 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterSEED: Semantics-Structure Decoupling for Heterogeneous Graph Learning under Heterophily
May 06, 2026Many real-world heterogeneous graphs exhibit pronounced heterophily, where connected nodes often have dissimilar labels or play different semantic roles. In such settings, standard heterogeneous graph neural networks that aggregate messages along metapaths or meta-relations primarily based on feature similarity can propagate misleading information, since feature similarity may be misaligned with underlying relational semantics. In this paper, we propose HeterSEED, a semantics-structure decoupling framework for heterogeneous graph learning under heterophily. HeterSEED decouples representation learning into a heterogeneous semantic channel that captures type- and relation-aware local semantics and a structure-aware heterophily channel that separates homophilic and heterophilic neighborhoods via pseudo-label-guided partitioning and aggregates them using metapath-based structural weights. A node-level adaptive fusion mechanism then combines the two channels to produce context-dependent node representations. Theoretically, we establish that, on heterogeneous graphs under heterophily, HeterSEED is strictly more expressive than standard heterogeneous graph neural networks that rely primarily on feature similarity and provably reduces the prediction bias introduced by heterophilic neighbors. Experiments on five real-world heterogeneous graphs, including two large-scale networks at the million-node and hundred-million-edge scale, demonstrate that HeterSEED consistently outperforms representative heterogeneous graph neural networks and recent heterophily-aware baselines, especially in strongly heterophilic regimes.
Decentralized Optimization on Compact Submanifolds by Quantized Riemannian Gradient Tracking
Jun 09, 2025This paper considers the problem of decentralized optimization on compact submanifolds, where a finite sum of smooth (possibly non-convex) local functions is minimized by $n$ agents forming an undirected and connected graph. However, the efficiency of distributed optimization is often hindered by communication bottlenecks. To mitigate this, we propose the Quantized Riemannian Gradient Tracking (Q-RGT) algorithm, where agents update their local variables using quantized gradients. The introduction of quantization noise allows our algorithm to bypass the constraints of the accurate Riemannian projection operator (such as retraction), further improving iterative efficiency. To the best of our knowledge, this is the first algorithm to achieve an $\mathcal{O}(1/K)$ convergence rate in the presence of quantization, matching the convergence rate of methods without quantization. Additionally, we explicitly derive lower bounds on decentralized consensus associated with a function of quantization levels. Numerical experiments demonstrate that Q-RGT performs comparably to non-quantized methods while reducing communication bottlenecks and computational overhead.
Out-of-Distribution Detection on Graphs: A Survey
Feb 12, 2025Graph machine learning has witnessed rapid growth, driving advancements across diverse domains. However, the in-distribution assumption, where training and testing data share the same distribution, often breaks in real-world scenarios, leading to degraded model performance under distribution shifts. This challenge has catalyzed interest in graph out-of-distribution (GOOD) detection, which focuses on identifying graph data that deviates from the distribution seen during training, thereby enhancing model robustness. In this paper, we provide a rigorous definition of GOOD detection and systematically categorize existing methods into four types: enhancement-based, reconstruction-based, information propagation-based, and classification-based approaches. We analyze the principles and mechanisms of each approach and clarify the distinctions between GOOD detection and related fields, such as graph anomaly detection, outlier detection, and GOOD generalization. Beyond methodology, we discuss practical applications and theoretical foundations, highlighting the unique challenges posed by graph data. Finally, we discuss the primary challenges and propose future directions to advance this emerging field. The repository of this survey is available at https://github.com/ca1man-2022/Awesome-GOOD-Detection.
