 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAG: Multi-Modal Aligned Autoregressive Co-Speech Gesture Generation without Vector Quantization
Mar 18, 2025This work focuses on full-body co-speech gesture generation. Existing methods typically employ an autoregressive model accompanied by vector-quantized tokens for gesture generation, which results in information loss and compromises the realism of the generated gestures. To address this, inspired by the natural continuity of real-world human motion, we propose MAG, a novel multi-modal aligned framework for high-quality and diverse co-speech gesture synthesis without relying on discrete tokenization. Specifically, (1) we introduce a motion-text-audio-aligned variational autoencoder (MTA-VAE), which leverages pre-trained WavCaps' text and audio embeddings to enhance both semantic and rhythmic alignment with motion, ultimately producing more realistic gestures. (2) Building on this, we propose a multimodal masked autoregressive model (MMAG) that enables autoregressive modeling in continuous motion embeddings through diffusion without vector quantization. To further ensure multi-modal consistency, MMAG incorporates a hybrid granularity audio-text fusion block, which serves as conditioning for diffusion process. Extensive experiments on two benchmark datasets demonstrate that MAG achieves stateof-the-art performance both quantitatively and qualitatively, producing highly realistic and diverse co-speech gestures.The code will be released to facilitate future research.
VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting
Mar 16, 2025We propose VRSketch2Gaussian, a first VR sketch-guided, multi-modal, native 3D object generation framework that incorporates a 3D Gaussian Splatting representation. As part of our work, we introduce VRSS, the first large-scale paired dataset containing VR sketches, text, images, and 3DGS, bridging the gap in multi-modal VR sketch-based generation. Our approach features the following key innovations: 1) Sketch-CLIP feature alignment. We propose a two-stage alignment strategy that bridges the domain gap between sparse VR sketch embeddings and rich CLIP embeddings, facilitating both VR sketch-based retrieval and generation tasks. 2) Fine-Grained multi-modal conditioning. We disentangle the 3D generation process by using explicit VR sketches for geometric conditioning and text descriptions for appearance control. To facilitate this, we propose a generalizable VR sketch encoder that effectively aligns different modalities. 3) Efficient and high-fidelity 3D native generation. Our method leverages a 3D-native generation approach that enables fast and texture-rich 3D object synthesis. Experiments conducted on our VRSS dataset demonstrate that our method achieves high-quality, multi-modal VR sketch-based 3D generation. We believe our VRSS dataset and VRsketch2Gaussian method will be beneficial for the 3D generation community.
Exploring the Robustness of Human Parsers Towards Common Corruptions
Sep 07, 2023



Human parsing aims to segment each pixel of the human image with fine-grained semantic categories. However, current human parsers trained with clean data are easily confused by numerous image corruptions such as blur and noise. To improve the robustness of human parsers, in this paper, we construct three corruption robustness benchmarks, termed LIP-C, ATR-C, and Pascal-Person-Part-C, to assist us in evaluating the risk tolerance of human parsing models. Inspired by the data augmentation strategy, we propose a novel heterogeneous augmentation-enhanced mechanism to bolster robustness under commonly corrupted conditions. Specifically, two types of data augmentations from different views, i.e., image-aware augmentation and model-aware image-to-image transformation, are integrated in a sequential manner for adapting to unforeseen image corruptions. The image-aware augmentation can enrich the high diversity of training images with the help of common image operations. The model-aware augmentation strategy that improves the diversity of input data by considering the model's randomness. The proposed method is model-agnostic, and it can plug and play into arbitrary state-of-the-art human parsing frameworks. The experimental results show that the proposed method demonstrates good universality which can improve the robustness of the human parsing models and even the semantic segmentation models when facing various image common corruptions. Meanwhile, it can still obtain approximate performance on clean data.
Frequency Perception Network for Camouflaged Object Detection
Aug 17, 2023



