 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasicAVSR: Arbitrary-Scale Video Super-Resolution via Image Priors and Enhanced Motion Compensation
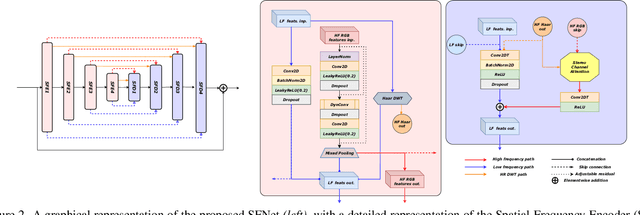
Oct 30, 2025Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we propose a strong baseline BasicAVSR for AVSR by integrating four key components: 1) adaptive multi-scale frequency priors generated from image Laplacian pyramids, 2) a flow-guided propagation unit to aggregate spatiotemporal information from adjacent frames, 3) a second-order motion compensation unit for more accurate spatial alignment of adjacent frames, and 4) a hyper-upsampling unit to generate scale-aware and content-independent upsampling kernels. To meet diverse application demands, we instantiate three propagation variants: (i) a unidirectional RNN unit for strictly online inference, (ii) a unidirectional RNN unit empowered with a limited lookahead that tolerates a small output delay, and (iii) a bidirectional RNN unit designed for offline tasks where computational resources are less constrained. Experimental results demonstrate the effectiveness and adaptability of our model across these different scenarios. Through extensive experiments, we show that BasicAVSR significantly outperforms existing methods in terms of super-resolution quality, generalization ability, and inference speed. Our work not only advances the state-of-the-art in AVSR but also extends its core components to multiple frameworks for diverse scenarios. The code is available at https://github.com/shangwei5/BasicAVSR.
Motion-Aware Adaptive Pixel Pruning for Efficient Local Motion Deblurring
Jul 10, 2025Local motion blur in digital images originates from the relative motion between dynamic objects and static imaging systems during exposure. Existing deblurring methods face significant challenges in addressing this problem due to their inefficient allocation of computational resources and inadequate handling of spatially varying blur patterns. To overcome these limitations, we first propose a trainable mask predictor that identifies blurred regions in the image. During training, we employ blur masks to exclude sharp regions. For inference optimization, we implement structural reparameterization by converting $3\times 3$ convolutions to computationally efficient $1\times 1$ convolutions, enabling pixel-level pruning of sharp areas to reduce computation. Second, we develop an intra-frame motion analyzer that translates relative pixel displacements into motion trajectories, establishing adaptive guidance for region-specific blur restoration. Our method is trained end-to-end using a combination of reconstruction loss, reblur loss, and mask loss guided by annotated blur masks. Extensive experiments demonstrate superior performance over state-of-the-art methods on both local and global blur datasets while reducing FLOPs by 49\% compared to SOTA models (e.g., LMD-ViT). The source code is available at https://github.com/shangwei5/M2AENet.
Efficient RAW Image Deblurring with Adaptive Frequency Modulation
May 30, 2025Image deblurring plays a crucial role in enhancing visual clarity across various applications. Although most deep learning approaches primarily focus on sRGB images, which inherently lose critical information during the image signal processing pipeline, RAW images, being unprocessed and linear, possess superior restoration potential but remain underexplored. Deblurring RAW images presents unique challenges, particularly in handling frequency-dependent blur while maintaining computational efficiency. To address these issues, we propose Frequency Enhanced Network (FrENet), a framework specifically designed for RAW-to-RAW deblurring that operates directly in the frequency domain. We introduce a novel Adaptive Frequency Positional Modulation module, which dynamically adjusts frequency components according to their spectral positions, thereby enabling precise control over the deblurring process. Additionally, frequency domain skip connections are adopted to further preserve high-frequency details. Experimental results demonstrate that FrENet surpasses state-of-the-art deblurring methods in RAW image deblurring, achieving significantly better restoration quality while maintaining high efficiency in terms of reduced MACs. Furthermore, FrENet's adaptability enables it to be extended to sRGB images, where it delivers comparable or superior performance compared to methods specifically designed for sRGB data. The code will be available at https://github.com/WenlongJiao/FrENet .
