 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquivariant Spatio-Temporal Attentive Graph Networks to Simulate Physical Dynamics
May 21, 2024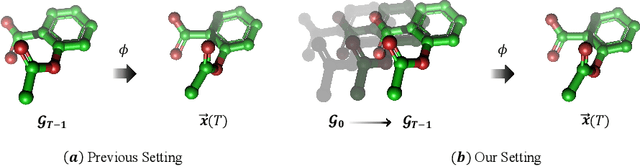
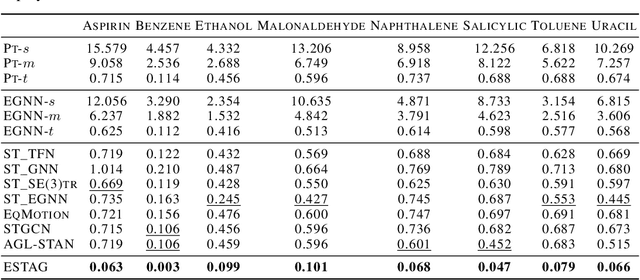
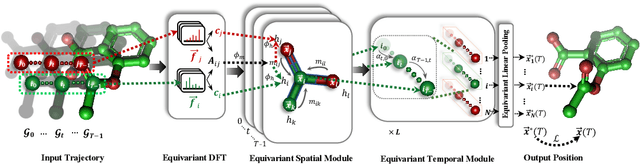
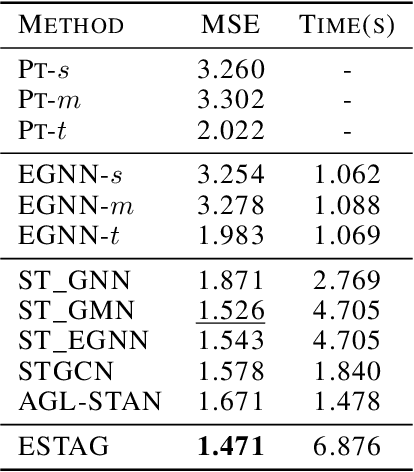
Learning to represent and simulate the dynamics of physical systems is a crucial yet challenging task. Existing equivariant Graph Neural Network (GNN) based methods have encapsulated the symmetry of physics, \emph{e.g.}, translations, rotations, etc, leading to better generalization ability. Nevertheless, their frame-to-frame formulation of the task overlooks the non-Markov property mainly incurred by unobserved dynamics in the environment. In this paper, we reformulate dynamics simulation as a spatio-temporal prediction task, by employing the trajectory in the past period to recover the Non-Markovian interactions. We propose Equivariant Spatio-Temporal Attentive Graph Networks (ESTAG), an equivariant version of spatio-temporal GNNs, to fulfill our purpose. At its core, we design a novel Equivariant Discrete Fourier Transform (EDFT) to extract periodic patterns from the history frames, and then construct an Equivariant Spatial Module (ESM) to accomplish spatial message passing, and an Equivariant Temporal Module (ETM) with the forward attention and equivariant pooling mechanisms to aggregate temporal message. We evaluate our model on three real datasets corresponding to the molecular-, protein- and macro-level. Experimental results verify the effectiveness of ESTAG compared to typical spatio-temporal GNNs and equivariant GNNs.
