 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Iteration Distillation for Robust IHD Screening: The IDNet Framework and A New Benchmark
Jun 29, 2026Color Fundus Photography (CFP) offers a low-cost and non-invasive route for ischemic heart disease (IHD) screening, but current studies are limited by scarce public benchmarks and ineffective fusion of retinal images with sparse clinical variables. We propose IDNet, a multimodal framework with a Cross-Modal Distillation Aggregator (CDA) that uses learnable queries to sequentially integrate left-eye, right-eye, and clinical features, mitigating the imbalance between high-dimensional visual features and low-dimensional tabular inputs. We also construct a reproducible UK Biobank benchmark with open-source curation and quality-control pipelines, yielding 50,410 images from 25,205 subjects. On this benchmark, IDNet outperforms image-only, clinical-only, and several multimodal baselines, and CDA consistently improves multiple visual encoders as a plug-in fusion module.
Pointwise Generalization in Deep Neural Networks
May 18, 2026We address the fundamental question of why deep neural networks generalize by establishing a pointwise generalization theory for fully connected networks. This framework resolves long-standing barriers to characterizing the rich nonlinear feature-learning regime and builds a new statistical foundation for representation learning. For each trained model, we characterize the hypothesis via a pointwise Riemannian Dimension, derived from the eigenvalues of the learned feature representations across layers. This establishes a principled framework for deriving hypothesis-dependent, representation-aware generalization bounds. These bounds offer a systematic upgrade over approaches based on model size, products of norms, and infinite-width linearizations, yielding guarantees that are orders of magnitude tighter in both theory and experiment. Analytically, we identify the structural properties and mathematical principles that explain the tractability of deep networks. Empirically, the pointwise Riemannian Dimension exhibits substantial feature compression, decreases with increased over-parameterization, and captures the implicit bias of optimizers. Taken together, our results indicate that deep networks are mathematically tractable in practical regimes and that their generalization is sharply explained by pointwise, feature-spectrum-aware complexity.
Stability and Sharper Risk Bounds with Convergence Rate $O(1/n^2)$
Oct 13, 2024The sharpest known high probability excess risk bounds are up to $O\left( 1/n \right)$ for empirical risk minimization and projected gradient descent via algorithmic stability (Klochkov \& Zhivotovskiy, 2021). In this paper, we show that high probability excess risk bounds of order up to $O\left( 1/n^2 \right)$ are possible. We discuss how high probability excess risk bounds reach $O\left( 1/n^2 \right)$ under strongly convexity, smoothness and Lipschitz continuity assumptions for empirical risk minimization, projected gradient descent and stochastic gradient descent. Besides, to the best of our knowledge, our high probability results on the generalization gap measured by gradients for nonconvex problems are also the sharpest.
Towards Sharper Risk Bounds for Minimax Problems
Oct 11, 2024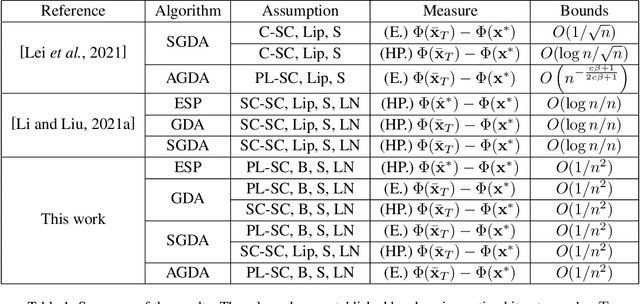
Minimax problems have achieved success in machine learning such as adversarial training, robust optimization, reinforcement learning. For theoretical analysis, current optimal excess risk bounds, which are composed by generalization error and optimization error, present 1/n-rates in strongly-convex-strongly-concave (SC-SC) settings. Existing studies mainly focus on minimax problems with specific algorithms for optimization error, with only a few studies on generalization performance, which limit better excess risk bounds. In this paper, we study the generalization bounds measured by the gradients of primal functions using uniform localized convergence. We obtain a sharper high probability generalization error bound for nonconvex-strongly-concave (NC-SC) stochastic minimax problems. Furthermore, we provide dimension-independent results under Polyak-Lojasiewicz condition for the outer layer. Based on our generalization error bound, we analyze some popular algorithms such as empirical saddle point (ESP), gradient descent ascent (GDA) and stochastic gradient descent ascent (SGDA). We derive better excess primal risk bounds with further reasonable assumptions, which, to the best of our knowledge, are n times faster than exist results in minimax problems.