High-Frequency Prior-Driven Adaptive Masking for Accelerating Image Super-Resolution
May 11, 2025
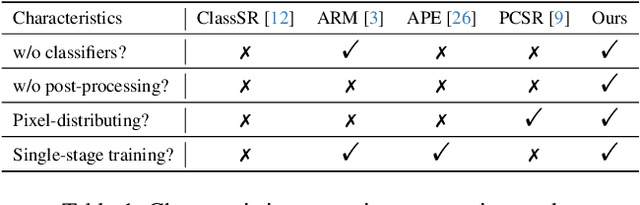
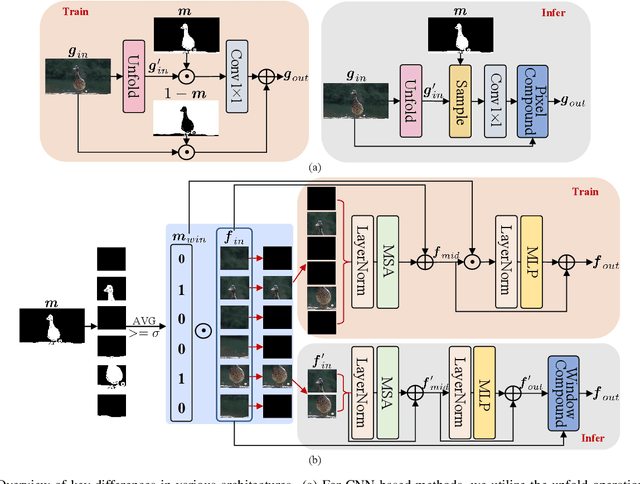
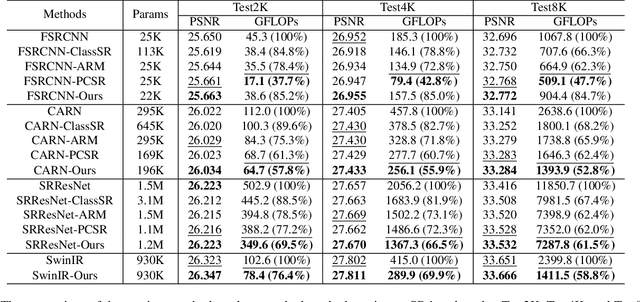
The primary challenge in accelerating image super-resolution lies in reducing computation while maintaining performance and adaptability. Motivated by the observation that high-frequency regions (e.g., edges and textures) are most critical for reconstruction, we propose a training-free adaptive masking module for acceleration that dynamically focuses computation on these challenging areas. Specifically, our method first extracts high-frequency components via Gaussian blur subtraction and adaptively generates binary masks using K-means clustering to identify regions requiring intensive processing. Our method can be easily integrated with both CNNs and Transformers. For CNN-based architectures, we replace standard $3 \times 3$ convolutions with an unfold operation followed by $1 \times 1$ convolutions, enabling pixel-wise sparse computation guided by the mask. For Transformer-based models, we partition the mask into non-overlapping windows and selectively process tokens based on their average values. During inference, unnecessary pixels or windows are pruned, significantly reducing computation. Moreover, our method supports dilation-based mask adjustment to control the processing scope without retraining, and is robust to unseen degradations (e.g., noise, compression). Extensive experiments on benchmarks demonstrate that our method reduces FLOPs by 24--43% for state-of-the-art models (e.g., CARN, SwinIR) while achieving comparable or better quantitative metrics. The source code is available at https://github.com/shangwei5/AMSR
SelfDRSC++: Self-Supervised Learning for Dual Reversed Rolling Shutter Correction
Aug 21, 2024



Modern consumer cameras commonly employ the rolling shutter (RS) imaging mechanism, via which images are captured by scanning scenes row-by-row, resulting in RS distortion for dynamic scenes. To correct RS distortion, existing methods adopt a fully supervised learning manner that requires high framerate global shutter (GS) images as ground-truth for supervision. In this paper, we propose an enhanced Self-supervised learning framework for Dual reversed RS distortion Correction (SelfDRSC++). Firstly, we introduce a lightweight DRSC network that incorporates a bidirectional correlation matching block to refine the joint optimization of optical flows and corrected RS features, thereby improving correction performance while reducing network parameters. Subsequently, to effectively train the DRSC network, we propose a self-supervised learning strategy that ensures cycle consistency between input and reconstructed dual reversed RS images. The RS reconstruction in SelfDRSC++ can be interestingly formulated as a specialized instance of video frame interpolation, where each row in reconstructed RS images is interpolated from predicted GS images by utilizing RS distortion time maps. By achieving superior performance while simplifying the training process, SelfDRSC++ enables feasible one-stage self-supervised training. Additionally, besides start and end RS scanning time, SelfDRSC++ allows supervision of GS images at arbitrary intermediate scanning times, thus enabling the learned DRSC network to generate high framerate GS videos. The code and trained models are available at \url{https://github.com/shangwei5/SelfDRSC_plusplus}.
