 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoPO: Incorporating Motion Prior for Occluded Human Mesh Recovery
May 11, 2026Although recent studies have made remarkable progress in human mesh recovery, they still exhibit limited robustness to occlusions and often produce inaccurate poses and severe motion jitter due to the insufficient spatial features for occluded body parts. Inspired by the rapid advancements in human motion prediction, we discover that compared to occluded image features, pose sequence inherently contains reliable motion prior for estimating occluded body parts. In this paper, we incorporate Motion Prior for Occluded human mesh recovery, called MoPO. Our MoPO mainly consists of two components: 1) The motion de-occlusion module, where we propose a spatial-temporal occlusion detector to detect joint visibility, and then we propose a lightweight motion predictor to complete the occluded body parts by predicting the most plausible joint positions based on history poses. 2) The motion-aware fusion and refinement module, which fuses the completed joint sequence with image features to estimate human shape and initial human pose. Moreover, the completed joint sequence is further used to refine the final human pose through inverse kinematics, which provides the occlusion-free motion prior for regressing human poses. Extensive experiments demonstrate that MoPO achieves state-of-the-art performance on both occlusion-specific and standard benchmarks, significantly enhancing the accuracy and temporal consistency of occluded human mesh recovery. Our code and demo can be found in the supplementary material.
UniMotion: A Unified Framework for Motion-Text-Vision Understanding and Generation
Mar 23, 2026We present UniMotion, to our knowledge the first unified framework for simultaneous understanding and generation of human motion, natural language, and RGB images within a single architecture. Existing unified models handle only restricted modality subsets (e.g., Motion-Text or static Pose-Image) and predominantly rely on discrete tokenization, which introduces quantization errors and disrupts temporal continuity. UniMotion overcomes both limitations through a core principle: treating motion as a first-class continuous modality on equal footing with RGB. A novel Cross-Modal Aligned Motion VAE (CMA-VAE) and symmetric dual-path embedders construct parallel continuous pathways for Motion and RGB within a shared LLM backbone. To inject visual-semantic priors into motion representations without requiring images at inference, we propose Dual-Posterior KL Alignment (DPA), which distills a vision-fused encoder's richer posterior into the motion-only encoder. To address the cold-start problem -- where text supervision alone is too sparse to calibrate the newly introduced motion pathway -- we further propose Latent Reconstruction Alignment (LRA), a self-supervised pre-training strategy that uses dense motion latents as unambiguous conditions to co-calibrate the embedder, backbone, and flow head, establishing a stable motion-aware foundation for all downstream tasks. UniMotion achieves state-of-the-art performance across seven tasks spanning any-to-any understanding, generation, and editing among the three modalities, with especially strong advantages on cross-modal compositional tasks.
Universal Skeleton Understanding via Differentiable Rendering and MLLMs
Mar 18, 2026Multimodal large language models (MLLMs) exhibit strong visual-language reasoning, yet remain confined to their native modalities and cannot directly process structured, non-visual data such as human skeletons. Existing methods either compress skeleton dynamics into lossy feature vectors for text alignment, or quantize motion into discrete tokens that generalize poorly across heterogeneous skeleton formats. We present SkeletonLLM, which achieves universal skeleton understanding by translating arbitrary skeleton sequences into the MLLM's native visual modality. At its core is DrAction, a differentiable, format-agnostic renderer that converts skeletal kinematics into compact image sequences. Because the pipeline is end-to-end differentiable, MLLM gradients can directly guide the rendering to produce task-informative visual tokens. To further enhance reasoning capabilities, we introduce a cooperative training strategy: Causal Reasoning Distillation transfers structured, step-by-step reasoning from a teacher model, while Discriminative Finetuning sharpens decision boundaries between confusable actions. SkeletonLLM demonstrates strong generalization on diverse tasks including recognition, captioning, reasoning, and cross-format transfer -- suggesting a viable path for applying MLLMs to non-native modalities. Code will be released upon acceptance.
Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
GCNext: Towards the Unity of Graph Convolutions for Human Motion Prediction
Dec 19, 2023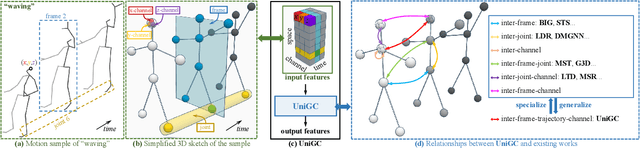
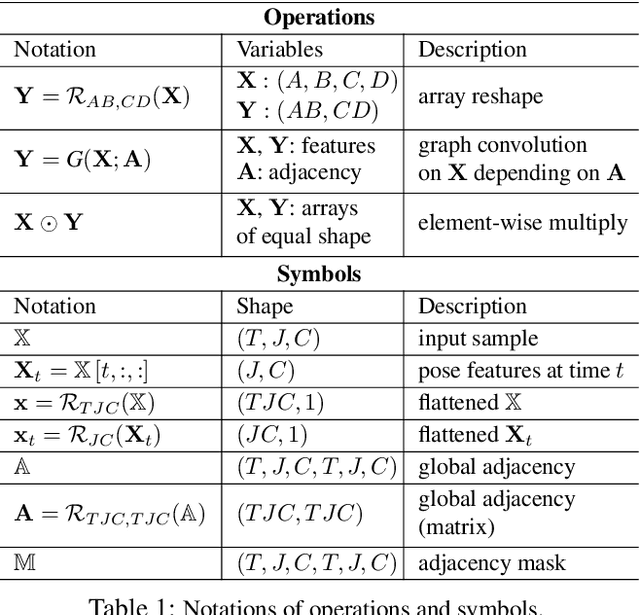
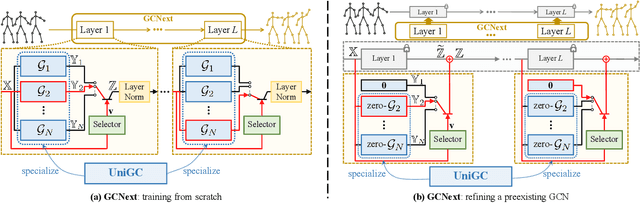
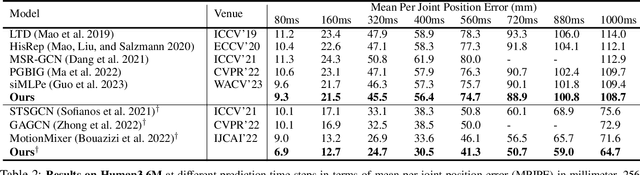
The past few years has witnessed the dominance of Graph Convolutional Networks (GCNs) over human motion prediction.Various styles of graph convolutions have been proposed, with each one meticulously designed and incorporated into a carefully-crafted network architecture. This paper breaks the limits of existing knowledge by proposing Universal Graph Convolution (UniGC), a novel graph convolution concept that re-conceptualizes different graph convolutions as its special cases. Leveraging UniGC on network-level, we propose GCNext, a novel GCN-building paradigm that dynamically determines the best-fitting graph convolutions both sample-wise and layer-wise. GCNext offers multiple use cases, including training a new GCN from scratch or refining a preexisting GCN. Experiments on Human3.6M, AMASS, and 3DPW datasets show that, by incorporating unique module-to-network designs, GCNext yields up to 9x lower computational cost than existing GCN methods, on top of achieving state-of-the-art performance.
Skeleton-in-Context: Unified Skeleton Sequence Modeling with In-Context Learning
Dec 06, 2023



In-context learning provides a new perspective for multi-task modeling for vision and NLP. Under this setting, the model can perceive tasks from prompts and accomplish them without any extra task-specific head predictions or model fine-tuning. However, Skeleton sequence modeling via in-context learning remains unexplored. Directly applying existing in-context models from other areas onto skeleton sequences fails due to the inter-frame and cross-task pose similarity that makes it outstandingly hard to perceive the task correctly from a subtle context. To address this challenge, we propose Skeleton-in-Context (SiC), an effective framework for in-context skeleton sequence modeling. Our SiC is able to handle multiple skeleton-based tasks simultaneously after a single training process and accomplish each task from context according to the given prompt. It can further generalize to new, unseen tasks according to customized prompts. To facilitate context perception, we additionally propose a task-unified prompt, which adaptively learns tasks of different natures, such as partial joint-level generation, sequence-level prediction, or 2D-to-3D motion prediction. We conduct extensive experiments to evaluate the effectiveness of our SiC on multiple tasks, including motion prediction, pose estimation, joint completion, and future pose estimation. We also evaluate its generalization capability on unseen tasks such as motion-in-between. These experiments show that our model achieves state-of-the-art multi-task performance and even outperforms single-task methods on certain tasks.
