 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
Yan: Foundational Interactive Video Generation
Aug 13, 2025We present Yan, a foundational framework for interactive video generation, covering the entire pipeline from simulation and generation to editing. Specifically, Yan comprises three core modules. AAA-level Simulation: We design a highly-compressed, low-latency 3D-VAE coupled with a KV-cache-based shift-window denoising inference process, achieving real-time 1080P/60FPS interactive simulation. Multi-Modal Generation: We introduce a hierarchical autoregressive caption method that injects game-specific knowledge into open-domain multi-modal video diffusion models (VDMs), then transforming the VDM into a frame-wise, action-controllable, real-time infinite interactive video generator. Notably, when the textual and visual prompts are sourced from different domains, the model demonstrates strong generalization, allowing it to blend and compose the style and mechanics across domains flexibly according to user prompts. Multi-Granularity Editing: We propose a hybrid model that explicitly disentangles interactive mechanics simulation from visual rendering, enabling multi-granularity video content editing during interaction through text. Collectively, Yan offers an integration of these modules, pushing interactive video generation beyond isolated capabilities toward a comprehensive AI-driven interactive creation paradigm, paving the way for the next generation of creative tools, media, and entertainment. The project page is: https://greatx3.github.io/Yan/.
Playable Game Generation
Dec 01, 2024



In recent years, Artificial Intelligence Generated Content (AIGC) has advanced from text-to-image generation to text-to-video and multimodal video synthesis. However, generating playable games presents significant challenges due to the stringent requirements for real-time interaction, high visual quality, and accurate simulation of game mechanics. Existing approaches often fall short, either lacking real-time capabilities or failing to accurately simulate interactive mechanics. To tackle the playability issue, we propose a novel method called \emph{PlayGen}, which encompasses game data generation, an autoregressive DiT-based diffusion model, and a comprehensive playability-based evaluation framework. Validated on well-known 2D and 3D games, PlayGen achieves real-time interaction, ensures sufficient visual quality, and provides accurate interactive mechanics simulation. Notably, these results are sustained even after over 1000 frames of gameplay on an NVIDIA RTX 2060 GPU. Our code is publicly available: https://github.com/GreatX3/Playable-Game-Generation. Our playable demo generated by AI is: http://124.156.151.207.
Point-In-Context: Understanding Point Cloud via In-Context Learning
Apr 18, 2024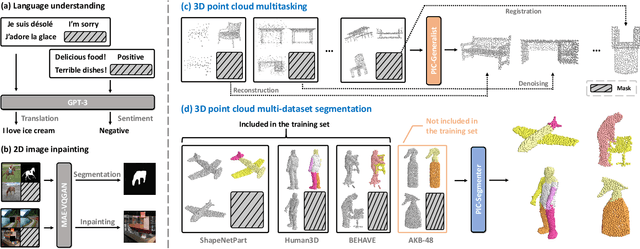
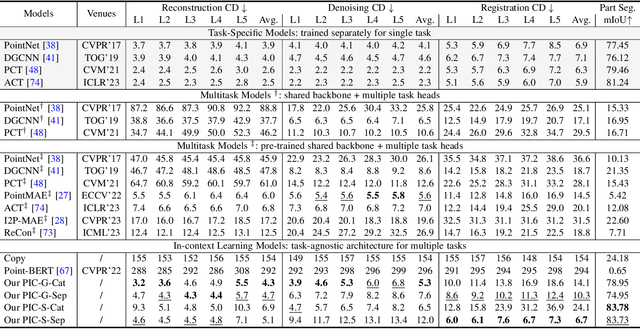
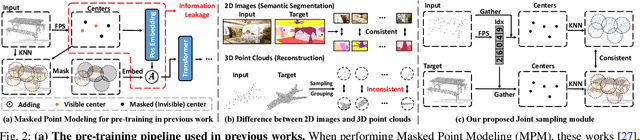
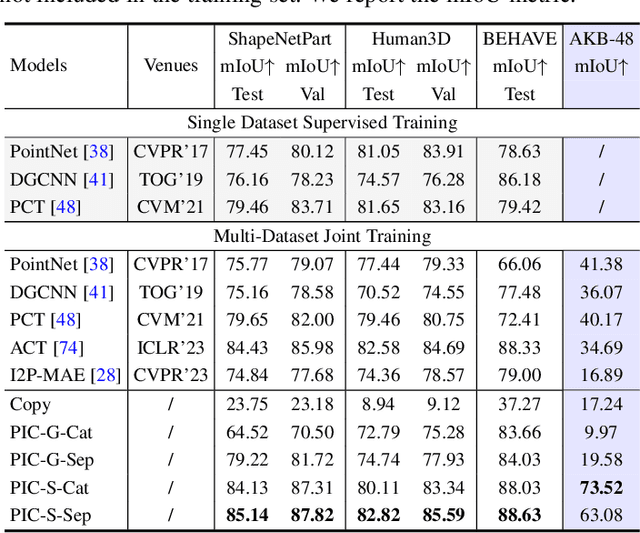
With the emergence of large-scale models trained on diverse datasets, in-context learning has emerged as a promising paradigm for multitasking, notably in natural language processing and image processing. However, its application in 3D point cloud tasks remains largely unexplored. In this work, we introduce Point-In-Context (PIC), a novel framework for 3D point cloud understanding via in-context learning. We address the technical challenge of effectively extending masked point modeling to 3D point clouds by introducing a Joint Sampling module and proposing a vanilla version of PIC called Point-In-Context-Generalist (PIC-G). PIC-G is designed as a generalist model for various 3D point cloud tasks, with inputs and outputs modeled as coordinates. In this paradigm, the challenging segmentation task is achieved by assigning label points with XYZ coordinates for each category; the final prediction is then chosen based on the label point closest to the predictions. To break the limitation by the fixed label-coordinate assignment, which has poor generalization upon novel classes, we propose two novel training strategies, In-Context Labeling and In-Context Enhancing, forming an extended version of PIC named Point-In-Context-Segmenter (PIC-S), targeting improving dynamic context labeling and model training. By utilizing dynamic in-context labels and extra in-context pairs, PIC-S achieves enhanced performance and generalization capability in and across part segmentation datasets. PIC is a general framework so that other tasks or datasets can be seamlessly introduced into our PIC through a unified data format. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks and segmenting multi-datasets. Our PIC-S is capable of generalizing unseen datasets and performing novel part segmentation by customizing prompts.
ModelNet-O: A Large-Scale Synthetic Dataset for Occlusion-Aware Point Cloud Classification
Jan 16, 2024