A New Formulation of Lipschitz Constrained With Functional Gradient Learning for GANs
Jan 20, 2025This paper introduces a promising alternative method for training Generative Adversarial Networks (GANs) on large-scale datasets with clear theoretical guarantees. GANs are typically learned through a minimax game between a generator and a discriminator, which is known to be empirically unstable. Previous learning paradigms have encountered mode collapse issues without a theoretical solution. To address these challenges, we propose a novel Lipschitz-constrained Functional Gradient GANs learning (Li-CFG) method to stabilize the training of GAN and provide a theoretical foundation for effectively increasing the diversity of synthetic samples by reducing the neighborhood size of the latent vector. Specifically, we demonstrate that the neighborhood size of the latent vector can be reduced by increasing the norm of the discriminator gradient, resulting in enhanced diversity of synthetic samples. To efficiently enlarge the norm of the discriminator gradient, we introduce a novel {\epsilon}-centered gradient penalty that amplifies the norm of the discriminator gradient using the hyper-parameter {\epsilon}. In comparison to other constraints, our method enlarging the discriminator norm, thus obtaining the smallest neighborhood size of the latent vector. Extensive experiments on benchmark datasets for image generation demonstrate the efficacy of the Li-CFG method and the {\epsilon}-centered gradient penalty. The results showcase improved stability and increased diversity of synthetic samples.
Nested Annealed Training Scheme for Generative Adversarial Networks
Jan 20, 2025Recently, researchers have proposed many deep generative models, including generative adversarial networks(GANs) and denoising diffusion models. Although significant breakthroughs have been made and empirical success has been achieved with the GAN, its mathematical underpinnings remain relatively unknown. This paper focuses on a rigorous mathematical theoretical framework: the composite-functional-gradient GAN (CFG)[1]. Specifically, we reveal the theoretical connection between the CFG model and score-based models. We find that the training objective of the CFG discriminator is equivalent to finding an optimal D(x). The optimal gradient of D(x) differentiates the integral of the differences between the score functions of real and synthesized samples. Conversely, training the CFG generator involves finding an optimal G(x) that minimizes this difference. In this paper, we aim to derive an annealed weight preceding the weight of the CFG discriminator. This new explicit theoretical explanation model is called the annealed CFG method. To overcome the limitation of the annealed CFG method, as the method is not readily applicable to the SOTA GAN model, we propose a nested annealed training scheme (NATS). This scheme keeps the annealed weight from the CFG method and can be seamlessly adapted to various GAN models, no matter their structural, loss, or regularization differences. We conduct thorough experimental evaluations on various benchmark datasets for image generation. The results show that our annealed CFG and NATS methods significantly improve the quality and diversity of the synthesized samples. This improvement is clear when comparing the CFG method and the SOTA GAN models.
TcGAN: Semantic-Aware and Structure-Preserved GANs with Individual Vision Transformer for Fast Arbitrary One-Shot Image Generation
Feb 16, 2023



One-shot image generation (OSG) with generative adversarial networks that learn from the internal patches of a given image has attracted world wide attention. In recent studies, scholars have primarily focused on extracting features of images from probabilistically distributed inputs with pure convolutional neural networks (CNNs). However, it is quite difficult for CNNs with limited receptive domain to extract and maintain the global structural information. Therefore, in this paper, we propose a novel structure-preserved method TcGAN with individual vision transformer to overcome the shortcomings of the existing one-shot image generation methods. Specifically, TcGAN preserves global structure of an image during training to be compatible with local details while maintaining the integrity of semantic-aware information by exploiting the powerful long-range dependencies modeling capability of the transformer. We also propose a new scaling formula having scale-invariance during the calculation period, which effectively improves the generated image quality of the OSG model on image super-resolution tasks. We present the design of the TcGAN converter framework, comprehensive experimental as well as ablation studies demonstrating the ability of TcGAN to achieve arbitrary image generation with the fastest running time. Lastly, TcGAN achieves the most excellent performance in terms of applying it to other image processing tasks, e.g., super-resolution as well as image harmonization, the results further prove its superiority.
