 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBasicAVSR: Arbitrary-Scale Video Super-Resolution via Image Priors and Enhanced Motion Compensation
Oct 30, 2025Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we propose a strong baseline BasicAVSR for AVSR by integrating four key components: 1) adaptive multi-scale frequency priors generated from image Laplacian pyramids, 2) a flow-guided propagation unit to aggregate spatiotemporal information from adjacent frames, 3) a second-order motion compensation unit for more accurate spatial alignment of adjacent frames, and 4) a hyper-upsampling unit to generate scale-aware and content-independent upsampling kernels. To meet diverse application demands, we instantiate three propagation variants: (i) a unidirectional RNN unit for strictly online inference, (ii) a unidirectional RNN unit empowered with a limited lookahead that tolerates a small output delay, and (iii) a bidirectional RNN unit designed for offline tasks where computational resources are less constrained. Experimental results demonstrate the effectiveness and adaptability of our model across these different scenarios. Through extensive experiments, we show that BasicAVSR significantly outperforms existing methods in terms of super-resolution quality, generalization ability, and inference speed. Our work not only advances the state-of-the-art in AVSR but also extends its core components to multiple frameworks for diverse scenarios. The code is available at https://github.com/shangwei5/BasicAVSR.
Motion-Aware Adaptive Pixel Pruning for Efficient Local Motion Deblurring
Jul 10, 2025Local motion blur in digital images originates from the relative motion between dynamic objects and static imaging systems during exposure. Existing deblurring methods face significant challenges in addressing this problem due to their inefficient allocation of computational resources and inadequate handling of spatially varying blur patterns. To overcome these limitations, we first propose a trainable mask predictor that identifies blurred regions in the image. During training, we employ blur masks to exclude sharp regions. For inference optimization, we implement structural reparameterization by converting $3\times 3$ convolutions to computationally efficient $1\times 1$ convolutions, enabling pixel-level pruning of sharp areas to reduce computation. Second, we develop an intra-frame motion analyzer that translates relative pixel displacements into motion trajectories, establishing adaptive guidance for region-specific blur restoration. Our method is trained end-to-end using a combination of reconstruction loss, reblur loss, and mask loss guided by annotated blur masks. Extensive experiments demonstrate superior performance over state-of-the-art methods on both local and global blur datasets while reducing FLOPs by 49\% compared to SOTA models (e.g., LMD-ViT). The source code is available at https://github.com/shangwei5/M2AENet.
High-Frequency Prior-Driven Adaptive Masking for Accelerating Image Super-Resolution
May 11, 2025
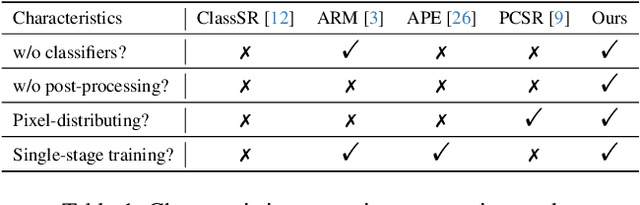
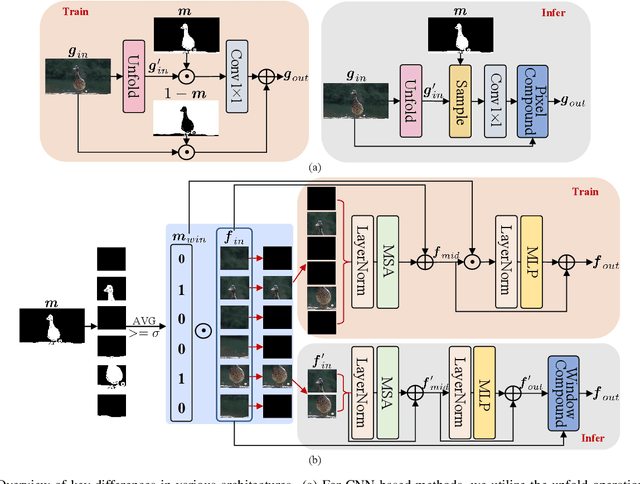