Dynamic Dense Graph Convolutional Network for Skeleton-based Human Motion Prediction
Nov 29, 2023Graph Convolutional Networks (GCN) which typically follows a neural message passing framework to model dependencies among skeletal joints has achieved high success in skeleton-based human motion prediction task. Nevertheless, how to construct a graph from a skeleton sequence and how to perform message passing on the graph are still open problems, which severely affect the performance of GCN. To solve both problems, this paper presents a Dynamic Dense Graph Convolutional Network (DD-GCN), which constructs a dense graph and implements an integrated dynamic message passing. More specifically, we construct a dense graph with 4D adjacency modeling as a comprehensive representation of motion sequence at different levels of abstraction. Based on the dense graph, we propose a dynamic message passing framework that learns dynamically from data to generate distinctive messages reflecting sample-specific relevance among nodes in the graph. Extensive experiments on benchmark Human 3.6M and CMU Mocap datasets verify the effectiveness of our DD-GCN which obviously outperforms state-of-the-art GCN-based methods, especially when using long-term and our proposed extremely long-term protocol.
Learning Snippet-to-Motion Progression for Skeleton-based Human Motion Prediction
Jul 26, 2023



Existing Graph Convolutional Networks to achieve human motion prediction largely adopt a one-step scheme, which output the prediction straight from history input, failing to exploit human motion patterns. We observe that human motions have transitional patterns and can be split into snippets representative of each transition. Each snippet can be reconstructed from its starting and ending poses referred to as the transitional poses. We propose a snippet-to-motion multi-stage framework that breaks motion prediction into sub-tasks easier to accomplish. Each sub-task integrates three modules: transitional pose prediction, snippet reconstruction, and snippet-to-motion prediction. Specifically, we propose to first predict only the transitional poses. Then we use them to reconstruct the corresponding snippets, obtaining a close approximation to the true motion sequence. Finally we refine them to produce the final prediction output. To implement the network, we propose a novel unified graph modeling, which allows for direct and effective feature propagation compared to existing approaches which rely on separate space-time modeling. Extensive experiments on Human 3.6M, CMU Mocap and 3DPW datasets verify the effectiveness of our method which achieves state-of-the-art performance.
A Mixer Layer is Worth One Graph Convolution: Unifying MLP-Mixers and GCNs for Human Motion Prediction
Apr 07, 2023



The past few years has witnessed the dominance of Graph Convolutional Networks (GCNs) over human motion prediction, while their performance is still far from satisfactory. Recently, MLP-Mixers show competitive results on top of being more efficient and simple. To extract features, GCNs typically follow an aggregate-and-update paradigm, while Mixers rely on token mixing and channel mixing operations. The two research paths have been independently established in the community. In this paper, we develop a novel perspective by unifying Mixers and GCNs. We show that a mixer layer can be seen as a graph convolutional layer applied to a fully-connected graph with parameterized adjacency. Extending this theoretical finding to the practical side, we propose Meta-Mixing Network (M$^2$-Net). Assisted with a novel zero aggregation operation, our network is capable of capturing both the structure-agnostic and the structure-sensitive dependencies in a collaborative manner. Not only is it computationally efficient, but most importantly, it also achieves state-of-the-art performance. An extensive evaluation on the Human3.6M, AMASS, and 3DPW datasets shows that M$^2$-Net consistently outperforms all other approaches. We hope our work brings the community one step further towards truly predictable human motion. Our code will be publicly available.