 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR Forcing: Towards Long-Horizon Robot Navigation World Model
May 29, 2026The diffusion based robot navigation world models are typically trained using parallel supervision, while autoregressive inference is employed during path planning. This results in a distribution shift between training and inference, which destabilizes the performance over long-horizon prediction. We propose AR Forcing, an autoregressive training strategy, which integrates the standard diffusion loss into the autoregressive training loop. At each step, the model uses its own predictions to update the context and optimize the single step noise prediction objective, thereby explicitly exposing the model to the inference state distribution during training. Our method does not require additional discriminators or distribution-matching losses, retains the original diffusion framework and sampler, and is easy to integrate. Experiments on multi-domain navigation datasets (RECON, SCAND, HuRoN, TartanDrive) show that compared with strong baselines, AR Forcing improved the consistency of generated images during long-horizon navigation and the accuracy of predicted trajectories, enhancing robustness of the model in complex known and unknown environments. We will release the code soon.
GaussianDream: A Feed-Forward 3D Gaussian World Model for Robotic Manipulation
May 20, 2026Vision-language-action (VLA) policies have advanced language-conditioned robotic manipulation by transferring semantic priors from pretrained vision-language models to action generation. Yet, standard action-imitation training often provides limited explicit supervision for 3D geometry, dense visual structure, and short-horizon environment evolution, which are critical for physically precise manipulation. We introduce \textbf{GaussianDream}, a feed-forward 3D Gaussian world-model plug-in that turns robot trajectories into structured spatial-temporal supervision. The key idea is to couple current Gaussian reconstruction with horizon-conditioned future Gaussian prediction during training, forcing a compact spatio-temporal prefix to be decodable into renderable 3D Gaussian states. This enables dense RGB rendering, depth, and pseudo 3D scene-flow supervision without requiring test-time Gaussian decoding. At inference, GaussianDream discards all auxiliary decoding heads and retains only the learned prefix to condition action generation, avoiding rendering, video rollout, or additional planning during closed-loop control. Experiments on LIBERO, RoboCasa Human-50, and real-robot tasks demonstrate strong and highly competitive performance, achieving \textbf{98.4\%} average success on LIBERO, \textbf{52.6\%} on RoboCasa Human-50, and \textbf{50.0\%} in real-world evaluation.
CounterScene: Counterfactual Causal Reasoning in Generative World Models for Safety-Critical Closed-Loop Evaluation
Mar 22, 2026Generating safety-critical driving scenarios requires understanding why dangerous interactions arise, rather than merely forcing collisions. However, existing methods rely on heuristic adversarial agent selection and unstructured perturbations, lacking explicit modeling of interaction dependencies and thus exhibiting a realism--adversarial trade-off. We present CounterScene, a framework that endows closed-loop generative BEV world models with structured counterfactual reasoning for safety-critical scenario generation. Given a safe scene, CounterScene asks: what if the causally critical agent had behaved differently? To answer this, we introduce causal adversarial agent identification to identify the critical agent and classify conflict types, and develop a conflict-aware interactive world model in which a causal interaction graph is used to explicitly model dynamic inter-agent dependencies. Building on this structure, stage-adaptive counterfactual guidance performs minimal interventions on the identified agent, removing its spatial and temporal safety margins while allowing risk to emerge through natural interaction propagation. Extensive experiments on nuScenes demonstrate that CounterScene achieves the strongest adversarial effectiveness while maintaining superior trajectory realism across all horizons, improving long-horizon collision rate from 12.3% to 22.7% over the strongest baseline with better realism (ADE 1.88 vs.2.09). Notably, this advantage further widens over longer rollouts, and CounterScene generalizes zero-shot to nuPlan with state-of-the-art realism.
ReconDrive: Fast Feed-Forward 4D Gaussian Splatting for Autonomous Driving Scene Reconstruction
Mar 08, 2026High-fidelity visual reconstruction and novel-view synthesis are essential for realistic closed-loop evaluation in autonomous driving. While 4D Gaussian Splatting (4DGS) offers a promising balance of accuracy and efficiency, existing per-scene optimization methods require costly iterative refinement, rendering them unscalable for extensive urban environments. Conversely, current feed-forward approaches often suffer from degraded photometric quality. To address these limitations, we propose ReconDrive, a feed-forward framework that leverages and extends the 3D foundation model VGGT for rapid, high-fidelity 4DGS generation. Our architecture introduces two core adaptations to tailor the foundation model to dynamic driving scenes: (1) Hybrid Gaussian Prediction Heads, which decouple the regression of spatial coordinates and appearance attributes to overcome the photometric deficiencies inherent in generalized foundation features; and (2) a Static-Dynamic 4D Composition strategy that explicitly captures temporal motion via velocity modeling to represent complex dynamic environments. Benchmarked on nuScenes, ReconDrive significantly outperforms existing feed-forward baselines in reconstruction, novel-view synthesis, and 3D perception. It achieves performance competitive with per-scene optimization while being orders of magnitude faster, providing a scalable and practical solution for realistic driving simulation.