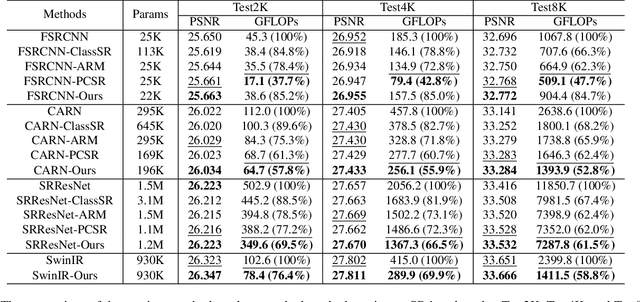
The primary challenge in accelerating image super-resolution lies in reducing computation while maintaining performance and adaptability. Motivated by the observation that high-frequency regions (e.g., edges and textures) are most critical for reconstruction, we propose a training-free adaptive masking module for acceleration that dynamically focuses computation on these challenging areas. Specifically, our method first extracts high-frequency components via Gaussian blur subtraction and adaptively generates binary masks using K-means clustering to identify regions requiring intensive processing. Our method can be easily integrated with both CNNs and Transformers. For CNN-based architectures, we replace standard $3 \times 3$ convolutions with an unfold operation followed by $1 \times 1$ convolutions, enabling pixel-wise sparse computation guided by the mask. For Transformer-based models, we partition the mask into non-overlapping windows and selectively process tokens based on their average values. During inference, unnecessary pixels or windows are pruned, significantly reducing computation. Moreover, our method supports dilation-based mask adjustment to control the processing scope without retraining, and is robust to unseen degradations (e.g., noise, compression). Extensive experiments on benchmarks demonstrate that our method reduces FLOPs by 24--43% for state-of-the-art models (e.g., CARN, SwinIR) while achieving comparable or better quantitative metrics. The source code is available at https://github.com/shangwei5/AMSR
SelfDRSC++: Self-Supervised Learning for Dual Reversed Rolling Shutter Correction
Aug 21, 2024



Modern consumer cameras commonly employ the rolling shutter (RS) imaging mechanism, via which images are captured by scanning scenes row-by-row, resulting in RS distortion for dynamic scenes. To correct RS distortion, existing methods adopt a fully supervised learning manner that requires high framerate global shutter (GS) images as ground-truth for supervision. In this paper, we propose an enhanced Self-supervised learning framework for Dual reversed RS distortion Correction (SelfDRSC++). Firstly, we introduce a lightweight DRSC network that incorporates a bidirectional correlation matching block to refine the joint optimization of optical flows and corrected RS features, thereby improving correction performance while reducing network parameters. Subsequently, to effectively train the DRSC network, we propose a self-supervised learning strategy that ensures cycle consistency between input and reconstructed dual reversed RS images. The RS reconstruction in SelfDRSC++ can be interestingly formulated as a specialized instance of video frame interpolation, where each row in reconstructed RS images is interpolated from predicted GS images by utilizing RS distortion time maps. By achieving superior performance while simplifying the training process, SelfDRSC++ enables feasible one-stage self-supervised training. Additionally, besides start and end RS scanning time, SelfDRSC++ allows supervision of GS images at arbitrary intermediate scanning times, thus enabling the learned DRSC network to generate high framerate GS videos. The code and trained models are available at \url{https://github.com/shangwei5/SelfDRSC_plusplus}.
