 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIReCa: Intrinsic Reward-enhanced Context-aware Reinforcement Learning for Human-AI Coordination
Aug 15, 2024



In human-AI coordination scenarios, human agents usually exhibit asymmetric behaviors that are significantly sparse and unpredictable compared to those of AI agents. These characteristics introduce two primary challenges to human-AI coordination: the effectiveness of obtaining sparse rewards and the efficiency of training the AI agents. To tackle these challenges, we propose an Intrinsic Reward-enhanced Context-aware (IReCa) reinforcement learning (RL) algorithm, which leverages intrinsic rewards to facilitate the acquisition of sparse rewards and utilizes environmental context to enhance training efficiency. Our IReCa RL algorithm introduces three unique features: (i) it encourages the exploration of sparse rewards by incorporating intrinsic rewards that supplement traditional extrinsic rewards from the environment; (ii) it improves the acquisition of sparse rewards by prioritizing the corresponding sparse state-action pairs; and (iii) it enhances the training efficiency by optimizing the exploration and exploitation through innovative context-aware weights of extrinsic and intrinsic rewards. Extensive simulations executed in the Overcooked layouts demonstrate that our IReCa RL algorithm can increase the accumulated rewards by approximately 20% and reduce the epochs required for convergence by approximately 67% compared to state-of-the-art baselines.
Explore the LiDAR-Camera Dynamic Adjustment Fusion for 3D Object Detection
Jul 22, 2024



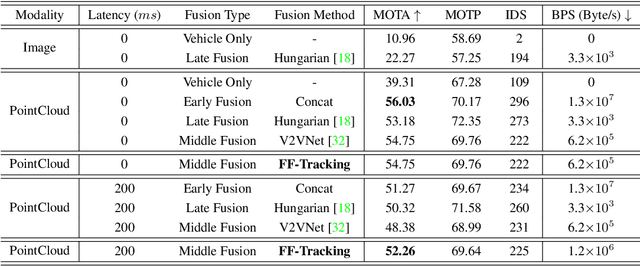
Camera and LiDAR serve as informative sensors for accurate and robust autonomous driving systems. However, these sensors often exhibit heterogeneous natures, resulting in distributional modality gaps that present significant challenges for fusion. To address this, a robust fusion technique is crucial, particularly for enhancing 3D object detection. In this paper, we introduce a dynamic adjustment technology aimed at aligning modal distributions and learning effective modality representations to enhance the fusion process. Specifically, we propose a triphase domain aligning module. This module adjusts the feature distributions from both the camera and LiDAR, bringing them closer to the ground truth domain and minimizing differences. Additionally, we explore improved representation acquisition methods for dynamic fusion, which includes modal interaction and specialty enhancement. Finally, an adaptive learning technique that merges the semantics and geometry information for dynamical instance optimization. Extensive experiments in the nuScenes dataset present competitive performance with state-of-the-art approaches. Our code will be released in the future.
Gaussian Process Model with Tensorial Inputs and Its Application to the Design of 3D Printed Antennas
Jul 19, 2024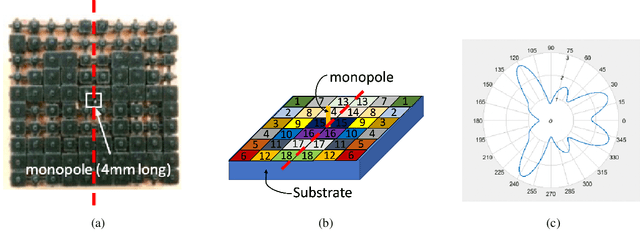

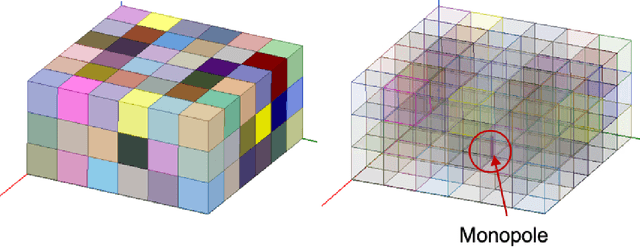

In simulation-based engineering design with time-consuming simulators, Gaussian process (GP) models are widely used as fast emulators to speed up the design optimization process. In its most commonly used form, the input of GP is a simple list of design parameters. With rapid development of additive manufacturing (also known as 3D printing), design inputs with 2D/3D spatial information become prevalent in some applications, for example, neighboring relations between pixels/voxels and material distributions in heterogeneous materials. Such spatial information, vital to 3D printed designs, is hard to incorporate into existing GP models with common kernels such as squared exponential or Mat\'ern. In this work, we propose to embed a generalized distance measure into a GP kernel, offering a novel and convenient technique to incorporate spatial information from freeform 3D printed designs into the GP framework. The proposed method allows complex design problems for 3D printed objects to take advantage of a plethora of tools available from the GP surrogate-based simulation optimization such as designed experiments and GP-based optimizations including Bayesian optimization. We investigate the properties of the proposed method and illustrate its performance by several numerical examples of 3D printed antennas. The dataset is publicly available at: https://github.com/xichennn/GP_dataset.
ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
Mar 15, 2024



Although Vision Transformer (ViT) has achieved significant success in computer vision, it does not perform well in dense prediction tasks due to the lack of inner-patch information interaction and the limited diversity of feature scale. Most existing studies are devoted to designing vision-specific transformers to solve the above problems, which introduce additional pre-training costs. Therefore, we present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks. (3) We evaluate the performance of ViT-CoMer across various dense prediction tasks, different frameworks, and multiple advanced pre-training. Notably, our ViT-CoMer-L achieves 64.3% AP on COCO val2017 without extra training data, and 62.1% mIoU on ADE20K val, both of which are comparable to state-of-the-art methods. We hope ViT-CoMer can serve as a new backbone for dense prediction tasks to facilitate future research. The code will be released at https://github.com/Traffic-X/ViT-CoMer.
WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Feb 22, 2024Weakly supervised visual recognition using inexact supervision is a critical yet challenging learning problem. It significantly reduces human labeling costs and traditionally relies on multi-instance learning and pseudo-labeling. This paper introduces WeakSAM and solves the weakly-supervised object detection (WSOD) and segmentation by utilizing the pre-learned world knowledge contained in a vision foundation model, i.e., the Segment Anything Model (SAM). WeakSAM addresses two critical limitations in traditional WSOD retraining, i.e., pseudo ground truth (PGT) incompleteness and noisy PGT instances, through adaptive PGT generation and Region of Interest (RoI) drop regularization. It also addresses the SAM's problems of requiring prompts and category unawareness for automatic object detection and segmentation. Our results indicate that WeakSAM significantly surpasses previous state-of-the-art methods in WSOD and WSIS benchmarks with large margins, i.e. average improvements of 7.4% and 8.5%, respectively. The code is available at \url{https://github.com/hustvl/WeakSAM}.
Graph Neural Network-Based Bandwidth Allocation for Secure Wireless Communications
Dec 13, 2023This paper designs a graph neural network (GNN) to improve bandwidth allocations for multiple legitimate wireless users transmitting to a base station in the presence of an eavesdropper. To improve the privacy and prevent eavesdropping attacks, we propose a user scheduling algorithm to schedule users satisfying an instantaneous minimum secrecy rate constraint. Based on this, we optimize the bandwidth allocations with three algorithms namely iterative search (IvS), GNN-based supervised learning (GNN-SL), and GNN-based unsupervised learning (GNN-USL). We present a computational complexity analysis which shows that GNN-SL and GNN-USL can be more efficient compared to IvS which is limited by the bandwidth block size. Numerical simulation results highlight that our proposed GNN-based resource allocations can achieve a comparable sum secrecy rate compared to IvS with significantly lower computational complexity. Furthermore, we observe that the GNN approach is more robust to uncertainties in the eavesdropper's channel state information, especially compared with the best channel allocation scheme.