UniMM-V2X: MoE-Enhanced Multi-Level Fusion for End-to-End Cooperative Autonomous Driving
Nov 12, 2025Autonomous driving holds transformative potential but remains fundamentally constrained by the limited perception and isolated decision-making with standalone intelligence. While recent multi-agent approaches introduce cooperation, they often focus merely on perception-level tasks, overlooking the alignment with downstream planning and control, or fall short in leveraging the full capacity of the recent emerging end-to-end autonomous driving. In this paper, we present UniMM-V2X, a novel end-to-end multi-agent framework that enables hierarchical cooperation across perception, prediction, and planning. At the core of our framework is a multi-level fusion strategy that unifies perception and prediction cooperation, allowing agents to share queries and reason cooperatively for consistent and safe decision-making. To adapt to diverse downstream tasks and further enhance the quality of multi-level fusion, we incorporate a Mixture-of-Experts (MoE) architecture to dynamically enhance the BEV representations. We further extend MoE into the decoder to better capture diverse motion patterns. Extensive experiments on the DAIR-V2X dataset demonstrate our approach achieves state-of-the-art (SOTA) performance with a 39.7% improvement in perception accuracy, a 7.2% reduction in prediction error, and a 33.2% improvement in planning performance compared with UniV2X, showcasing the strength of our MoE-enhanced multi-level cooperative paradigm.
Griffin: Aerial-Ground Cooperative Detection and Tracking Dataset and Benchmark
Mar 10, 2025



Despite significant advancements, autonomous driving systems continue to struggle with occluded objects and long-range detection due to the inherent limitations of single-perspective sensing. Aerial-ground cooperation offers a promising solution by integrating UAVs' aerial views with ground vehicles' local observations. However, progress in this emerging field has been hindered by the absence of public datasets and standardized evaluation benchmarks. To address this gap, this paper presents a comprehensive solution for aerial-ground cooperative 3D perception through three key contributions: (1) Griffin, a large-scale multi-modal dataset featuring over 200 