Arbitrary-Scale Video Super-Resolution with Structural and Textural Priors
Jul 13, 2024
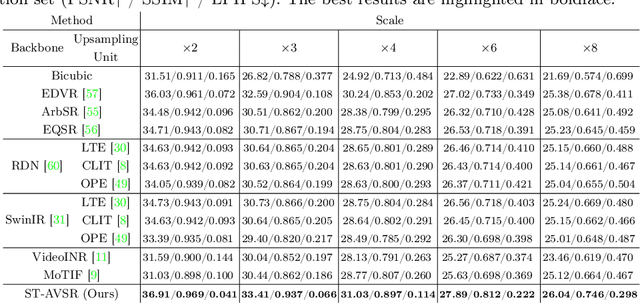
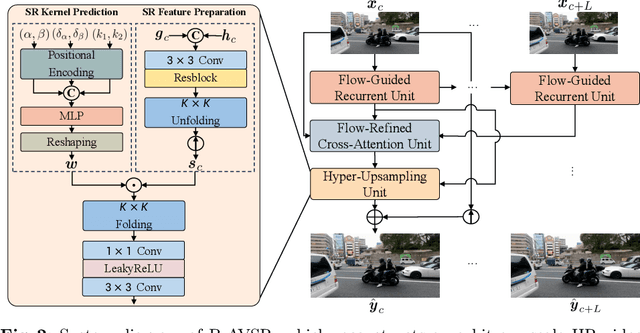
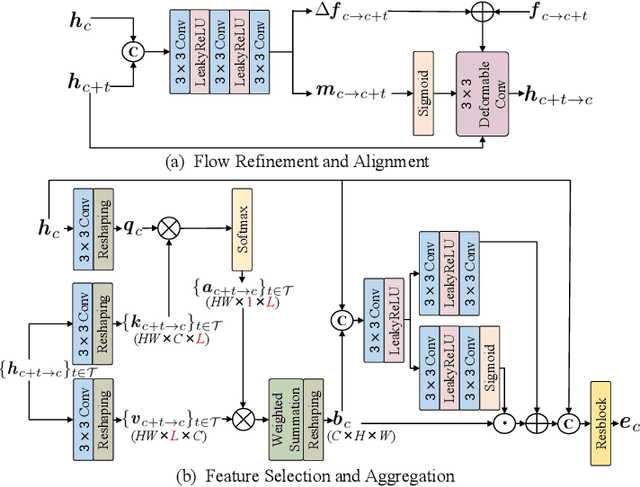
Arbitrary-scale video super-resolution (AVSR) aims to enhance the resolution of video frames, potentially at various scaling factors, which presents several challenges regarding spatial detail reproduction, temporal consistency, and computational complexity. In this paper, we first describe a strong baseline for AVSR by putting together three variants of elementary building blocks: 1) a flow-guided recurrent unit that aggregates spatiotemporal information from previous frames, 2) a flow-refined cross-attention unit that selects spatiotemporal information from future frames, and 3) a hyper-upsampling unit that generates scaleaware and content-independent upsampling kernels. We then introduce ST-AVSR by equipping our baseline with a multi-scale structural and textural prior computed from the pre-trained VGG network. This prior has proven effective in discriminating structure and texture across different locations and scales, which is beneficial for AVSR. Comprehensive experiments show that ST-AVSR significantly improves super-resolution quality, generalization ability, and inference speed over the state-of-theart. The code is available at https://github.com/shangwei5/ST-AVSR.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024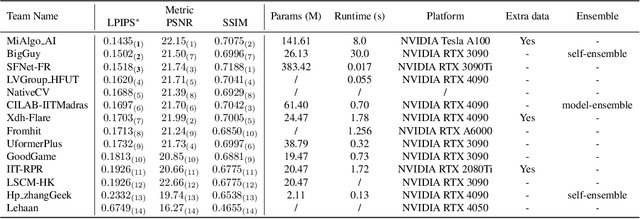
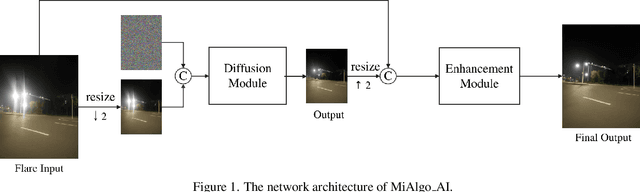
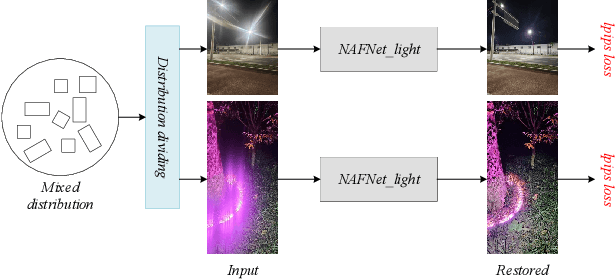
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Dynamic Dense Graph Convolutional Network for Skeleton-based Human Motion Prediction
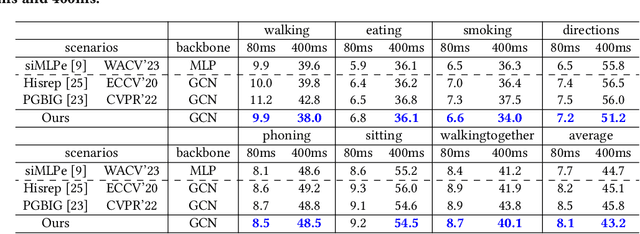
Nov 29, 2023Graph Convolutional Networks (GCN) which typically follows a neural message passing framework to model dependencies among skeletal joints has achieved high success in skeleton-based human motion prediction task. Nevertheless, how to construct a graph from a skeleton sequence and how to perform message passing on the graph are still open problems, which severely affect the performance of GCN. To solve both problems, this paper presents a Dynamic Dense Graph Convolutional Network (DD-GCN), which constructs a dense graph and implements an integrated dynamic message passing. More specifically, we construct a dense graph with 4D adjacency modeling as a comprehensive representation of motion sequence at different levels of abstraction. Based on the dense graph, we propose a dynamic message passing framework that learns dynamically from data to generate distinctive messages reflecting sample-specific relevance among nodes in the graph. Extensive experiments on benchmark Human 3.6M and CMU Mocap datasets verify the effectiveness of our DD-GCN which obviously outperforms state-of-the-art GCN-based methods, especially when using long-term and our proposed extremely long-term protocol.
