 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSat2RealCity: Geometry-Aware and Appearance-Controllable 3D Urban Generation from Satellite Imagery
Nov 14, 2025Recent advances in generative modeling have substantially enhanced 3D urban generation, enabling applications in digital twins, virtual cities, and large-scale simulations. However, existing methods face two key challenges: (1) the need for large-scale 3D city assets for supervised training, which are difficult and costly to obtain, and (2) reliance on semantic or height maps, which are used exclusively for generating buildings in virtual worlds and lack connection to real-world appearance, limiting the realism and generalizability of generated cities. To address these limitations, we propose Sat2RealCity, a geometry-aware and appearance-controllable framework for 3D urban generation from real-world satellite imagery. Unlike previous city-level generation methods, Sat2RealCity builds generation upon individual building entities, enabling the use of rich priors and pretrained knowledge from 3D object generation while substantially reducing dependence on large-scale 3D city assets. Specifically, (1) we introduce the OSM-based spatial priors strategy to achieve interpretable geometric generation from spatial topology to building instances; (2) we design an appearance-guided controllable modeling mechanism for fine-grained appearance realism and style control; and (3) we construct an MLLM-powered semantic-guided generation pipeline, bridging semantic interpretation and geometric reconstruction. Extensive quantitative and qualitative experiments demonstrate that Sat2RealCity significantly surpasses existing baselines in structural consistency and appearance realism, establishing a strong foundation for real-world aligned 3D urban content creation. The code will be released soon.
DoReMi: A Domain-Representation Mixture Framework for Generalizable 3D Understanding
Nov 14, 2025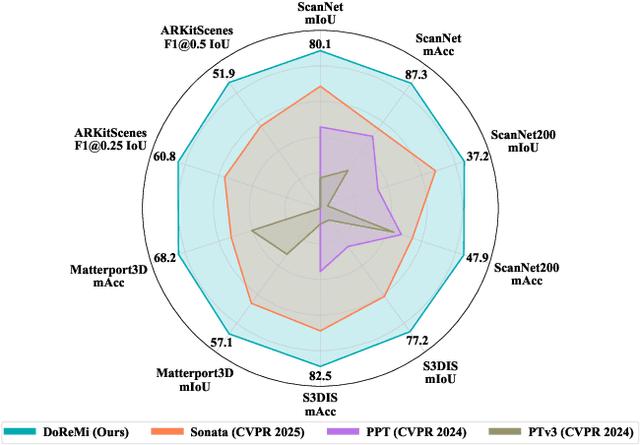
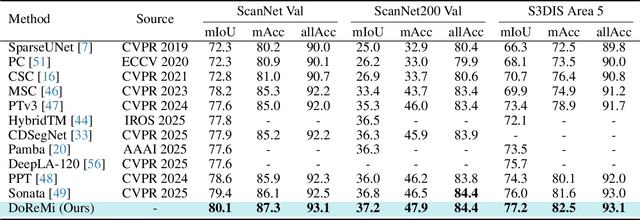
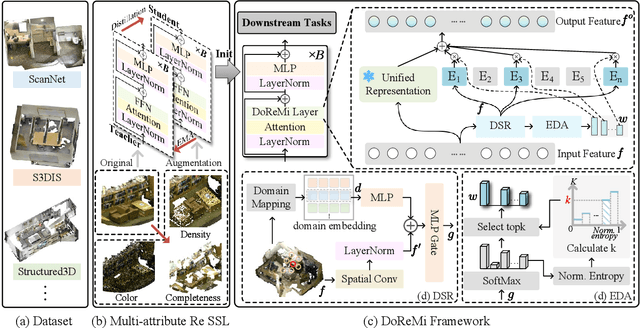

The generalization of 3D deep learning across multiple domains remains limited by the limited scale of existing datasets and the high heterogeneity of multi-source point clouds. Point clouds collected from different sensors (e.g., LiDAR scans and mesh-derived point clouds) exhibit substantial discrepancies in density and noise distribution, resulting in negative transfer during multi-domain fusion. Most existing approaches focus exclusively on either domain-aware or domain-general features, overlooking the potential synergy between them. To address this, we propose DoReMi (Domain-Representation Mixture), a Mixture-of-Experts (MoE) framework that jointly models Domain-aware Experts branch and a unified Representation branch to enable cooperative learning between specialized and generalizable knowledge. DoReMi dynamically activates domain-aware expert branch via Domain-Guided Spatial Routing (DSR) for context-aware expert selection and employs Entropy-Controlled Dynamic Allocation (EDA) for stable and efficient expert utilization, thereby adaptively modeling diverse domain distributions. Complemented by a frozen unified representation branch pretrained through robust multi-attribute self-supervised learning, DoReMi preserves cross-domain geometric and structural priors while maintaining global consistency. We evaluate DoReMi across multiple 3D understanding benchmarks. Notably, DoReMi achieves 80.1% mIoU on ScanNet Val and 77.2% mIoU on S3DIS, demonstrating competitive or superior performance compared to existing approaches, and showing strong potential as a foundation framework for future 3D understanding research. The code will be released soon.
ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
Mar 15, 2024Although Vision Transformer (ViT) has achieved significant success in computer vision, it does not perform well in dense prediction tasks due to the lack of inner-patch information interaction and the limited diversity of feature scale. Most existing studies are devoted to designing vision-specific transformers to solve the above problems, which introduce additional pre-training costs. Therefore, we present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks. (3) We evaluate the performance of ViT-CoMer across various dense prediction tasks, different frameworks, and multiple advanced pre-training. Notably, our ViT-CoMer-L achieves 64.3% AP on COCO val2017 without extra training data, and 62.1% mIoU on ADE20K val, both of which are comparable to state-of-the-art methods. We hope ViT-CoMer can serve as a new backbone for dense prediction tasks to facilitate future research. The code will be released at https://github.com/Traffic-X/ViT-CoMer.
Open-TransMind: A New Baseline and Benchmark for 1st Foundation Model Challenge of Intelligent Transportation
Apr 12, 2023



With the continuous improvement of computing power and deep learning algorithms in recent years, the foundation model has grown in popularity. Because of its powerful capabilities and excellent performance, this technology is being adopted and applied by an increasing number of industries. In the intelligent transportation industry, artificial intelligence faces the following typical challenges: few shots, poor generalization, and a lack of multi-modal techniques. Foundation model technology can significantly alleviate the aforementioned issues. To address these, we designed the 1st Foundation Model Challenge, with the goal of increasing the popularity of foundation model technology in traffic scenarios and promoting the rapid development of the intelligent transportation industry. The challenge is divided into two tracks: all-in-one and cross-modal image retrieval. Furthermore, we provide a new baseline and benchmark for the two tracks, called Open-TransMind. According to our knowledge, Open-TransMind is the first open-source transportation foundation model with multi-task and multi-modal capabilities. Simultaneously, Open-TransMind can achieve state-of-the-art performance on detection, classification, and segmentation datasets of traffic scenarios. Our source code is available at https://github.com/Traffic-X/Open-TransMind.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.