 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIParsing: Anchor-free Instance-level Human Parsing
Paper and Code
Jul 14, 2022
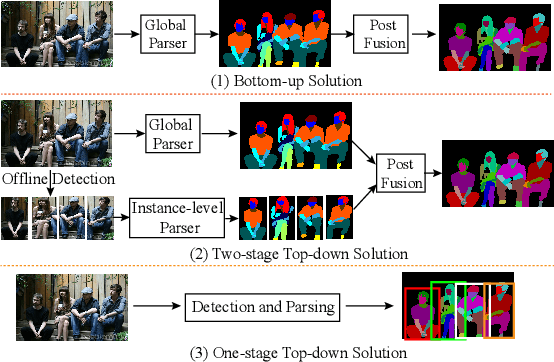
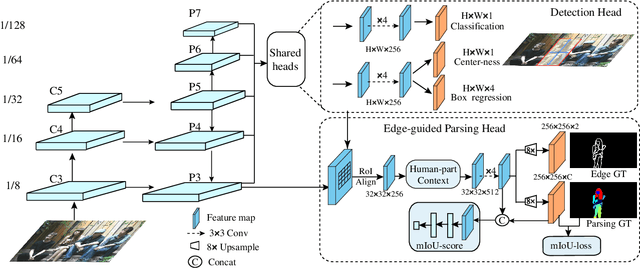

Most state-of-the-art instance-level human parsing models adopt two-stage anchor-based detectors and, therefore, cannot avoid the heuristic anchor box design and the lack of analysis on a pixel level. To address these two issues, we have designed an instance-level human parsing network which is anchor-free and solvable on a pixel level. It consists of two simple sub-networks: an anchor-free detection head for bounding box predictions and an edge-guided parsing head for human segmentation. The anchor-free detector head inherits the pixel-like merits and effectively avoids the sensitivity of hyper-parameters as proved in object detection applications. By introducing the part-aware boundary clue, the edge-guided parsing head is capable to distinguish adjacent human parts from among each other up to 58 parts in a single human instance, even overlapping instances. Meanwhile, a refinement head integrating box-level score and part-level parsing quality is exploited to improve the quality of the parsing results. Experiments on two multiple human parsing datasets (i.e., CIHP and LV-MHP-v2.0) and one video instance-level human parsing dataset (i.e., VIP) show that our method achieves the best global-level and instance-level performance over state-of-the-art one-stage top-down alternatives.