual Expansion of Queries and Documents with Large Language Models for Information Retrieval
Dec 19, 2025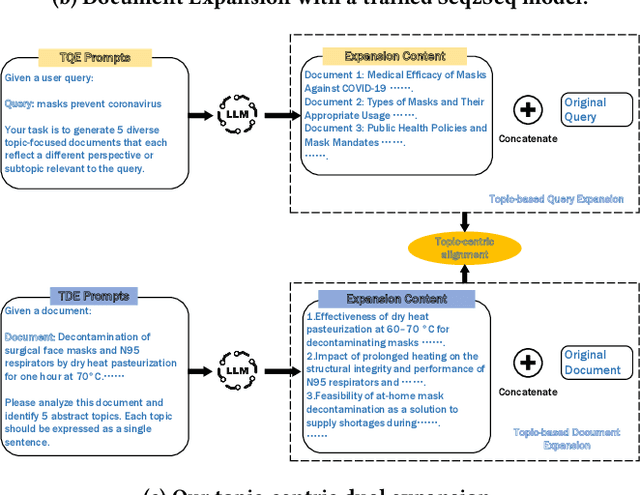

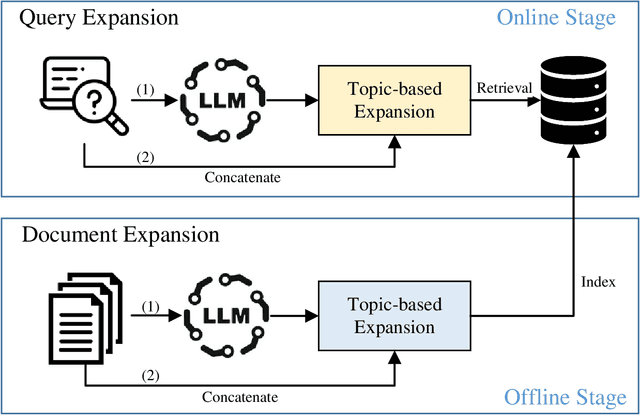

Query Expansion (QE) enriches queries and Document Expansion (DE) enriches documents, and these two techniques are often applied separately. However, such separate application may lead to semantic misalignment between the expanded queries (or documents) and their relevant documents (or queries). To address this serious issue, we propose TCDE, a dual expansion strategy that leverages large language models (LLMs) for topic-centric enrichment on both queries and documents. In TCDE, we design two distinct prompt templates for processing each query and document. On the query side, an LLM is guided to identify distinct sub-topics within each query and generate a focused pseudo-document for each sub-topic. On the document side, an LLM is guided to distill each document into a set of core topic sentences. The resulting outputs are used to expand the original query and document. This topic-centric dual expansion process establishes semantic bridges between queries and their relevant documents, enabling better alignment for downstream retrieval models. Experiments on two challenging benchmarks, TREC Deep Learning and BEIR, demonstrate that TCDE achieves substantial improvements over strong state-of-the-art expansion baselines. In particular, on dense retrieval tasks, it outperforms several state-of-the-art methods, with a relative improvement of 2.8\% in NDCG@10 on the SciFact dataset. Experimental results validate the effectiveness of our topic-centric and dual expansion strategy.
Spatial-Frequency Enhanced Mamba for Multi-Modal Image Fusion
Nov 10, 2025Multi-Modal Image Fusion (MMIF) aims to integrate complementary image information from different modalities to produce informative images. Previous deep learning-based MMIF methods generally adopt Convolutional Neural Networks (CNNs) or Transformers for feature extraction. However, these methods deliver unsatisfactory performances due to the limited receptive field of CNNs and the high computational cost of Transformers. Recently, Mamba has demonstrated a powerful potential for modeling long-range dependencies with linear complexity, providing a promising solution to MMIF. Unfortunately, Mamba lacks full spatial and frequency perceptions, which are very important for MMIF. Moreover, employing Image Reconstruction (IR) as an auxiliary task has been proven beneficial for MMIF. However, a primary challenge is how to leverage IR efficiently and effectively. To address the above issues, we propose a novel framework named Spatial-Frequency Enhanced Mamba Fusion (SFMFusion) for MMIF. More specifically, we first propose a three-branch structure to couple MMIF and IR, which can retain complete contents from source images. Then, we propose the Spatial-Frequency Enhanced Mamba Block (SFMB), which can enhance Mamba in both spatial and frequency domains for comprehensive feature extraction. Finally, we propose the Dynamic Fusion Mamba Block (DFMB), which can be deployed across different branches for dynamic feature fusion. Extensive experiments show that our method achieves better results than most state-of-the-art methods on six MMIF datasets. The source code is available at https://github.com/SunHui1216/SFMFusion.
TradingGroup: A Multi-Agent Trading System with Self-Reflection and Data-Synthesis
Aug 25, 2025Recent advancements in large language models (LLMs) have enabled powerful agent-based applications in finance, particularly for sentiment analysis, financial report comprehension, and stock forecasting. However, existing systems often lack inter-agent coordination, structured self-reflection, and access to high-quality, domain-specific post-training data such as data from trading activities including both market conditions and agent decisions. These data are crucial for agents to understand the market dynamics, improve the quality of decision-making and promote effective coordination. We introduce TradingGroup, a multi-agent trading system designed to address these limitations through a self-reflective architecture and an end-to-end data-synthesis pipeline. TradingGroup consists of specialized agents for news sentiment analysis, financial report interpretation, stock trend forecasting, trading style adaptation, and a trading decision making agent that merges all signals and style preferences to produce buy, sell or hold decisions. Specifically, we design self-reflection mechanisms for the stock forecasting, style, and decision-making agents to distill past successes and failures for similar reasoning in analogous future scenarios and a dynamic risk-management model to offer configurable dynamic stop-loss and take-profit mechanisms. In addition, TradingGroup embeds an automated data-synthesis and annotation pipeline that generates high-quality post-training data for further improving the agent performance through post-training. Our backtesting experiments across five real-world stock datasets demonstrate TradingGroup's superior performance over rule-based, machine learning, reinforcement learning, and existing LLM-based trading strategies.
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
P3Net: Progressive and Periodic Perturbation for Semi-Supervised Medical Image Segmentation
May 21, 2025Perturbation with diverse unlabeled data has proven beneficial for semi-supervised medical image segmentation (SSMIS). While many works have successfully used various perturbation techniques, a deeper understanding of learning perturbations is needed. Excessive or inappropriate perturbation can have negative effects, so we aim to address two challenges: how to use perturbation mechanisms to guide the learning of unlabeled data through labeled data, and how to ensure accurate predictions in boundary regions. Inspired by human progressive and periodic learning, we propose a progressive and periodic perturbation mechanism (P3M) and a boundary-focused loss. P3M enables dynamic adjustment of perturbations, allowing the model to gradually learn them. Our boundary-focused loss encourages the model to concentrate on boundary regions, enhancing sensitivity to intricate details and ensuring accurate predictions. Experimental results demonstrate that our method achieves state-of-the-art performance on two 2D and 3D datasets. Moreover, P3M is extendable to other methods, and the proposed loss serves as a universal tool for improving existing methods, highlighting the scalability and applicability of our approach.