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
Mar 31, 2024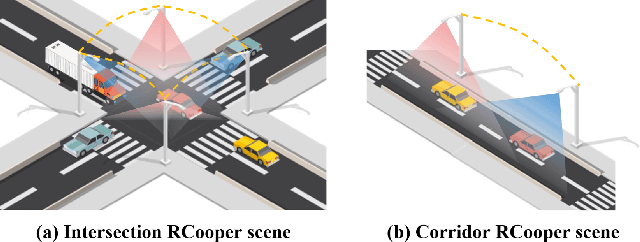
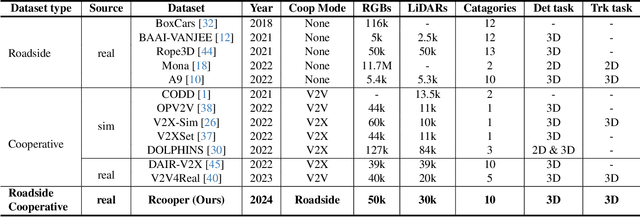
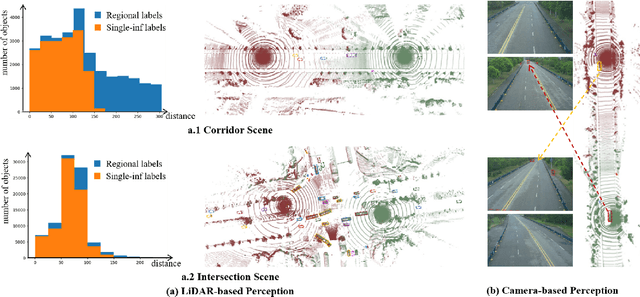

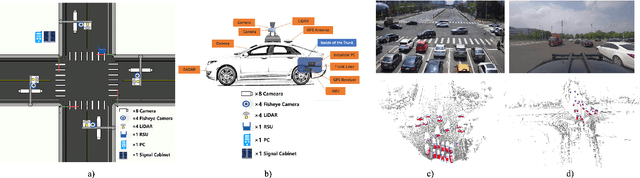
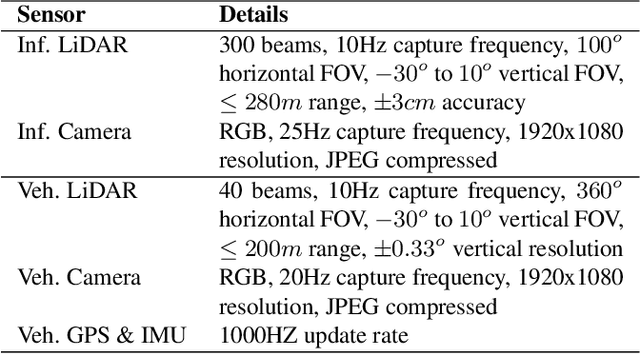
The value of roadside perception, which could extend the boundaries of autonomous driving and traffic management, has gradually become more prominent and acknowledged in recent years. However, existing roadside perception approaches only focus on the single-infrastructure sensor system, which cannot realize a comprehensive understanding of a traffic area because of the limited sensing range and blind spots. Orienting high-quality roadside perception, we need Roadside Cooperative Perception (RCooper) to achieve practical area-coverage roadside perception for restricted traffic areas. Rcooper has its own domain-specific challenges, but further exploration is hindered due to the lack of datasets. We hence release the first real-world, large-scale RCooper dataset to bloom the research on practical roadside cooperative perception, including detection and tracking. The manually annotated dataset comprises 50k images and 30k point clouds, including two representative traffic scenes (i.e., intersection and corridor). The constructed benchmarks prove the effectiveness of roadside cooperation perception and demonstrate the direction of further research. Codes and dataset can be accessed at: https://github.com/AIR-THU/DAIR-RCooper.
