 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Traffic: A Text-to-Image Generation and Editing Method for Traffic Scenes
Nov 17, 2025With the rapid advancement of intelligent transportation systems, text-driven image generation and editing techniques have demonstrated significant potential in providing rich, controllable visual scene data for applications such as traffic monitoring and autonomous driving. However, several challenges remain, including insufficient semantic richness of generated traffic elements, limited camera viewpoints, low visual fidelity of synthesized images, and poor alignment between textual descriptions and generated content. To address these issues, we propose a unified text-driven framework for both image generation and editing, leveraging a controllable mask mechanism to seamlessly integrate the two tasks. Furthermore, we incorporate both vehicle-side and roadside multi-view data to enhance the geometric diversity of traffic scenes. Our training strategy follows a two-stage paradigm: first, we perform conceptual learning using large-scale coarse-grained text-image data; then, we fine-tune with fine-grained descriptive data to enhance text-image alignment and detail quality. Additionally, we introduce a mask-region-weighted loss that dynamically emphasizes small yet critical regions during training, thereby substantially enhancing the generation fidelity of small-scale traffic elements. Extensive experiments demonstrate that our method achieves leading performance in text-based image generation and editing within traffic scenes.
RT-DATR:Real-time Unsupervised Domain Adaptive Detection Transformer with Adversarial Feature Learning
Apr 12, 2025

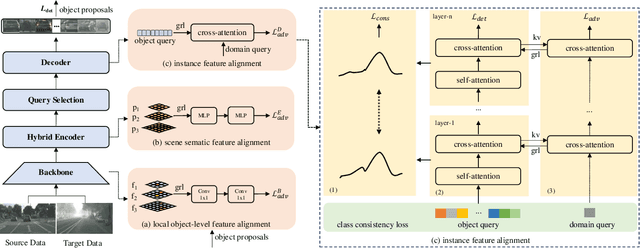

Despite domain-adaptive object detectors based on CNN and transformers have made significant progress in cross-domain detection tasks, it is regrettable that domain adaptation for real-time transformer-based detectors has not yet been explored. Directly applying existing domain adaptation algorithms has proven to be suboptimal. In this paper, we propose RT-DATR, a simple and efficient real-time domain adaptive detection transformer. Building on RT-DETR as our base detector, we first introduce a local object-level feature alignment module to significantly enhance the feature representation of domain invariance during object transfer. Additionally, we introduce a scene semantic feature alignment module designed to boost cross-domain detection performance by aligning scene semantic features. Finally, we introduced a domain query and decoupled it from the object query to further align the instance feature distribution within the decoder layer, reduce the domain gap, and maintain discriminative ability. Experimental results on various benchmarks demonstrate that our method outperforms current state-of-the-art approaches. Our code will be released soon.
RT-DETRv3: Real-time End-to-End Object Detection with Hierarchical Dense Positive Supervision
Sep 13, 2024



RT-DETR is the first real-time end-to-end transformer-based object detector. Its efficiency comes from the framework design and the Hungarian matching. However, compared to dense supervision detectors like the YOLO series, the Hungarian matching provides much sparser supervision, leading to insufficient model training and difficult to achieve optimal results. To address these issues, we proposed a hierarchical dense positive supervision method based on RT-DETR, named RT-DETRv3. Firstly, we introduce a CNN-based auxiliary branch that provides dense supervision that collaborates with the original decoder to enhance the encoder feature representation. Secondly, to address insufficient decoder training, we propose a novel learning strategy involving self-attention perturbation. This strategy diversifies label assignment for positive samples across multiple query groups, thereby enriching positive supervisions. Additionally, we introduce a shared-weight decoder branch for dense positive supervision to ensure more high-quality queries matching each ground truth. Notably, all aforementioned modules are training-only. We conduct extensive experiments to demonstrate the effectiveness of our approach on COCO val2017. RT-DETRv3 significantly outperforms existing real-time detectors, including the RT-DETR series and the YOLO series. For example, RT-DETRv3-R18 achieves 48.1% AP (+1.6%/+1.4%) compared to RT-DETR-R18/RT-DETRv2-R18 while maintaining the same latency. Meanwhile, it requires only half of epochs to attain a comparable performance. Furthermore, RT-DETRv3-R101 can attain an impressive 54.6% AP outperforming YOLOv10-X. Code will be released soon.
ViT-CoMer: Vision Transformer with Convolutional Multi-scale Feature Interaction for Dense Predictions
Mar 15, 2024