Recently, 3D point cloud classification has made significant progress with the help of many datasets. However, these datasets do not reflect the incomplete nature of real-world point clouds caused by occlusion, which limits the practical application of current methods. To bridge this gap, we propose ModelNet-O, a large-scale synthetic dataset of 123,041 samples that emulate real-world point clouds with self-occlusion caused by scanning from monocular cameras. ModelNet-O is 10 times larger than existing datasets and offers more challenging cases to evaluate the robustness of existing methods. Our observation on ModelNet-O reveals that well-designed sparse structures can preserve structural information of point clouds under occlusion, motivating us to propose a robust point cloud processing method that leverages a critical point sampling (CPS) strategy in a multi-level manner. We term our method PointMLS. Through extensive experiments, we demonstrate that our PointMLS achieves state-of-the-art results on ModelNet-O and competitive results on regular datasets, and it is robust and effective. More experiments also demonstrate the robustness and effectiveness of PointMLS.
Skeleton-in-Context: Unified Skeleton Sequence Modeling with In-Context Learning
Dec 06, 2023



In-context learning provides a new perspective for multi-task modeling for vision and NLP. Under this setting, the model can perceive tasks from prompts and accomplish them without any extra task-specific head predictions or model fine-tuning. However, Skeleton sequence modeling via in-context learning remains unexplored. Directly applying existing in-context models from other areas onto skeleton sequences fails due to the inter-frame and cross-task pose similarity that makes it outstandingly hard to perceive the task correctly from a subtle context. To address this challenge, we propose Skeleton-in-Context (SiC), an effective framework for in-context skeleton sequence modeling. Our SiC is able to handle multiple skeleton-based tasks simultaneously after a single training process and accomplish each task from context according to the given prompt. It can further generalize to new, unseen tasks according to customized prompts. To facilitate context perception, we additionally propose a task-unified prompt, which adaptively learns tasks of different natures, such as partial joint-level generation, sequence-level prediction, or 2D-to-3D motion prediction. We conduct extensive experiments to evaluate the effectiveness of our SiC on multiple tasks, including motion prediction, pose estimation, joint completion, and future pose estimation. We also evaluate its generalization capability on unseen tasks such as motion-in-between. These experiments show that our model achieves state-of-the-art multi-task performance and even outperforms single-task methods on certain tasks.
Explore In-Context Learning for 3D Point Cloud Understanding
Jun 14, 2023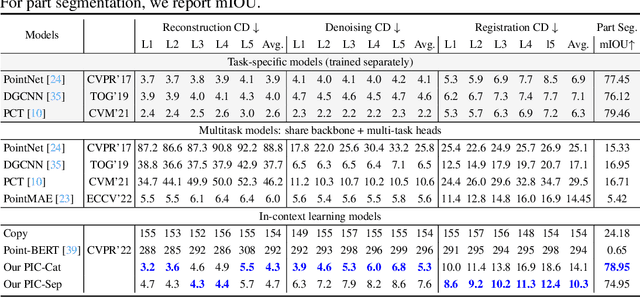

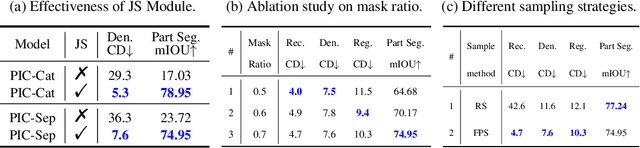

With the rise of large-scale models trained on broad data, in-context learning has become a new learning paradigm that has demonstrated significant potential in natural language processing and computer vision tasks. Meanwhile, in-context learning is still largely unexplored in the 3D point cloud domain. Although masked modeling has been successfully applied for in-context learning in 2D vision, directly extending it to 3D point clouds remains a formidable challenge. In the case of point clouds, the tokens themselves are the point cloud positions (coordinates) that are masked during inference. Moreover, position embedding in previous works may inadvertently introduce information leakage. To address these challenges, we introduce a novel framework, named Point-In-Context, designed especially for in-context learning in 3D point clouds, where both inputs and outputs are modeled as coordinates for each task. Additionally, we propose the Joint Sampling module, carefully designed to work in tandem with the general point sampling operator, effectively resolving the aforementioned technical issues. We conduct extensive experiments to validate the versatility and adaptability of our proposed methods in handling a wide range of tasks. Furthermore, with a more effective prompt selection strategy, our framework surpasses the results of individually trained models.