EFCM: Efficient Fine-tuning on Compressed Models for deployment of large models in medical image analysis
Sep 18, 2024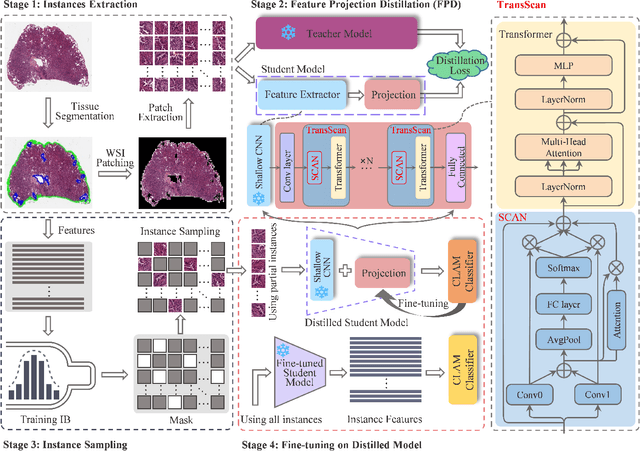
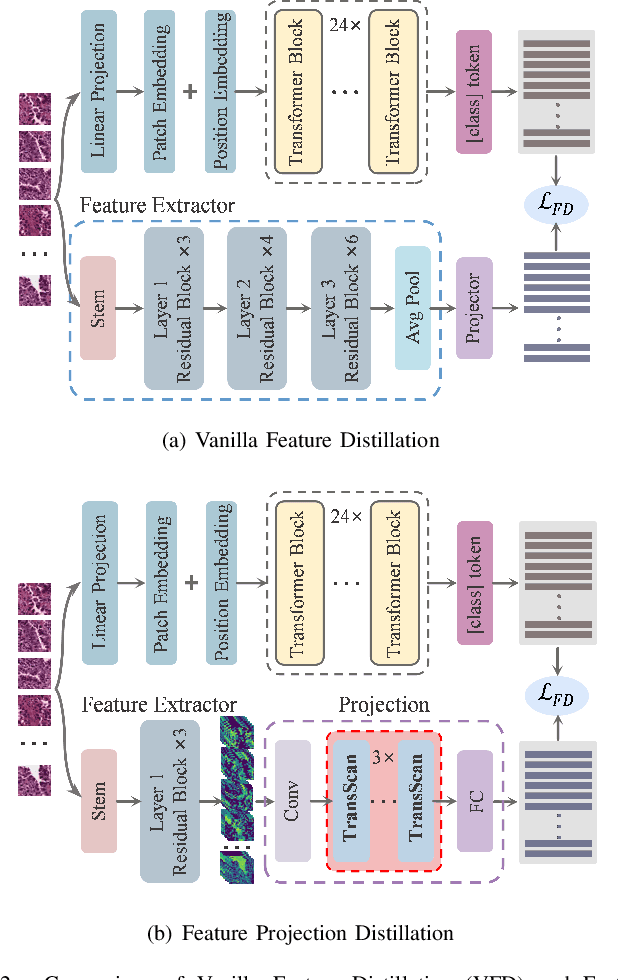
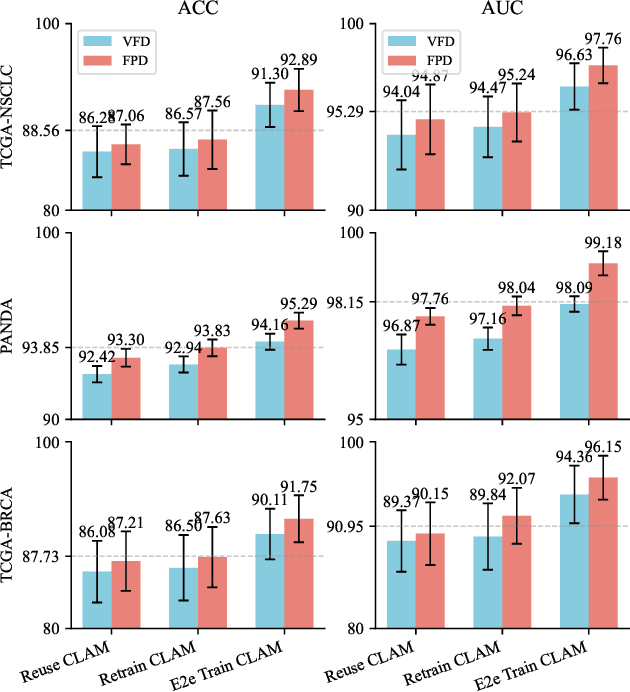
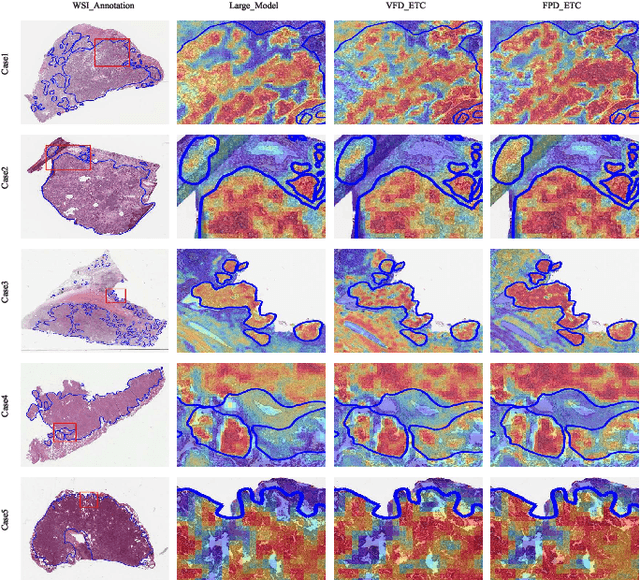
The recent development of deep learning large models in medicine shows remarkable performance in medical image analysis and diagnosis, but their large number of parameters causes memory and inference latency challenges. Knowledge distillation offers a solution, but the slide-level gradients cannot be backpropagated for student model updates due to high-resolution pathological images and slide-level labels. This study presents an Efficient Fine-tuning on Compressed Models (EFCM) framework with two stages: unsupervised feature distillation and fine-tuning. In the distillation stage, Feature Projection Distillation (FPD) is proposed with a TransScan module for adaptive receptive field adjustment to enhance the knowledge absorption capability of the student model. In the slide-level fine-tuning stage, three strategies (Reuse CLAM, Retrain CLAM, and End2end Train CLAM (ETC)) are compared. Experiments are conducted on 11 downstream datasets related to three large medical models: RETFound for retina, MRM for chest X-ray, and BROW for histopathology. The experimental results demonstrate that the EFCM framework significantly improves accuracy and efficiency in handling slide-level pathological image problems, effectively addressing the challenges of deploying large medical models. Specifically, it achieves a 4.33% increase in ACC and a 5.2% increase in AUC compared to the large model BROW on the TCGA-NSCLC and TCGA-BRCA datasets. The analysis of model inference efficiency highlights the high efficiency of the distillation fine-tuning method.
