 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheraAgent: Self-Improving Therapeutic Agent for Precise and Comprehensive Treatment Planning
May 07, 2026Formulating a treatment plan is inherently a complex reasoning and refinement task rather than a simple generation problem. However, existing large language models (LLMs) mainly rely on one-shot output without explicit verification, which may result in rough, incomplete, and potentially unsafe treatment plans. To address these limitations, we propose TheraAgent, an agentic framework that replaces one-shot generation with an iterative generate-judge-refine pipeline. By mirroring the actual reasoning process of human experts who iteratively revise treatment plans, our framework progressively transforms coarse and incomplete drafts into precise, comprehensive, and safer therapeutic regimens. To facilitate the critical judge component, we introduce TheraJudge, a treatment-specific evaluation module integrated into the inference loop to enforce clinical standards. Experiments show TheraAgent achieves state-of-the-art results on HealthBench, leading in Accuracy and Completeness. In expert evaluations, it attains an 86% win rate against physicians, with superior Targeting and Harm Control. Moreover, the highly agreement between TheraJudge and HealthBench evaluations confirms the reliability of our framework.
Decentralized Optimization on Compact Submanifolds by Quantized Riemannian Gradient Tracking
Jun 09, 2025This paper considers the problem of decentralized optimization on compact submanifolds, where a finite sum of smooth (possibly non-convex) local functions is minimized by $n$ agents forming an undirected and connected graph. However, the efficiency of distributed optimization is often hindered by communication bottlenecks. To mitigate this, we propose the Quantized Riemannian Gradient Tracking (Q-RGT) algorithm, where agents update their local variables using quantized gradients. The introduction of quantization noise allows our algorithm to bypass the constraints of the accurate Riemannian projection operator (such as retraction), further improving iterative efficiency. To the best of our knowledge, this is the first algorithm to achieve an $\mathcal{O}(1/K)$ convergence rate in the presence of quantization, matching the convergence rate of methods without quantization. Additionally, we explicitly derive lower bounds on decentralized consensus associated with a function of quantization levels. Numerical experiments demonstrate that Q-RGT performs comparably to non-quantized methods while reducing communication bottlenecks and computational overhead.
MOM: Memory-Efficient Offloaded Mini-Sequence Inference for Long Context Language Models
Apr 16, 2025Long-context language models exhibit impressive performance but remain challenging to deploy due to high GPU memory demands during inference. We propose Memory-efficient Offloaded Mini-sequence Inference (MOM), a method that partitions critical layers into smaller "mini-sequences" and integrates seamlessly with KV cache offloading. Experiments on various Llama, Qwen, and Mistral models demonstrate that MOM reduces peak memory usage by over 50\% on average. On Meta-Llama-3.2-8B, MOM extends the maximum context length from 155k to 455k tokens on a single A100 80GB GPU, while keeping outputs identical and not compromising accuracy. MOM also maintains highly competitive throughput due to minimal computational overhead and efficient last-layer processing. Compared to traditional chunked prefill methods, MOM achieves a 35\% greater context length extension. More importantly, our method drastically reduces prefill memory consumption, eliminating it as the longstanding dominant memory bottleneck during inference. This breakthrough fundamentally changes research priorities, redirecting future efforts from prefill-stage optimizations to improving decode-stage residual KV cache efficiency.
MAG: Multi-Modal Aligned Autoregressive Co-Speech Gesture Generation without Vector Quantization
Mar 18, 2025This work focuses on full-body co-speech gesture generation. Existing methods typically employ an autoregressive model accompanied by vector-quantized tokens for gesture generation, which results in information loss and compromises the realism of the generated gestures. To address this, inspired by the natural continuity of real-world human motion, we propose MAG, a novel multi-modal aligned framework for high-quality and diverse co-speech gesture synthesis without relying on discrete tokenization. Specifically, (1) we introduce a motion-text-audio-aligned variational autoencoder (MTA-VAE), which leverages pre-trained WavCaps' text and audio embeddings to enhance both semantic and rhythmic alignment with motion, ultimately producing more realistic gestures. (2) Building on this, we propose a multimodal masked autoregressive model (MMAG) that enables autoregressive modeling in continuous motion embeddings through diffusion without vector quantization. To further ensure multi-modal consistency, MMAG incorporates a hybrid granularity audio-text fusion block, which serves as conditioning for diffusion process. Extensive experiments on two benchmark datasets demonstrate that MAG achieves stateof-the-art performance both quantitatively and qualitatively, producing highly realistic and diverse co-speech gestures.The code will be released to facilitate future research.
Dual-branch Graph Feature Learning for NLOS Imaging
Feb 27, 2025The domain of non-line-of-sight (NLOS) imaging is advancing rapidly, offering the capability to reveal occluded scenes that are not directly visible. However, contemporary NLOS systems face several significant challenges: (1) The computational and storage requirements are profound due to the inherent three-dimensional grid data structure, which restricts practical application. (2) The simultaneous reconstruction of albedo and depth information requires a delicate balance using hyperparameters in the loss function, rendering the concurrent reconstruction of texture and depth information difficult. This paper introduces the innovative methodology, \xnet, which integrates an albedo-focused reconstruction branch dedicated to albedo information recovery and a depth-focused reconstruction branch that extracts geometrical structure, to overcome these obstacles. The dual-branch framework segregates content delivery to the respective reconstructions, thereby enhancing the quality of the retrieved data. To our knowledge, we are the first to employ the GNN as a fundamental component to transform dense NLOS grid data into sparse structural features for efficient reconstruction. Comprehensive experiments demonstrate that our method attains the highest level of performance among existing methods across synthetic and real data. https://github.com/Nicholassu/DG-NLOS.
Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
Dec 16, 2024



