 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR
Paper and Code
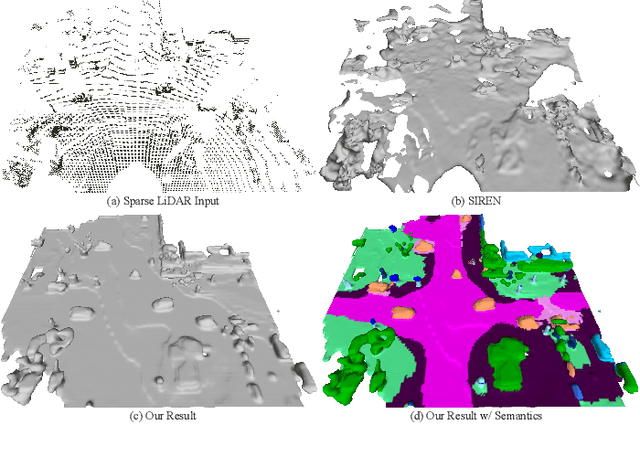
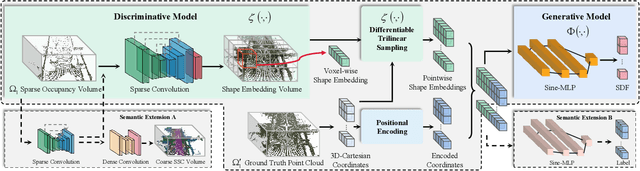
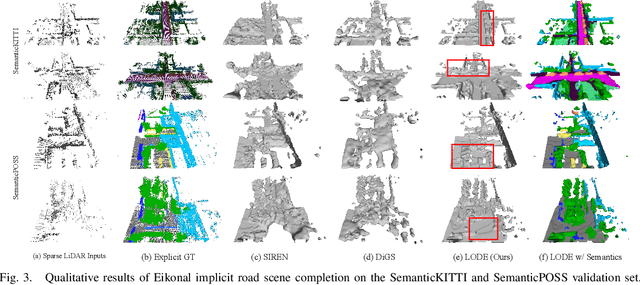
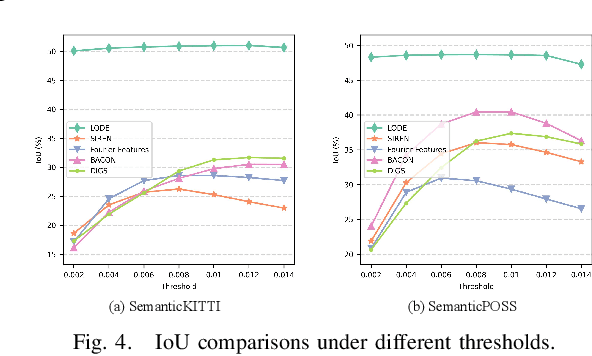
Scene completion refers to obtaining dense scene representation from an incomplete perception of complex 3D scenes. This helps robots detect multi-scale obstacles and analyse object occlusions in scenarios such as autonomous driving. Recent advances show that implicit representation learning can be leveraged for continuous scene completion and achieved through physical constraints like Eikonal equations. However, former Eikonal completion methods only demonstrate results on watertight meshes at a scale of tens of meshes. None of them are successfully done for non-watertight LiDAR point clouds of open large scenes at a scale of thousands of scenes. In this paper, we propose a novel Eikonal formulation that conditions the implicit representation on localized shape priors which function as dense boundary value constraints, and demonstrate it works on SemanticKITTI and SemanticPOSS. It can also be extended to semantic Eikonal scene completion with only small modifications to the network architecture. With extensive quantitative and qualitative results, we demonstrate the benefits and drawbacks of existing Eikonal methods, which naturally leads to the new locally conditioned formulation. Notably, we improve IoU from 31.7% to 51.2% on SemanticKITTI and from 40.5% to 48.7% on SemanticPOSS. We extensively ablate our methods and demonstrate that the proposed formulation is robust to a wide spectrum of implementation hyper-parameters. Codes and models are publicly available at https://github.com/AIR-DISCOVER/LODE.