Leveraging Deep Learning and Xception Architecture for High-Accuracy MRI Classification in Alzheimer Diagnosis
Mar 24, 2024
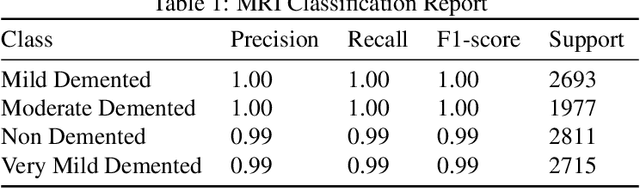
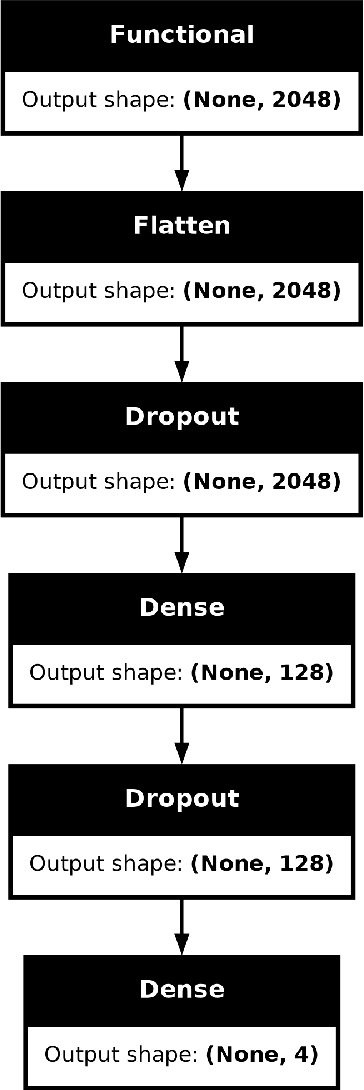
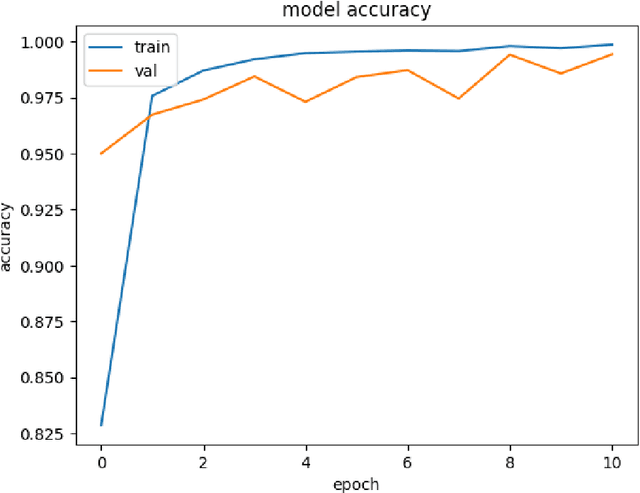
Exploring the application of deep learning technologies in the field of medical diagnostics, Magnetic Resonance Imaging (MRI) provides a unique perspective for observing and diagnosing complex neurodegenerative diseases such as Alzheimer Disease (AD). With advancements in deep learning, particularly in Convolutional Neural Networks (CNNs) and the Xception network architecture, we are now able to analyze and classify vast amounts of MRI data with unprecedented accuracy. The progress of this technology not only enhances our understanding of brain structural changes but also opens up new avenues for monitoring disease progression through non-invasive means and potentially allows for precise diagnosis in the early stages of the disease. This study aims to classify MRI images using deep learning models to identify different stages of Alzheimer Disease through a series of innovative data processing and model construction steps. Our experimental results show that the deep learning framework based on the Xception model achieved a 99.6% accuracy rate in the multi-class MRI image classification task, demonstrating its potential application value in assistive diagnosis. Future research will focus on expanding the dataset, improving model interpretability, and clinical validation to further promote the application of deep learning technology in the medical field, with the hope of bringing earlier diagnosis and more personalized treatment plans to Alzheimer Disease patients.