Thin-Plate Spline-based Interpolation for Animation Line Inbetweening
Aug 17, 2024



Animation line inbetweening is a crucial step in animation production aimed at enhancing animation fluidity by predicting intermediate line arts between two key frames. However, existing methods face challenges in effectively addressing sparse pixels and significant motion in line art key frames. In literature, Chamfer Distance (CD) is commonly adopted for evaluating inbetweening performance. Despite achieving favorable CD values, existing methods often generate interpolated frames with line disconnections, especially for scenarios involving large motion. Motivated by this observation, we propose a simple yet effective interpolation method for animation line inbetweening that adopts thin-plate spline-based transformation to estimate coarse motion more accurately by modeling the keypoint correspondence between two key frames, particularly for large motion scenarios. Building upon the coarse estimation, a motion refine module is employed to further enhance motion details before final frame interpolation using a simple UNet model. Furthermore, to more accurately assess the performance of animation line inbetweening, we refine the CD metric and introduce a novel metric termed Weighted Chamfer Distance, which demonstrates a higher consistency with visual perception quality. Additionally, we incorporate Earth Mover's Distance and conduct user study to provide a more comprehensive evaluation. Our method outperforms existing approaches by delivering high-quality interpolation results with enhanced fluidity. The code is available at \url{https://github.com/Tian-one/tps-inbetween}.
Arbitrary-Scale Video Super-Resolution with Structural and Textural Priors
Jul 13, 2024
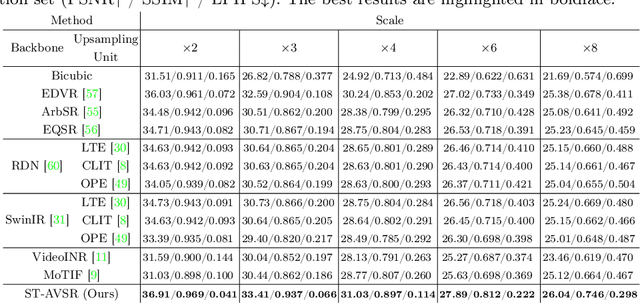
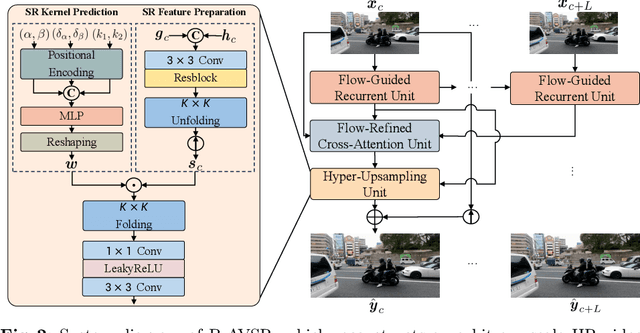
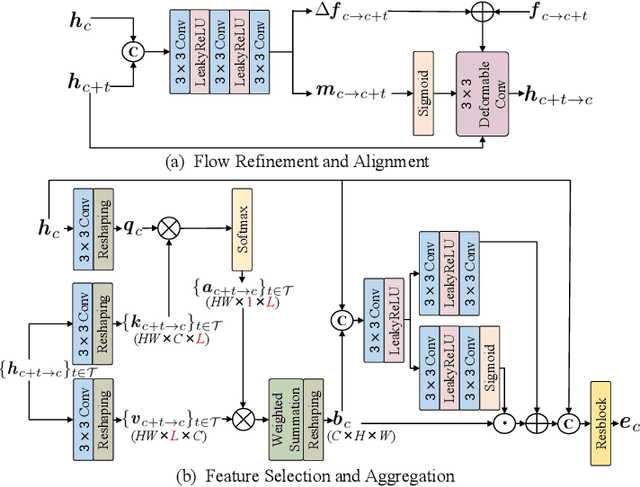
Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we first describe a strong baseline for AVSR by putting together three variants of elementary building blocks: 1) a flow-guided recurrent unit that aggregates spatiotemporal information from previous frames, 2) a flow-refined cross-attention unit that selects spatiotemporal information from future frames, and 3) a hyper-upsampling unit that generates scaleaware and content-independent upsampling kernels. We then