Fuzzy Knowledge Distillation from High-Order TSK to Low-Order TSK
Feb 16, 2023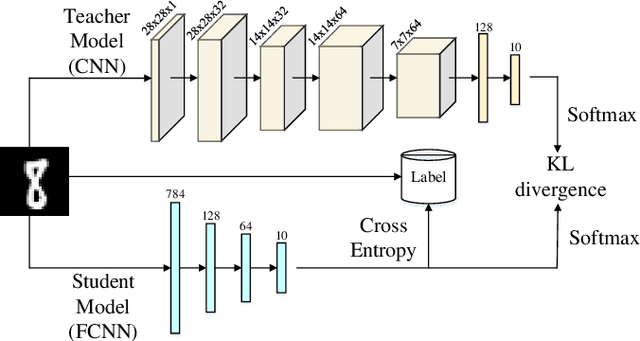
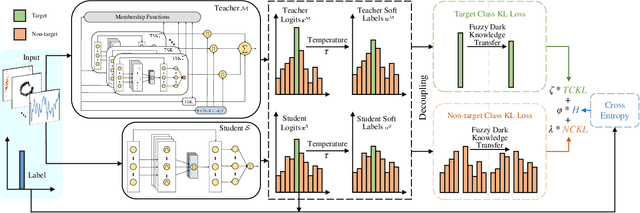
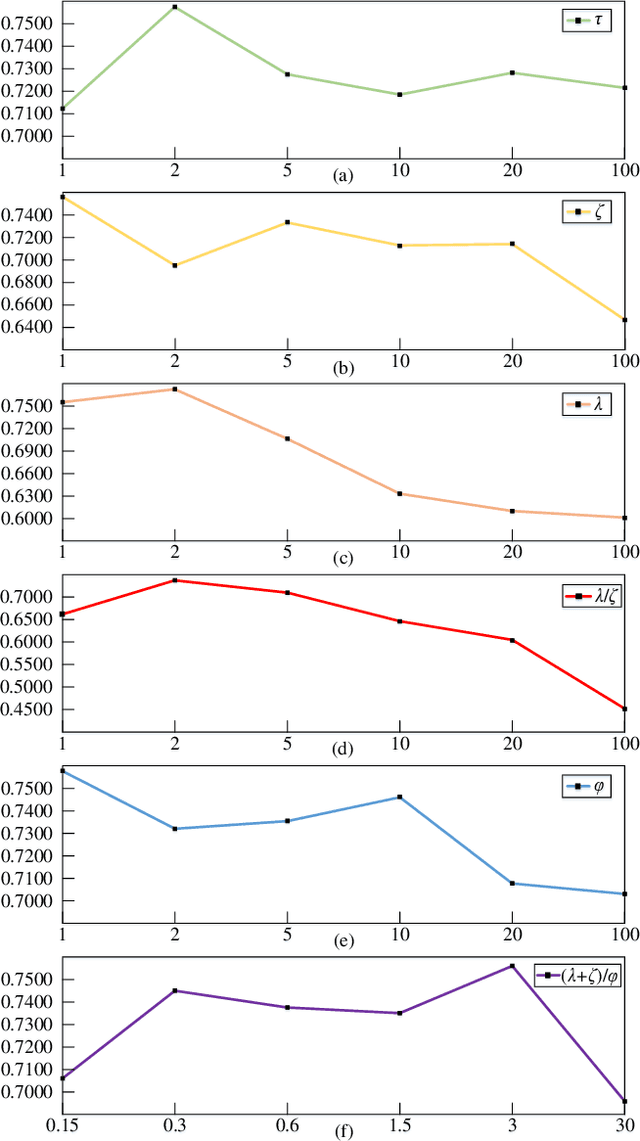

High-order Takagi-Sugeno-Kang (TSK) fuzzy classifiers possess powerful classification performance yet have fewer fuzzy rules, but always be impaired by its exponential growth training time and poorer interpretability owing to High-order polynomial used in consequent part of fuzzy rule, while Low-order TSK fuzzy classifiers run quickly with high interpretability, however they usually require more fuzzy rules and perform relatively not very well. Address this issue, a novel TSK fuzzy classifier embeded with knowledge distillation in deep learning called HTSK-LLM-DKD is proposed in this study. HTSK-LLM-DKD achieves the following distinctive characteristics: 1) It takes High-order TSK classifier as teacher model and Low-order TSK fuzzy classifier as student model, and leverages the proposed LLM-DKD (Least Learning Machine based Decoupling Knowledge Distillation) to distill the fuzzy dark knowledge from High-order TSK fuzzy classifier to Low-order TSK fuzzy classifier, which resulting in Low-order TSK fuzzy classifier endowed with enhanced performance surpassing or at least comparable to High-order TSK classifier, as well as high interpretability; specifically 2) The Negative Euclidean distance between the output of teacher model and each class is employed to obtain the teacher logits, and then it compute teacher/student soft labels by the softmax function with distillating temperature parameter; 3) By