Utilizing the LightGBM Algorithm for Operator User Credit Assessment Research
Mar 21, 2024



Mobile Internet user credit assessment is an important way for communication operators to establish decisions and formulate measures, and it is also a guarantee for operators to obtain expected benefits. However, credit evaluation methods have long been monopolized by financial industries such as banks and credit. As supporters and providers of platform network technology and network resources, communication operators are also builders and maintainers of communication networks. Internet data improves the user's credit evaluation strategy. This paper uses the massive data provided by communication operators to carry out research on the operator's user credit evaluation model based on the fusion LightGBM algorithm. First, for the massive data related to user evaluation provided by operators, key features are extracted by data preprocessing and feature engineering methods, and a multi-dimensional feature set with statistical significance is constructed; then, linear regression, decision tree, LightGBM, and other machine learning algorithms build multiple basic models to find the best basic model; finally, integrates Averaging, Voting, Blending, Stacking and other integrated algorithms to refine multiple fusion models, and finally establish the most suitable fusion model for operator user evaluation.
Fostc3net:A Lightweight YOLOv5 Based On the Network Structure Optimization
Mar 20, 2024Transmission line detection technology is crucial for automatic monitoring and ensuring the safety of electrical facilities. The YOLOv5 series is currently one of the most advanced and widely used methods for object detection. However, it faces inherent challenges, such as high computational load on devices and insufficient detection accuracy. To address these concerns, this paper presents an enhanced lightweight YOLOv5 technique customized for mobile devices, specifically intended for identifying objects associated with transmission lines. The C3Ghost module is integrated into the convolutional network of YOLOv5 to reduce floating point operations per second (FLOPs) in the feature channel fusion process and improve feature expression performance. In addition, a FasterNet module is introduced to replace the c3 module in the YOLOv5 Backbone. The FasterNet module uses Partial Convolutions to process only a portion of the input channels, improving feature extraction efficiency and reducing computational overhead. To address the imbalance between simple and challenging samples in the dataset and the diversity of aspect ratios of bounding boxes, the wIoU v3 LOSS is adopted as the loss function. To validate the performance of the proposed approach, Experiments are conducted on a custom dataset of transmission line poles. The results show that the proposed model achieves a 1% increase in detection accuracy, a 13% reduction in FLOPs, and a 26% decrease in model parameters compared to the existing YOLOv5.In the ablation experiment, it was also discovered that while the Fastnet module and the CSghost module improved the precision of the original YOLOv5 baseline model, they caused a decrease in the mAP@.5-.95 metric. However, the improvement of the wIoUv3 loss function significantly mitigated the decline of the mAP@.5-.95 metric.