Secure Deep Reinforcement Learning for Dynamic Resource Allocation in Wireless MEC Networks
Dec 13, 2023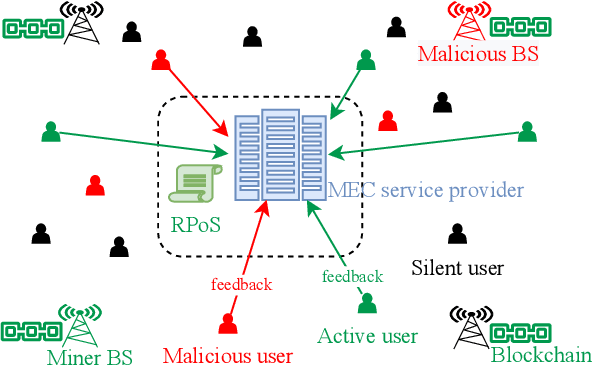
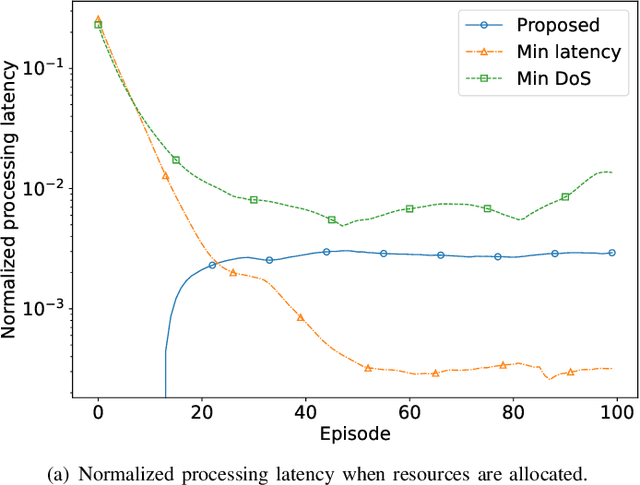
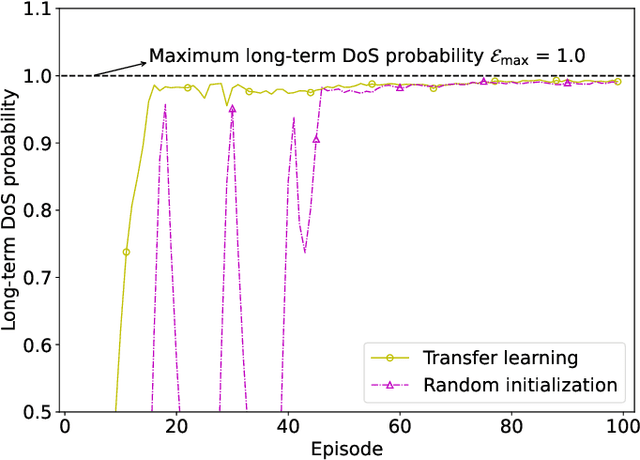
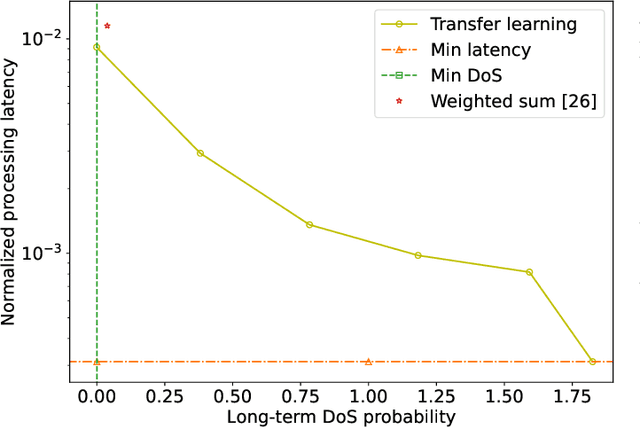
This paper proposes a blockchain-secured deep reinforcement learning (BC-DRL) optimization framework for {data management and} resource allocation in decentralized {wireless mobile edge computing (MEC)} networks. In our framework, {we design a low-latency reputation-based proof-of-stake (RPoS) consensus protocol to select highly reliable blockchain-enabled BSs to securely store MEC user requests and prevent data tampering attacks.} {We formulate the MEC resource allocation optimization as a constrained Markov decision process that balances minimum processing latency and denial-of-service (DoS) probability}. {We use the MEC aggregated features as the DRL input to significantly reduce the high-dimensionality input of the remaining service processing time for individual MEC requests. Our designed constrained DRL effectively attains the optimal resource allocations that are adapted to the dynamic DoS requirements. We provide extensive simulation results and analysis to} validate that our BC-DRL framework achieves higher security, reliability, and resource utilization efficiency than benchmark blockchain consensus protocols and {MEC} resource allocation algorithms.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023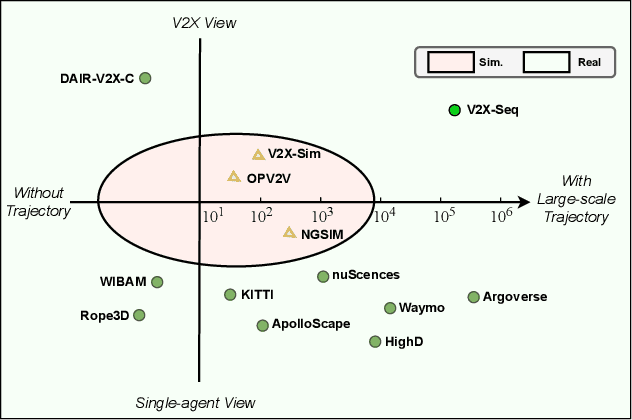