dynamic scenes (30k+ frames) with varied UAV altitudes (20-60m), diverse weather conditions, and occlusion-aware 3D annotations, enhanced by CARLA-AirSim co-simulation for realistic UAV dynamics; (2) A unified benchmarking framework for aerial-ground cooperative detection and tracking tasks, including protocols for evaluating communication efficiency, latency tolerance, and altitude adaptability; (3) AGILE, an instance-level intermediate fusion baseline that dynamically aligns cross-view features through query-based interaction, achieving an advantageous balance between communication overhead and perception accuracy. Extensive experiments prove the effectiveness of aerial-ground cooperative perception and demonstrate the direction of further research. The dataset and codes are available at https://github.com/wang-jh18-SVM/Griffin.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024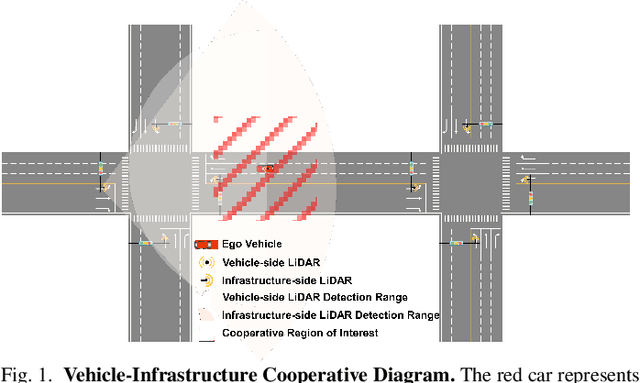
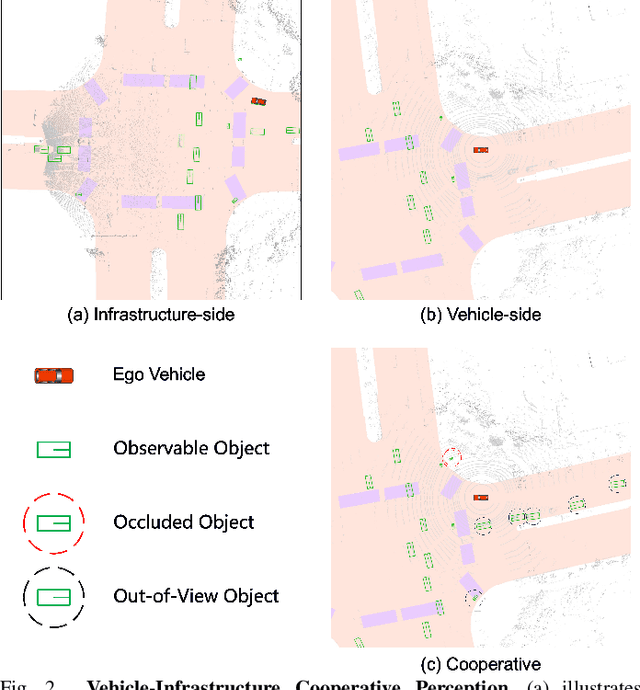
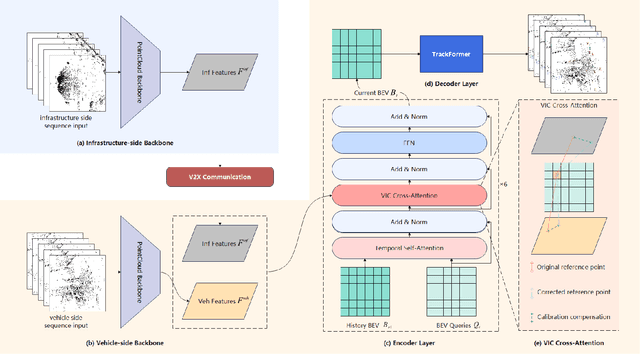
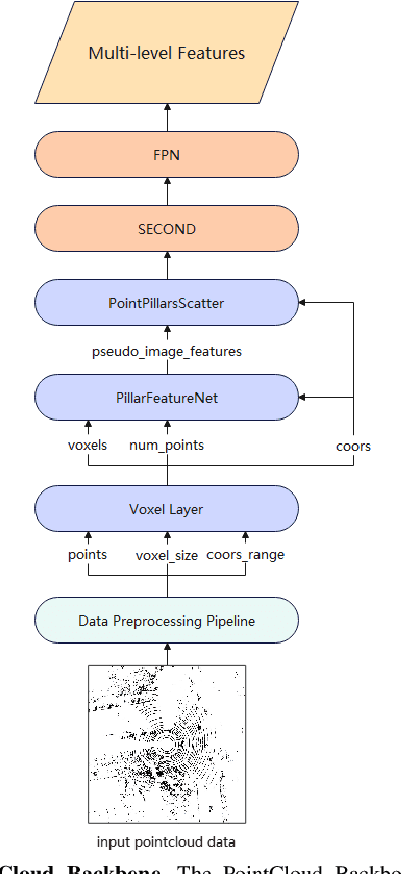
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
MEDCO: Medical Education Copilots Based on A Multi-Agent Framework
Aug 22, 2024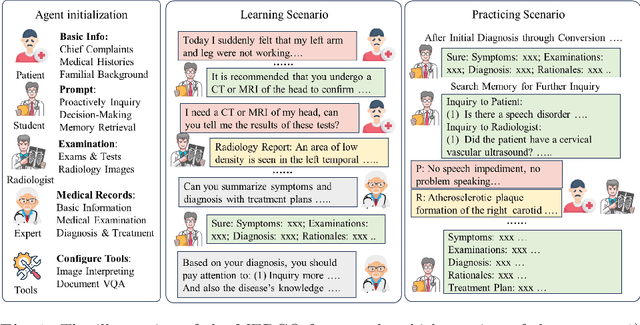
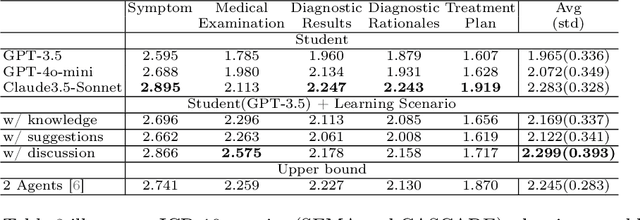

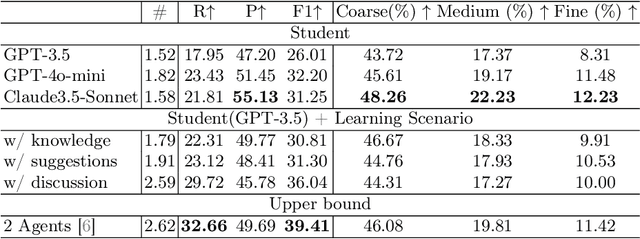
Large language models (LLMs) have had a significant impact on diverse research domains, including medicine and healthcare. However, the potential of LLMs as copilots in medical education remains underexplored. Current AI-assisted educational tools are limited by their solitary learning approach and inability to simulate the multi-disciplinary and interactive nature of actual medical training. To address these limitations, we propose MEDCO (Medical EDucation COpilots), a novel multi-agent-based copilot system specially developed to emulate real-world medical training environments. MEDCO incorporates three primary agents: an agentic patient, an expert doctor, and a radiologist, facilitating a multi-modal and interactive learning environment. Our framework emphasizes the learning of proficient question-asking skills, multi-disciplinary collaboration, and peer discussions between students. Our experiments show that simulated virtual students who underwent training with MEDCO not only