reformulating the Kullback-Leibler divergence, it decouples fuzzy dark knowledge into target class knowledge and non-target class knowledge, and transfers them to student model. The advantages of HTSK-LLM-DKD are verified on the benchmarking UCI datasets and a real dataset Cleveland heart disease, in terms of classification performance and model interpretability.
Mask-Guided Image Person Removal with Data Synthesis
Sep 29, 2022
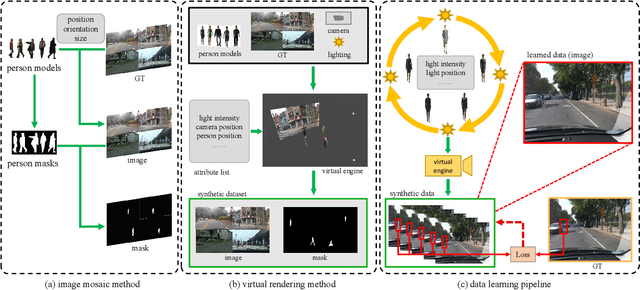
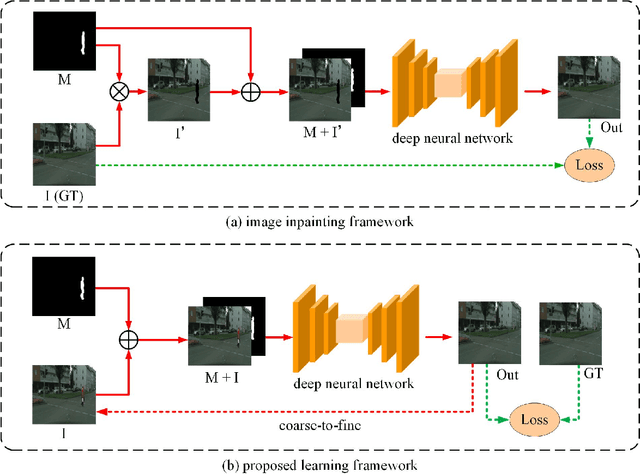

As a special case of common object removal, image person removal is playing an increasingly important role in social media and criminal investigation domains. Due to the integrity of person area and the complexity of human posture, person removal has its own dilemmas. In this paper, we propose a novel idea to tackle these problems from the perspective of data synthesis. Concerning the lack of dedicated dataset for image person removal, two dataset production methods are proposed to automatically generate images, masks and ground truths respectively. Then, a learning framework similar to local image degradation is proposed so that the masks can be used to guide the feature extraction process and more texture information can be gathered for final prediction. A coarse-to-fine training strategy is further applied to refine the details. The data synthesis and learning framework combine well with each other. Experimental results verify the effectiveness of our method quantitatively and qualitatively, and the trained network proves to have good generalization ability either on real or synthetic images.