Generative inbetweening aims to generate intermediate frame sequences by utilizing two key frames as input. Although remarkable progress has been made in video generation models, generative inbetweening still faces challenges in maintaining temporal stability due to the ambiguous interpolation path between two key frames. This issue becomes particularly severe when there is a large motion gap between input frames. In this paper, we propose a straightforward yet highly effective Frame-wise Conditions-driven Video Generation (FCVG) method that significantly enhances the temporal stability of interpolated video frames. Specifically, our FCVG provides an explicit condition for each frame, making it much easier to identify the interpolation path between two input frames and thus ensuring temporally stable production of visually plausible video frames. To achieve this, we suggest extracting matched lines from two input frames that can then be easily interpolated frame by frame, serving as frame-wise conditions seamlessly integrated into existing video generation models. In extensive evaluations covering diverse scenarios such as natural landscapes, complex human poses, camera movements and animations, existing methods often exhibit incoherent transitions across frames. In contrast, our FCVG demonstrates the capability to generate temporally stable videos using both linear and non-linear interpolation curves. Our project page and code are available at \url{https://fcvg-inbetween.github.io/}.
AniMer: Animal Pose and Shape Estimation Using Family Aware Transformer
Dec 01, 2024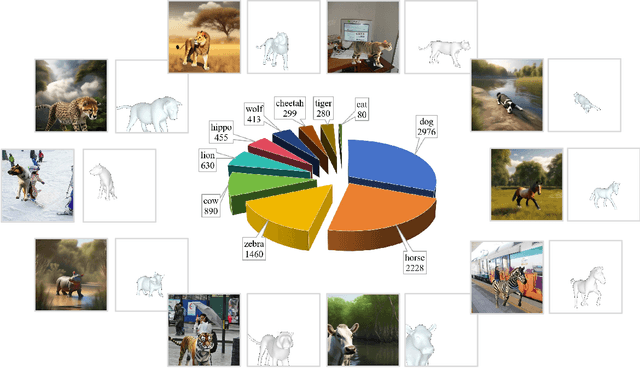
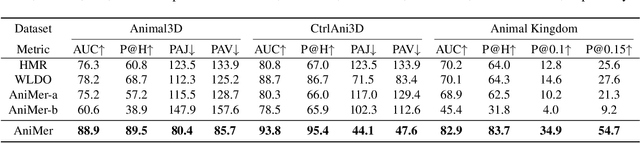
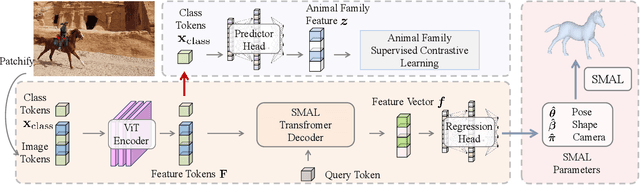

Quantitative analysis of animal behavior and biomechanics requires accurate animal pose and shape estimation across species, and is important for animal welfare and biological research. However, the small network capacity of previous methods and limited multi-species dataset leave this problem underexplored. To this end, this paper presents AniMer to estimate animal pose and shape using family aware Transformer, enhancing the reconstruction accuracy of diverse quadrupedal families. A key insight of AniMer is its integration of a high-capacity Transformer-based backbone and an animal family supervised contrastive learning scheme, unifying the discriminative understanding of various quadrupedal shapes within a single framework. For effective training, we aggregate most available open-sourced quadrupedal datasets, either with 3D or 2D labels. To improve the diversity of 3D labeled data, we introduce CtrlAni3D, a novel large-scale synthetic dataset created through a new diffusion-based conditional image generation pipeline. CtrlAni3D consists of about 10k images with pixel-aligned SMAL labels. In total, we obtain 41.3k annotated images for training and validation. Consequently, the combination of a family aware Transformer network and an expansive dataset enables AniMer to outperform existing methods not only on 3D datasets like Animal3D and CtrlAni3D, but also on out-of-distribution Animal Kingdom dataset. Ablation studies further demonstrate the effectiveness of our network design and CtrlAni3D in enhancing the performance of AniMer for in-the-wild applications. The project page of AniMer is https://luoxue-star.github.io/AniMer_project_page/.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
Thin-Plate Spline-based Interpolation for Animation Line Inbetweening
Aug 17, 2024



Animation line inbetweening is a crucial step in animation production aimed at enhancing animation fluidity by predicting intermediate line arts between two key frames. However, existing methods face challenges in effectively addressing sparse pixels and significant motion in line art key frames. In literature, Chamfer Distance (CD) is commonly adopted for evaluating inbetweening performance. Despite achieving favorable CD values, existing methods often generate interpolated frames with line disconnections, especially for scenarios involving large motion. Motivated by this observation, we propose a simple yet effective interpolation method for animation line inbetweening that adopts thin-plate spline-based transformation to estimate coarse motion more accurately by modeling the keypoint correspondence between two key frames, particularly for large motion scenarios. Building upon the coarse estimation, a motion refine module is employed to further enhance motion details before final frame interpolation using a simple UNet model. Furthermore, to more accurately assess the performance of animation line inbetweening, we refine the CD metric and introduce a novel metric termed Weighted Chamfer Distance, which demonstrates a higher consistency with visual perception quality. Additionally, we incorporate Earth Mover's Distance and conduct user study to provide a more comprehensive evaluation. Our method outperforms existing approaches by delivering high-quality interpolation results with enhanced fluidity. The code is available at \url{https://github.com/Tian-one/tps-inbetween}.