Dynamic Compositional Graph Convolutional Network for Efficient Composite Human Motion Prediction
Nov 23, 2023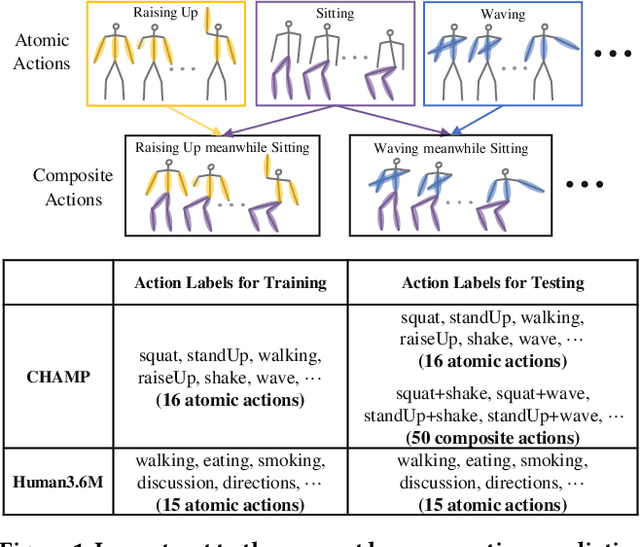
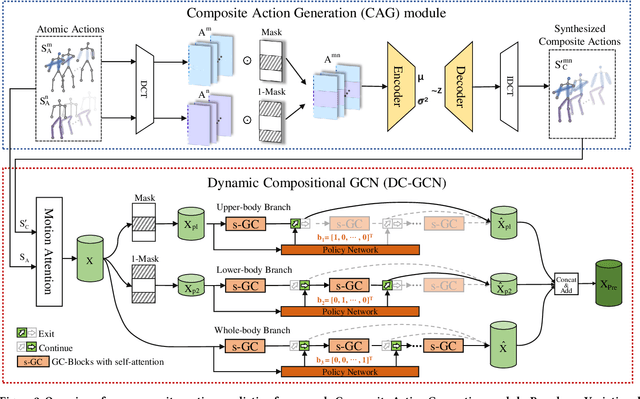
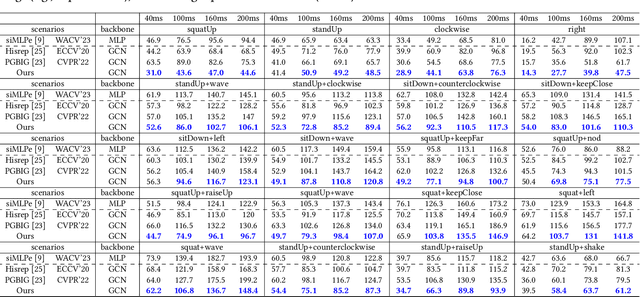
With potential applications in fields including intelligent surveillance and human-robot interaction, the human motion prediction task has become a hot research topic and also has achieved high success, especially using the recent Graph Convolutional Network (GCN). Current human motion prediction task usually focuses on predicting human motions for atomic actions. Observing that atomic actions can happen at the same time and thus formulating the composite actions, we propose the composite human motion prediction task. To handle this task, we first present a Composite Action Generation (CAG) module to generate synthetic composite actions for training, thus avoiding the laborious work of collecting composite action samples. Moreover, we alleviate the effect of composite actions on demand for a more complicated model by presenting a Dynamic Compositional Graph Convolutional Network (DC-GCN). Extensive experiments on the Human3.6M dataset and our newly collected CHAMP dataset consistently verify the efficiency of our DC-GCN method, which achieves state-of-the-art motion prediction accuracies and meanwhile needs few extra computational costs than traditional GCN-based human motion methods.