BROW: Better featuRes fOr Whole slide image based on self-distillation
Sep 15, 2023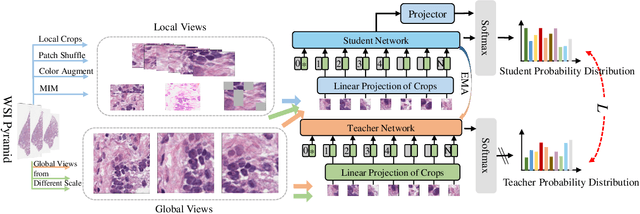
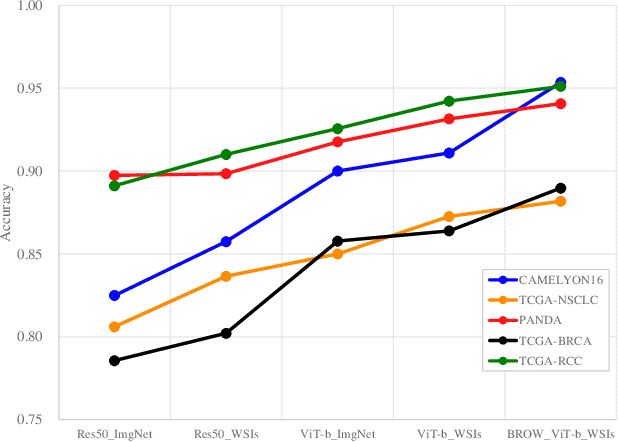
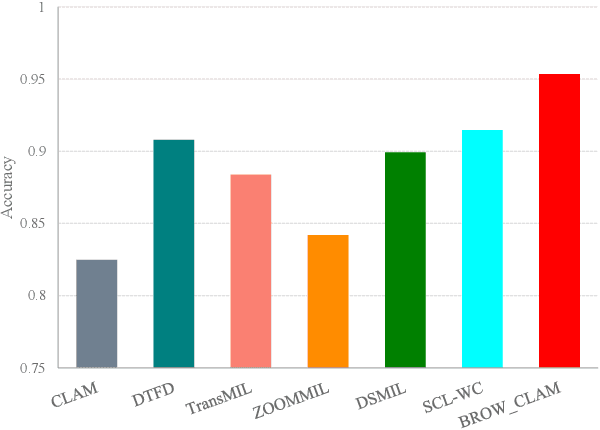
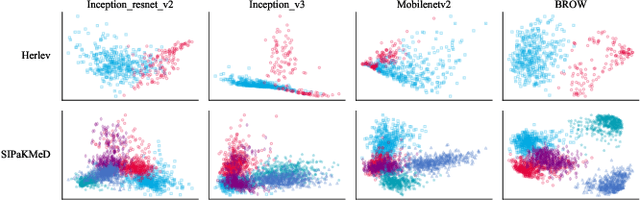
Whole slide image (WSI) processing is becoming part of the key components of standard clinical diagnosis for various diseases. However, the direct application of conventional image processing algorithms to WSI faces certain obstacles because of WSIs' distinct property: the super-high resolution. The performance of most WSI-related tasks relies on the efficacy of the backbone which extracts WSI patch feature representations. Hence, we proposed BROW, a foundation model for extracting better feature representations for WSIs, which can be conveniently adapted to downstream tasks without or with slight fine-tuning. The model takes transformer architecture, pretrained using self-distillation framework. To improve model's robustness, techniques such as patch shuffling have been employed. Additionally, the model leverages the unique properties of WSIs, utilizing WSI's multi-scale pyramid to incorporate an additional global view, thereby further enhancing its performance. We used both private and public data to make up a large pretraining dataset, containing more than 11000 slides, over 180M extracted patches, encompassing WSIs related to various organs and tissues. To assess the effectiveness of \ourmodel, we run a wide range of downstream tasks, including slide-level subtyping, patch-level classification and nuclei instance segmentation. The results confirmed the efficacy, robustness and good generalization ability of the proposed model. This substantiates its potential as foundation model for WSI feature extraction and highlights promising prospects for its application in WSI processing.
High Probability Analysis for Non-Convex Stochastic Optimization with Clipping
Jul 25, 2023Gradient clipping is a commonly used technique to stabilize the training process of neural networks. A growing body of studies has shown that gradient clipping is a promising technique for dealing with the heavy-tailed behavior that emerged in stochastic optimization as well. While gradient clipping is significant, its theoretical guarantees are scarce. Most theoretical guarantees only provide an in-expectation analysis and only focus on optimization performance. In this paper, we provide high probability analysis in the non-convex setting and derive the optimization bound and the generalization bound simultaneously for popular stochastic optimization algorithms with gradient clipping, including stochastic gradient descent and its variants of momentum and adaptive stepsizes. With the gradient clipping, we study a heavy-tailed assumption that the gradients only have bounded $\alpha$-th moments for some $\alpha \in (1, 2]$, which is much weaker than the standard bounded second-moment assumption. Overall, our study provides a relatively complete picture for the theoretical guarantee of stochastic optimization algorithms with clipping.