achieved substantial performance enhancements comparable to those of advanced models, but also demonstrated human-like learning behaviors and improvements, coupled with an increase in the number of learning samples. This work contributes to medical education by introducing a copilot that implements an interactive and collaborative learning approach. It also provides valuable insights into the effectiveness of AI-integrated training paradigms.
Leveraging Temporal Contexts to Enhance Vehicle-Infrastructure Cooperative Perception
Aug 20, 2024Infrastructure sensors installed at elevated positions offer a broader perception range and encounter fewer occlusions. Integrating both infrastructure and ego-vehicle data through V2X communication, known as vehicle-infrastructure cooperation, has shown considerable advantages in enhancing perception capabilities and addressing corner cases encountered in single-vehicle autonomous driving. However, cooperative perception still faces numerous challenges, including limited communication bandwidth and practical communication interruptions. In this paper, we propose CTCE, a novel framework for cooperative 3D object detection. This framework transmits queries with temporal contexts enhancement, effectively balancing transmission efficiency and performance to accommodate real-world communication conditions. Additionally, we propose a temporal-guided fusion module to further improve performance. The roadside temporal enhancement and vehicle-side spatial-temporal fusion together constitute a multi-level temporal contexts integration mechanism, fully leveraging temporal information to enhance performance. Furthermore, a motion-aware reconstruction module is introduced to recover lost roadside queries due to communication interruptions. Experimental results on V2X-Seq and V2X-Sim datasets demonstrate that CTCE outperforms the baseline QUEST, achieving improvements of 3.8% and 1.3% in mAP, respectively. Experiments under communication interruption conditions validate CTCE's robustness to communication interruptions.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024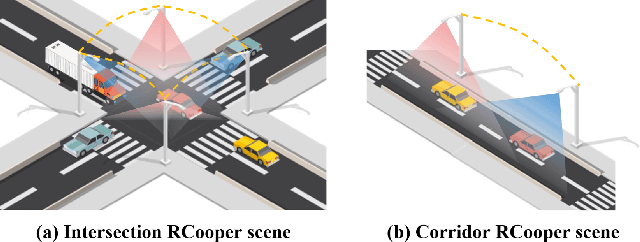
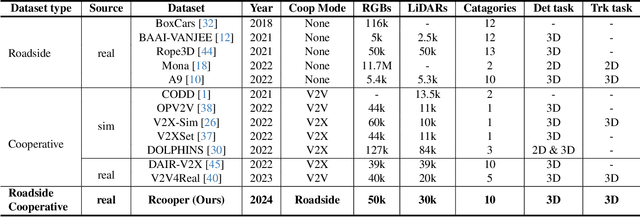
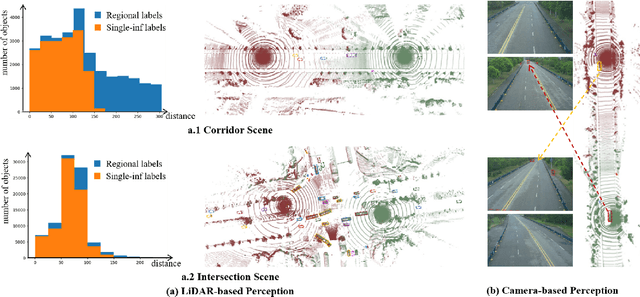

The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.