Although Vision Transformer (ViT) has achieved significant success in computer vision, it does not perform well in dense prediction tasks due to the lack of inner-patch information interaction and the limited diversity of feature scale. Most existing studies are devoted to designing vision-specific transformers to solve the above problems, which introduce additional pre-training costs. Therefore, we present a plain, pre-training-free, and feature-enhanced ViT backbone with Convolutional Multi-scale feature interaction, named ViT-CoMer, which facilitates bidirectional interaction between CNN and transformer. Compared to the state-of-the-art, ViT-CoMer has the following advantages: (1) We inject spatial pyramid multi-receptive field convolutional features into the ViT architecture, which effectively alleviates the problems of limited local information interaction and single-feature representation in ViT. (2) We propose a simple and efficient CNN-Transformer bidirectional fusion interaction module that performs multi-scale fusion across hierarchical features, which is beneficial for handling dense prediction tasks. (3) We evaluate the performance of ViT-CoMer across various dense prediction tasks, different frameworks, and multiple advanced pre-training. Notably, our ViT-CoMer-L achieves 64.3% AP on COCO val2017 without extra training data, and 62.1% mIoU on ADE20K val, both of which are comparable to state-of-the-art methods. We hope ViT-CoMer can serve as a new backbone for dense prediction tasks to facilitate future research. The code will be released at https://github.com/Traffic-X/ViT-CoMer.
Open-TransMind: A New Baseline and Benchmark for 1st Foundation Model Challenge of Intelligent Transportation
Apr 12, 2023



With the continuous improvement of computing power and deep learning algorithms in recent years, the foundation model has grown in popularity. Because of its powerful capabilities and excellent performance, this technology is being adopted and applied by an increasing number of industries. In the intelligent transportation industry, artificial intelligence faces the following typical challenges: few shots, poor generalization, and a lack of multi-modal techniques. Foundation model technology can significantly alleviate the aforementioned issues. To address these, we designed the 1st Foundation Model Challenge, with the goal of increasing the popularity of foundation model technology in traffic scenarios and promoting the rapid development of the intelligent transportation industry. The challenge is divided into two tracks: all-in-one and cross-modal image retrieval. Furthermore, we provide a new baseline and benchmark for the two tracks, called Open-TransMind. According to our knowledge, Open-TransMind is the first open-source transportation foundation model with multi-task and multi-modal capabilities. Simultaneously, Open-TransMind can achieve state-of-the-art performance on detection, classification, and segmentation datasets of traffic scenarios. Our source code is available at https://github.com/Traffic-X/Open-TransMind.
Abrupt Motion Tracking via Nearest Neighbor Field Driven Stochastic Sampling
Jan 21, 2015
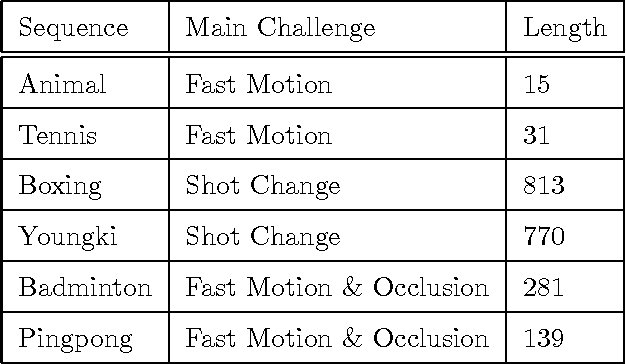
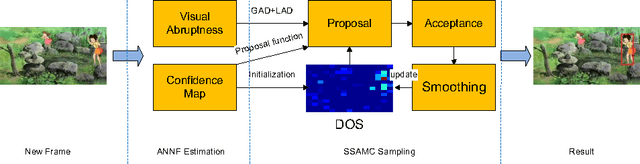
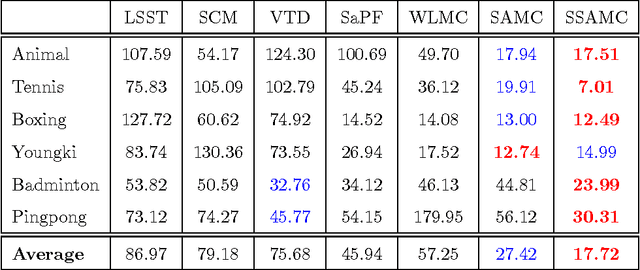
Stochastic sampling based trackers have shown good performance for abrupt motion tracking so that they have gained popularity in recent years. However, conventional methods tend to use a two-stage sampling paradigm, in which the search space needs to be uniformly explored with an inefficient preliminary sampling phase. In this paper, we propose a novel sampling-based method in the Bayesian filtering framework to address the problem. Within the framework, nearest neighbor field estimation is utilized to compute the importance proposal probabilities, which guide the Markov chain search towards promising regions and thus enhance the sampling efficiency; given the motion priors, a smoothing stochastic sampling Monte Carlo algorithm is proposed to approximate the posterior distribution through a smoothing weight-updating scheme. Moreover, to track the abrupt and the smooth motions simultaneously, we develop an abrupt-motion detection scheme which can discover the presence of abrupt motions during online tracking. Extensive experiments on challenging image sequences demonstrate the effectiveness and the robustness of our algorithm in handling the abrupt motions.