introduce ST-AVSR by equipping our baseline with a multi-scale structural and textural prior computed from the pre-trained VGG network. This prior has proven effective in discriminating structure and texture across different locations and scales, which is beneficial for AVSR. Comprehensive experiments show that ST-AVSR significantly improves super-resolution quality, generalization ability, and inference speed over the state-of-theart. The code is available at https://github.com/shangwei5/ST-AVSR.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024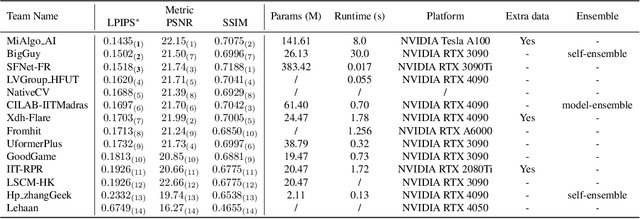
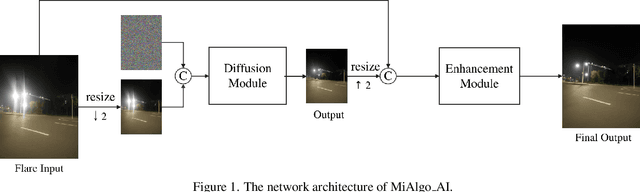
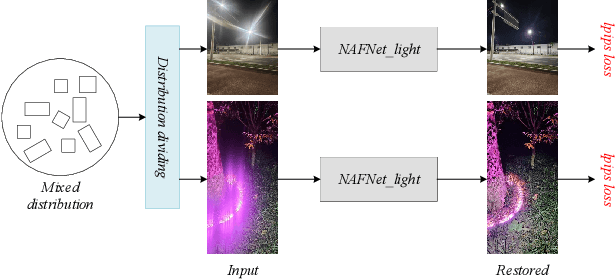
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Aggregating Long-term Sharp Features via Hybrid Transformers for Video Deblurring
Sep 13, 2023

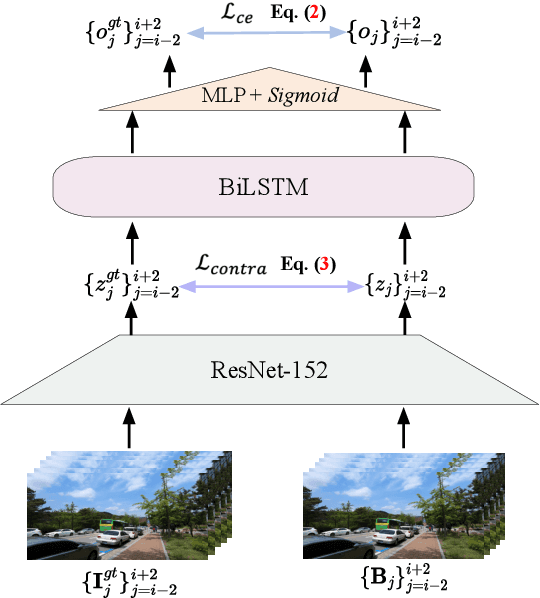

Video deblurring methods, aiming at recovering consecutive sharp frames from a given blurry video, usually assume that the input video suffers from consecutively blurry frames. However, in real-world blurry videos taken by modern imaging devices, sharp frames usually appear in the given video, thus making temporal long-term sharp features available for facilitating the restoration of a blurry frame. In this work, we propose a video deblurring method that leverages both neighboring frames and present sharp frames using hybrid Transformers for feature aggregation. Specifically, we first train a blur-aware detector to distinguish between sharp and blurry frames. Then, a window-based local Transformer is employed for exploiting features from neighboring frames, where cross attention is beneficial for aggregating features from neighboring frames without explicit spatial alignment. To aggregate long-term sharp features from detected sharp frames, we utilize a global Transformer with multi-scale matching capability. Moreover, our method can easily be extended to event-driven video deblurring by incorporating an event fusion module into the global Transformer. Extensive experiments on benchmark datasets demonstrate that our proposed method outperforms state-of-the-art video deblurring methods as well as event-driven video deblurring methods in terms of quantitative metrics and visual quality. The source code and trained models are available at https://github.com/shangwei5/STGTN.
