 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Product Flow Matching: Decoupling Radial and Angular Dynamics for Few-Shot Adaptation
May 06, 2026Recent flow matching (FM) methods improve the few-shot adaptation of vision-language models, by modeling cross-modal alignment as a continuous multi-step flow. In this paper, we argue that existing FM methods are inherently constrained by incompatible geometric priors on pre-trained cross-modal features, resulting in suboptimal adaptation performance. We first analyze these methods from a polar decomposition perspective (i.e., radial and angular sub-manifolds). Under this new geometric view, we identify three overlooked limitations in them: 1) Angular dynamics distortion: The radial-angular coupling induces non-uniform speed on the angular sub-manifold, leading to regression training difficulty and extra truncation errors. 2) Radial dynamics neglect: Feature normalization discards modality confidence, failing to distinguish out-of-distribution and in-distribution data, and abandoning crucial radial dynamics. 3) Context-agnostic unconditional flow: Dataset-specific information loss during pre-trained cross-modal feature extraction remains unrecovered. To resolve these issues, we propose warped product flow matching (WP-FM), a unified Riemannian framework that reformulates alignment on a warped product manifold. Within this framework, we derive direct product flow matching (DP-FM) by introducing a constant-warping metric, which yields a decoupled cylindrical manifold (i.e., direct product manifold). DP-FM enables independent radial evolution and constant-speed angular geodesic transport, effectively eliminating angular dynamics distortion while preserving radial consistency. Meanwhile, we incorporate classifier-free guidance by conditioning the flow on the pre-trained VLMs' hidden states to inject missing dataset-specific information. Extensive results across 11 benchmarks have demonstrated that DP-FM achieves a new state-of-the-art for multi-step few-shot adaptation.
IterIS: Iterative Inference-Solving Alignment for LoRA Merging
Nov 21, 2024



Low-rank adaptations (LoRA) are widely used to fine-tune large models across various domains for specific downstream tasks. While task-specific LoRAs are often available, concerns about data privacy and intellectual property can restrict access to training data, limiting the acquisition of a multi-task model through gradient-based training. In response, LoRA merging presents an effective solution by combining multiple LoRAs into a unified adapter while maintaining data privacy. Prior works on LoRA merging primarily frame it as an optimization problem, yet these approaches face several limitations, including the rough assumption about input features utilized in optimization, massive sample requirements, and the unbalanced optimization objective. These limitations can significantly degrade performance. To address these, we propose a novel optimization-based method, named IterIS: 1) We formulate LoRA merging as an advanced optimization problem to mitigate the rough assumption. Additionally, we employ an iterative inference-solving framework in our algorithm. It can progressively refine the optimization objective for improved performance. 2) We introduce an efficient regularization term to reduce the need for massive sample requirements (requiring only 1-5% of the unlabeled samples compared to prior methods). 3) We utilize adaptive weights in the optimization objective to mitigate potential unbalances in LoRA merging process. Our method demonstrates significant improvements over multiple baselines and state-of-the-art methods in composing tasks for text-to-image diffusion, vision-language models, and large language models. Furthermore, our layer-wise algorithm can achieve convergence with minimal steps, ensuring efficiency in both memory and computation.
Stability and Sharper Risk Bounds with Convergence Rate $O(1/n^2)$
Oct 13, 2024The sharpest known high probability excess risk bounds are up to $O\left( 1/n \right)$ for empirical risk minimization and projected gradient descent via algorithmic stability (Klochkov \& Zhivotovskiy, 2021). In this paper, we show that high probability excess risk bounds of order up to $O\left( 1/n^2 \right)$ are possible. We discuss how high probability excess risk bounds reach $O\left( 1/n^2 \right)$ under strongly convexity, smoothness and Lipschitz continuity assumptions for empirical risk minimization, projected gradient descent and stochastic gradient descent. Besides, to the best of our knowledge, our high probability results on the generalization gap measured by gradients for nonconvex problems are also the sharpest.
Towards Sharper Risk Bounds for Minimax Problems
Oct 11, 2024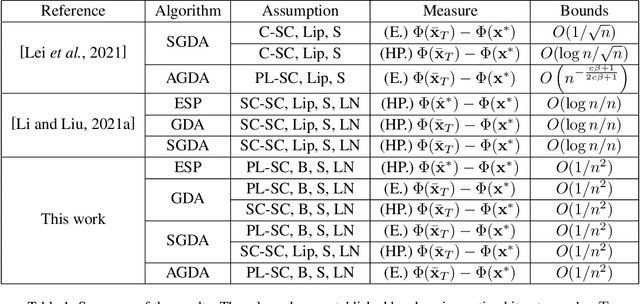
Minimax problems have achieved success in machine learning such as adversarial training, robust optimization, reinforcement learning. For theoretical analysis, current optimal excess risk bounds, which are composed by generalization error and optimization error, present 1/n-rates in strongly-convex-strongly-concave (SC-SC) settings. Existing studies mainly focus on minimax problems with specific algorithms for optimization error, with only a few studies on generalization performance, which limit better excess risk bounds. In this paper, we study the generalization bounds measured by the gradients of primal functions using uniform localized convergence. We obtain a sharper high probability generalization error bound for nonconvex-strongly-concave (NC-SC) stochastic minimax problems. Furthermore, we provide dimension-independent results under Polyak-Lojasiewicz condition for the outer layer. Based on our generalization error bound, we analyze some popular algorithms such as empirical saddle point (ESP), gradient descent ascent (GDA) and stochastic gradient descent ascent (SGDA). We derive better excess primal risk bounds with further reasonable assumptions, which, to the best of our knowledge, are n times faster than exist results in minimax problems.