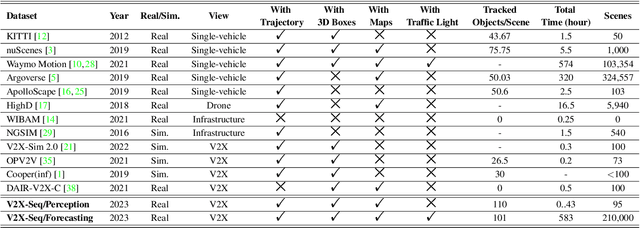
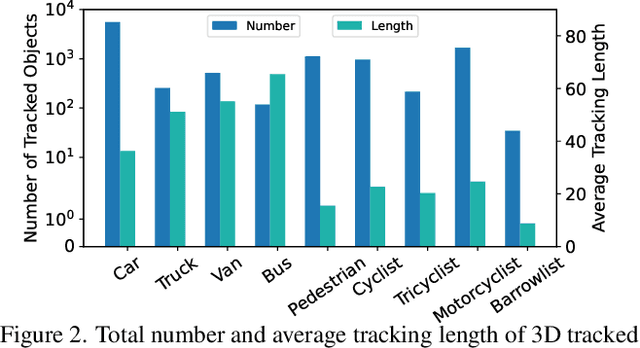
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
Simple Recurrent Neural Networks is all we need for clinical events predictions using EHR data
Oct 03, 2021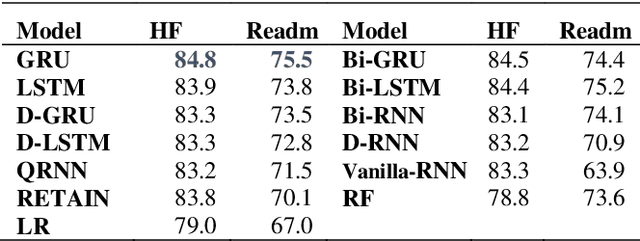
Recently, there is great interest to investigate the application of deep learning models for the prediction of clinical events using electronic health records (EHR) data. In EHR data, a patient's history is often represented as a sequence of visits, and each visit contains multiple events. As a result, deep learning models developed for sequence modeling, like recurrent neural networks (RNNs) are common architecture for EHR-based clinical events predictive models. While a large variety of RNN models were proposed in the literature, it is unclear if complex architecture innovations will offer superior predictive performance. In order to move this field forward, a rigorous evaluation of various methods is needed. In this study, we conducted a thorough benchmark of RNN architectures in modeling EHR data. We used two prediction tasks: the risk for developing heart failure and the risk of early readmission for inpatient hospitalization. We found that simple gated RNN models, including GRUs and LSTMs, often offer competitive results when properly tuned with Bayesian Optimization, which is in line with similar to findings in the natural language processing (NLP) domain. For reproducibility, Our codebase is shared at https://github.com/ZhiGroup/pytorch_ehr.