QUEST: Query Stream for Vehicle-Infrastructure Cooperative Perception
Aug 03, 2023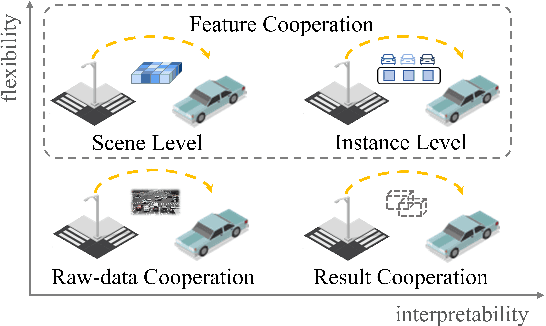
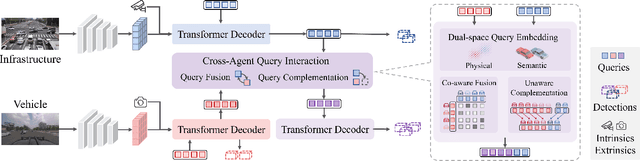
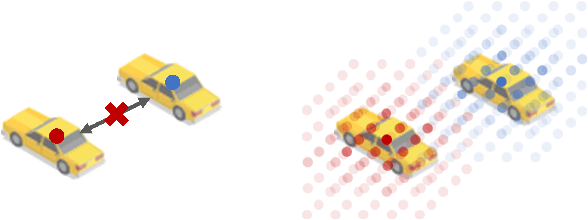
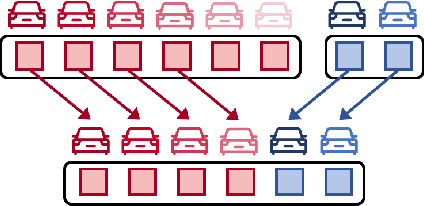
Cooperative perception can effectively enhance individual perception performance by providing additional viewpoint and expanding the sensing field. Existing cooperation paradigms are either interpretable (result cooperation) or flexible (feature cooperation). In this paper, we propose the concept of query cooperation to enable interpretable instance-level flexible feature interaction. To specifically explain the concept, we propose a cooperative perception framework, termed QUEST, which let query stream flow among agents. The cross-agent queries are interacted via fusion for co-aware instances and complementation for individual unaware instances. Taking camera-based vehicle-infrastructure perception as a typical practical application scene, the experimental results on the real-world dataset, DAIR-V2X-Seq, demonstrate the effectiveness of QUEST and further reveal the advantage of the query cooperation paradigm on transmission flexibility and robustness to packet dropout. We hope our work can further facilitate the cross-agent representation interaction for better cooperative perception in practice.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023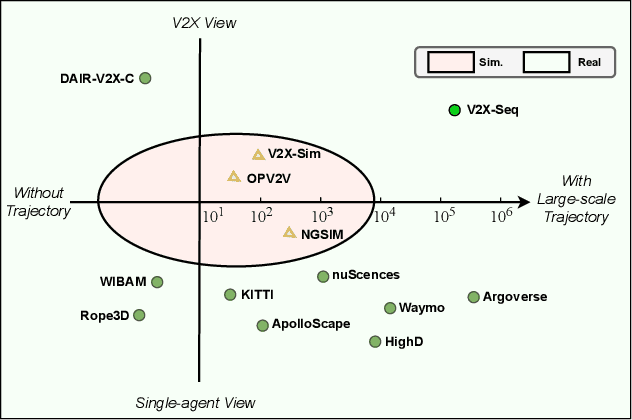
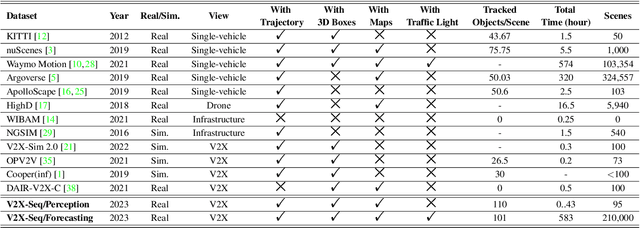
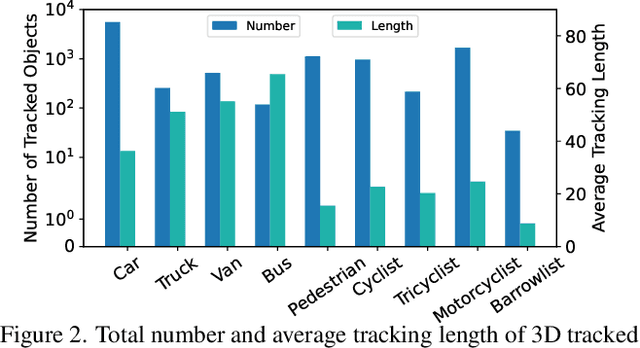
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
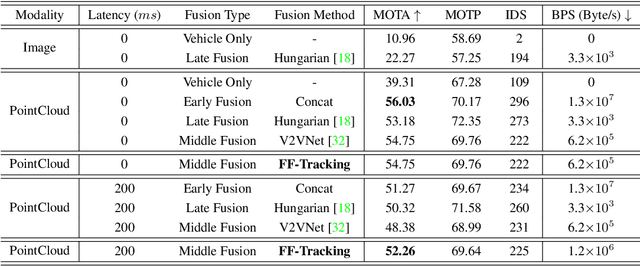
Vehicle-Infrastructure Cooperative 3D Object Detection via Feature Flow Prediction
Mar 19, 2023



Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, temporal asynchrony and limited wireless communication in traffic environments can lead to fusion misalignment and impact detection performance. This paper proposes Feature Flow Net (FFNet), a novel cooperative detection framework that uses a feature flow prediction module to address these issues in vehicle-infrastructure cooperative 3D object detection. Rather than transmitting feature maps extracted from still-images, FFNet transmits feature flow, which leverages the temporal coherence of sequential infrastructure frames to predict future features and compensate for asynchrony. Additionally, we introduce a self-supervised approach to enable FFNet to generate feature flow with feature prediction ability. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while requiring no more than 1/10 transmission cost of raw data on the DAIR-V2X dataset when temporal asynchrony exceeds 200$ms$. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
Feb 27, 2023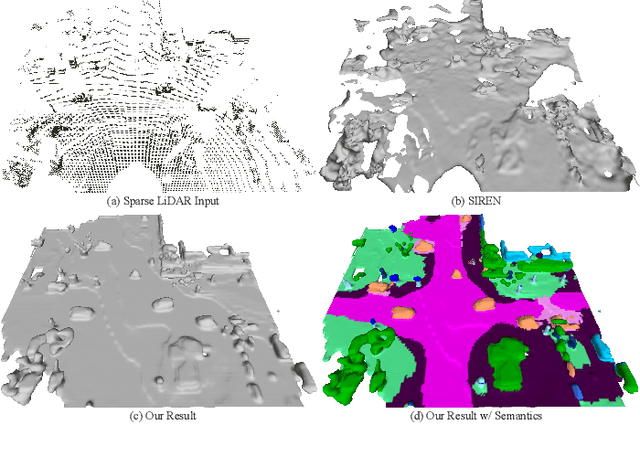
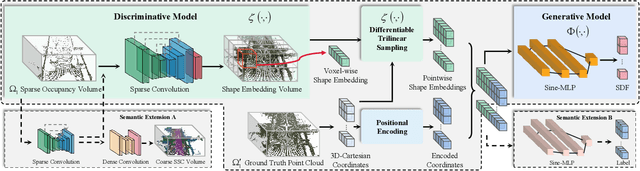
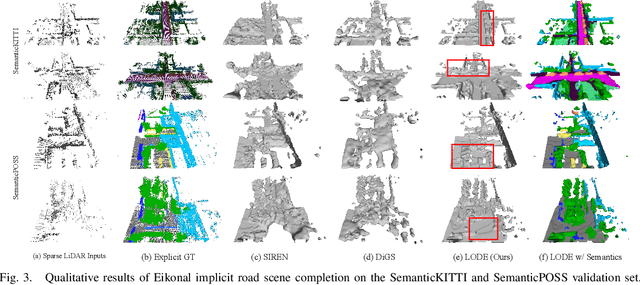
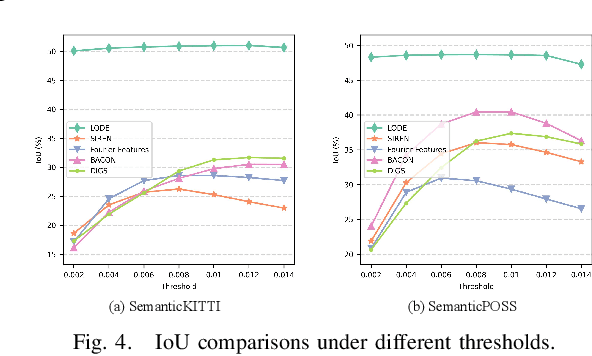
Scene completion refers to obtaining dense scene representation from an incomplete perception of complex 3D scenes. This helps robots detect multi-scale obstacles and analyse object occlusions in scenarios such as autonomous driving. Recent advances show that implicit representation learning can be leveraged for continuous scene completion and achieved through physical constraints like Eikonal equations. However, former Eikonal completion methods only demonstrate results on watertight meshes at a scale of tens of meshes. None of them are successfully done for non-watertight LiDAR point clouds of open large scenes at a scale of thousands of