Camouflaged object detection (COD) aims to accurately detect objects hidden in the surrounding environment. However, the existing COD methods mainly locate camouflaged objects in the RGB domain, their performance has not been fully exploited in many challenging scenarios. Considering that the features of the camouflaged object and the background are more discriminative in the frequency domain, we propose a novel learnable and separable frequency perception mechanism driven by the semantic hierarchy in the frequency domain. Our entire network adopts a two-stage model, including a frequency-guided coarse localization stage and a detail-preserving fine localization stage. With the multi-level features extracted by the backbone, we design a flexible frequency perception module based on octave convolution for coarse positioning. Then, we design the correction fusion module to step-by-step integrate the high-level features through the prior-guided correction and cross-layer feature channel association, and finally combine them with the shallow features to achieve the detailed correction of the camouflaged objects. Compared with the currently existing models, our proposed method achieves competitive performance in three popular benchmark datasets both qualitatively and quantitatively.
AIParsing: Anchor-free Instance-level Human Parsing
Jul 14, 2022
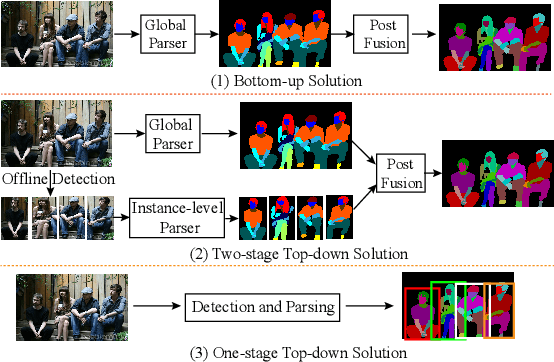
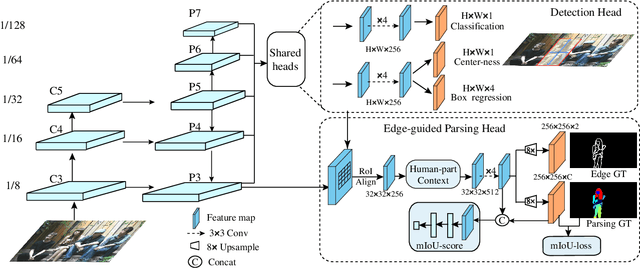

Most state-of-the-art instance-level human parsing models adopt two-stage anchor-based detectors and, therefore, cannot avoid the heuristic anchor box design and the lack of analysis on a pixel level. To address these two issues, we have designed an instance-level human parsing network which is anchor-free and solvable on a pixel level. It consists of two simple sub-networks: an anchor-free detection head for bounding box predictions and an edge-guided parsing head for human segmentation. The anchor-free detector head inherits the pixel-like merits and effectively avoids the sensitivity of hyper-parameters as proved in object detection applications. By introducing the part-aware boundary clue, the edge-guided parsing head is capable to distinguish adjacent human parts from among each other up to 58 parts in a single human instance, even overlapping instances. Meanwhile, a refinement head integrating box-level score and part-level parsing quality is exploited to improve the quality of the parsing results. Experiments on two multiple human parsing datasets (i.e., CIHP and LV-MHP-v2.0) and one video instance-level human parsing dataset (i.e., VIP) show that our method achieves the best global-level and instance-level performance over state-of-the-art one-stage top-down alternatives.
Nested Network with Two-Stream Pyramid for Salient Object Detection in Optical Remote Sensing Images
Jun 20, 2019



Arising from the various object types and scales, diverse imaging orientations, and cluttered backgrounds in optical remote sensing image (RSI), it is difficult to directly extend the success of salient object detection for nature scene image to the optical RSI. In this paper, we propose an end-to-end deep network called LV-Net based on the shape of network architecture, which detects salient objects from optical RSIs in a purely data-driven fashion. The proposed LV-Net consists of two key modules, i.e., a two-stream pyramid module (L-shaped module) and an encoder-decoder module with nested connections (V-shaped module). Specifically, the L-shaped module extracts a set of complementary information hierarchically by using a two-stream pyramid structure, which is beneficial to perceiving the diverse scales and local details of salient objects. The V-shaped module gradually integrates encoder detail features with decoder semantic features through nested connections, which aims at suppressing the cluttered backgrounds and highlighting the salient objects. In addition, we construct the first publicly available optical RSI dataset for salient object detection, including 800 images with varying spatial resolutions, diverse saliency types, and pixel-wise ground truth. Experiments on this benchmark dataset demonstrate that the proposed method outperforms the state-of-the-art salient object detection methods both qualitatively and quantitatively.