Self-supervised Learning to Bring Dual Reversed Rolling Shutter Images Alive
May 31, 2023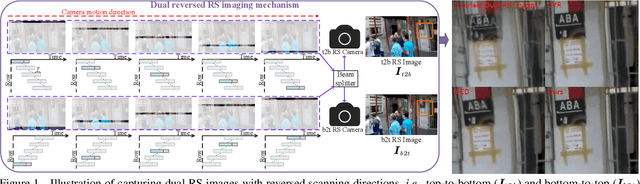

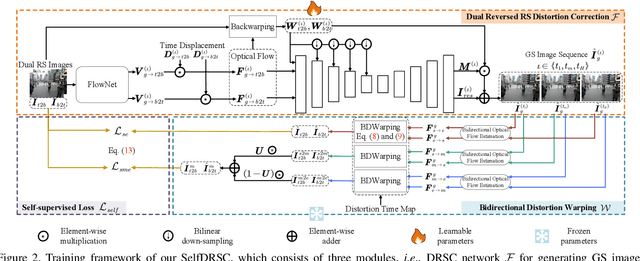
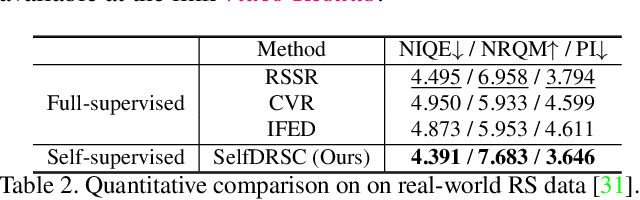
Modern consumer cameras usually employ the rolling shutter (RS) mechanism, where images are captured by scanning scenes row-by-row, yielding RS distortions for dynamic scenes. To correct RS distortions, existing methods adopt a fully supervised learning manner, where high framerate global shutter (GS) images should be collected as ground-truth supervision. In this paper, we propose a Self-supervised learning framework for Dual reversed RS distortions Correction (SelfDRSC), where a DRSC network can be learned to generate a high framerate GS video only based on dual RS images with reversed distortions. In particular, a bidirectional distortion warping module is proposed for reconstructing dual reversed RS images, and then a self-supervised loss can be deployed to train DRSC network by enhancing the cycle consistency between input and reconstructed dual reversed RS images. Besides start and end RS scanning time, GS images at arbitrary intermediate scanning time can also be supervised in SelfDRSC, thus enabling the learned DRSC network to generate a high framerate GS video. Moreover, a simple yet effective self-distillation strategy is introduced in self-supervised loss for mitigating boundary artifacts in generated GS images. On synthetic dataset, SelfDRSC achieves better or comparable quantitative metrics in comparison to state-of-the-art methods trained in the full supervision manner. On real-world RS cases, our SelfDRSC can produce high framerate GS videos with finer correction textures and better temporary consistency. The source code and trained models are made publicly available at https://github.com/shangwei5/SelfDRSC.