scenes. In this paper, we propose a novel Eikonal formulation that conditions the implicit representation on localized shape priors which function as dense boundary value constraints, and demonstrate it works on SemanticKITTI and SemanticPOSS. It can also be extended to semantic Eikonal scene completion with only small modifications to the network architecture. With extensive quantitative and qualitative results, we demonstrate the benefits and drawbacks of existing Eikonal methods, which naturally leads to the new locally conditioned formulation. Notably, we improve IoU from 31.7% to 51.2% on SemanticKITTI and from 40.5% to 48.7% on SemanticPOSS. We extensively ablate our methods and demonstrate that the proposed formulation is robust to a wide spectrum of implementation hyper-parameters. Codes and models are publicly available at https://github.com/AIR-DISCOVER/LODE.
A High Fidelity Simulation Framework for Potential Safety Benefits Estimation of Cooperative Pedestrian Perception
Oct 18, 2022
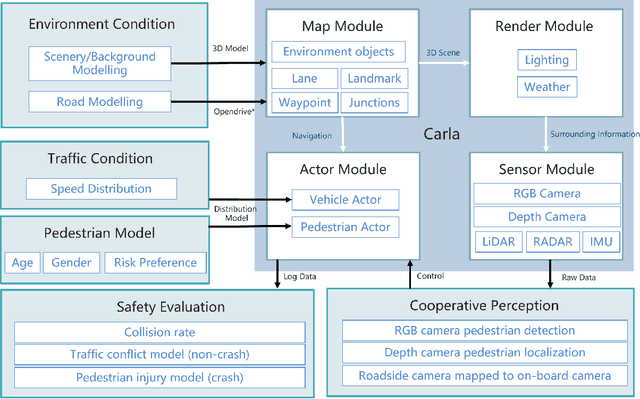
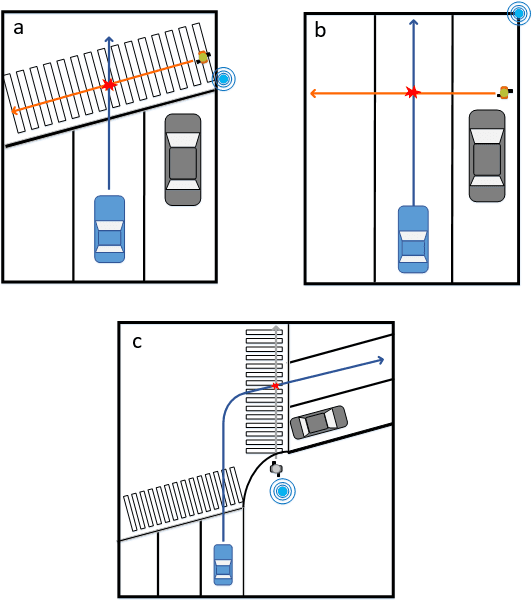
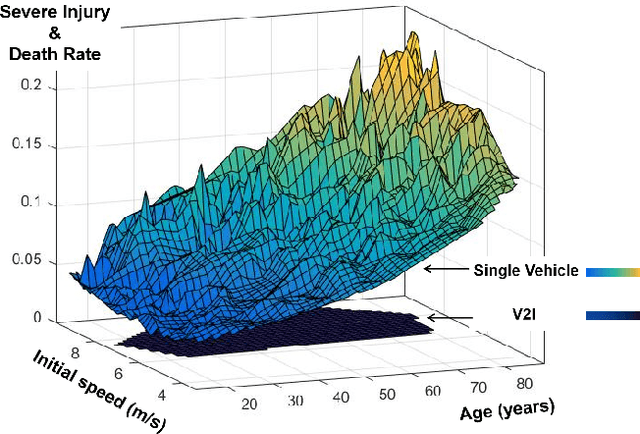
This paper proposes a high-fidelity simulation framework that can estimate the potential safety benefits of vehicle-to-infrastructure (V2I) pedestrian safety strategies. This simulator can support cooperative perception algorithms in the loop by simulating the environmental conditions, traffic conditions, and pedestrian characteristics at the same time. Besides, the benefit estimation model applied in our framework can systematically quantify both the risk conflict (non-crash condition) and the severity of the pedestrian's injuries (crash condition). An experiment was conducted in this paper that built a digital twin of a crowded urban intersection in China. The result shows that our framework is efficient for safety benefit estimation of V2I pedestrian safety strategies.
DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
Apr 12, 2022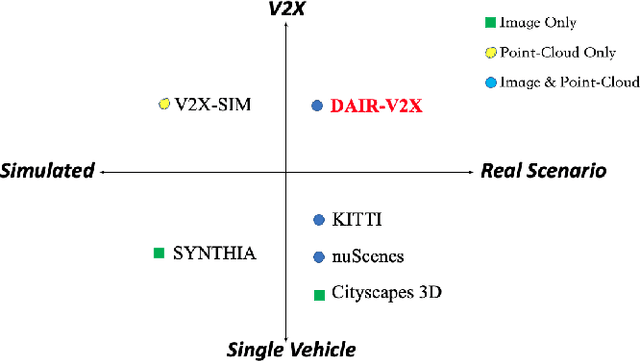
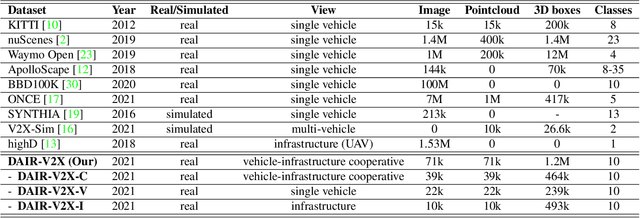
Autonomous driving faces great safety challenges for a lack of global perspective and the limitation of long-range perception capabilities. It has been widely agreed that vehicle-infrastructure cooperation is required to achieve Level 5 autonomy. However, there is still NO dataset from real scenarios available for computer vision researchers to work on vehicle-infrastructure cooperation-related problems. To accelerate computer vision research and innovation for Vehicle-Infrastructure Cooperative Autonomous Driving (VICAD), we release DAIR-V2X Dataset, which is the first large-scale, multi-modality, multi-view dataset from real scenarios for VICAD. DAIR-V2X comprises 71254 LiDAR frames and 71254 Camera frames, and all frames are captured from real scenes with 3D annotations. The Vehicle-Infrastructure Cooperative 3D Object Detection problem (VIC3D) is introduced, formulating the problem of collaboratively locating and identifying 3D objects using sensory inputs from both vehicle and infrastructure. In addition to solving traditional 3D object detection problems, the solution of VIC3D needs to consider the temporal asynchrony problem between vehicle and infrastructure sensors and the data transmission cost between them. Furthermore, we propose Time Compensation Late Fusion (TCLF), a late fusion framework for the VIC3D task as a benchmark based on DAIR-V2X. Find data, code, and more up-to-date information at https://thudair.baai.ac.cn/index and https://github.com/AIR-THU/DAIR-V2X.