 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025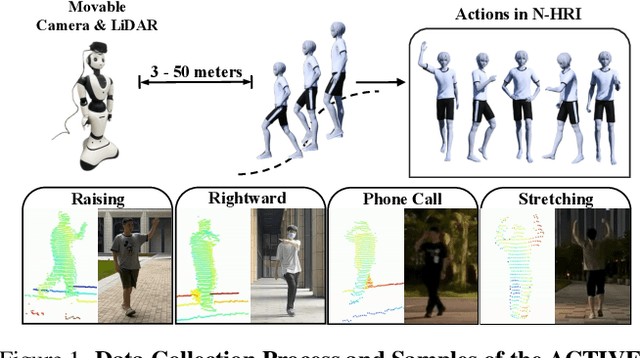
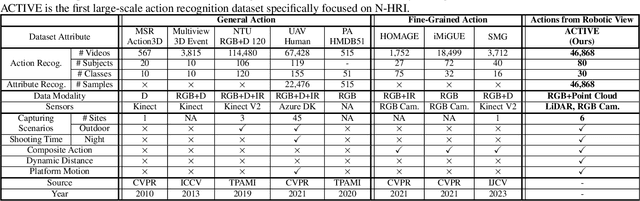

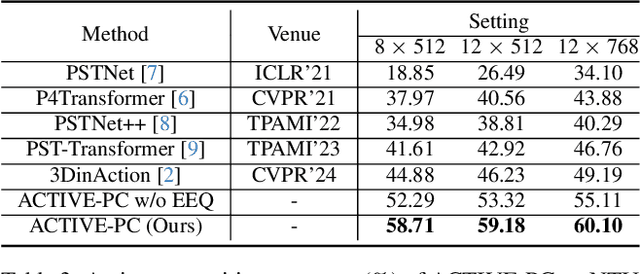
Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
VG4D: Vision-Language Model Goes 4D Video Recognition
Apr 17, 2024Understanding the real world through point cloud video is a crucial aspect of robotics and autonomous driving systems. However, prevailing methods for 4D point cloud recognition have limitations due to sensor resolution, which leads to a lack of detailed information. Recent advances have shown that Vision-Language Models (VLM) pre-trained on web-scale text-image datasets can learn fine-grained visual concepts that can be transferred to various downstream tasks. However, effectively integrating VLM into the domain of 4D point clouds remains an unresolved problem. In this work, we propose the Vision-Language Models Goes 4D (VG4D) framework to transfer VLM knowledge from visual-text pre-trained models to a 4D point cloud network. Our approach involves aligning the 4D encoder's representation with a VLM to learn a shared visual and text space from training on large-scale image-text pairs. By transferring the knowledge of the VLM to the 4D encoder and combining the VLM, our VG4D achieves improved recognition performance. To enhance the 4D encoder, we modernize the classic dynamic point cloud backbone and propose an improved version of PSTNet, im-PSTNet, which can efficiently model point cloud videos. Experiments demonstrate that our method achieves state-of-the-art performance for action recognition on both the NTU RGB+D 60 dataset and the NTU RGB+D 120 dataset. Code is available at \url{https://github.com/Shark0-0/VG4D}.