APB2FaceV2: Real-Time Audio-Guided Multi-Face Reenactment
Oct 25, 2020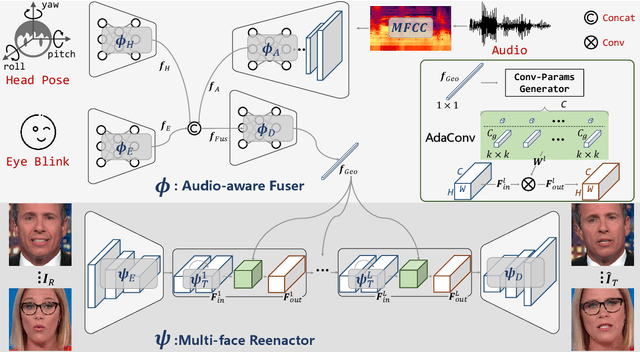
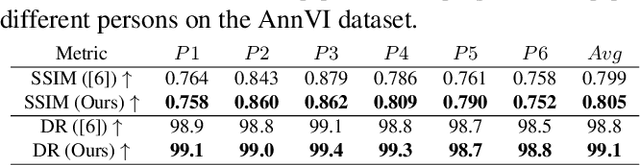


Audio-guided face reenactment aims to generate a photorealistic face that has matched facial expression with the input audio. However, current methods can only reenact a special person once the model is trained or need extra operations such as 3D rendering and image post-fusion on the premise of generating vivid faces. To solve the above challenge, we propose a novel \emph{R}eal-time \emph{A}udio-guided \emph{M}ulti-face reenactment approach named \emph{APB2FaceV2}, which can reenact different target faces among multiple persons with corresponding reference face and drive audio signal as inputs. Enabling the model to be trained end-to-end and have a faster speed, we design a novel module named Adaptive Convolution (AdaConv) to infuse audio information into the network, as well as adopt a lightweight network as our backbone so that the network can run in real time on CPU and GPU. Comparison experiments prove the superiority of our approach than existing state-of-the-art methods, and further experiments demonstrate that our method is efficient and flexible for practical applications https://github.com/zhangzjn/APB2FaceV2
DTVNet: Dynamic Time-lapse Video Generation via Single Still Image
Aug 11, 2020

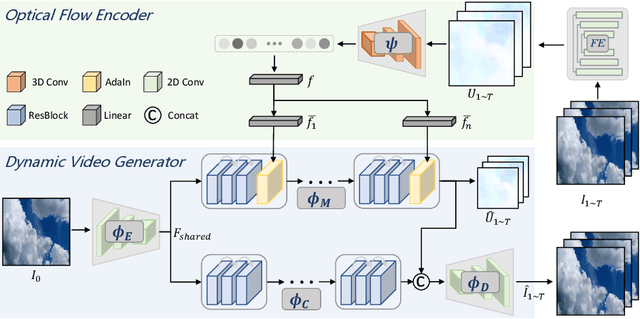
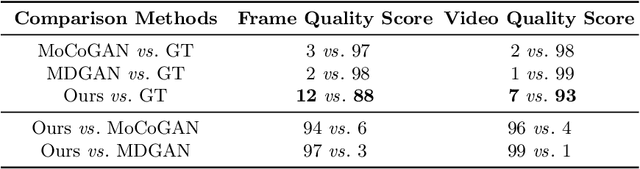
This paper presents a novel end-to-end dynamic time-lapse video generation framework, named DTVNet, to generate diversified time-lapse videos from a single landscape image, which are conditioned on normalized motion vectors. The proposed DTVNet consists of two submodules: \emph{Optical Flow Encoder} (OFE) and \emph{Dynamic Video Generator} (DVG). The OFE maps a sequence of optical flow maps to a \emph{normalized motion vector} that encodes the motion information inside the generated video. The DVG contains motion and content streams that learn from the motion vector and the single image respectively, as well as an encoder and a decoder to learn shared content features and construct video frames with corresponding motion respectively. Specifically, the \emph{motion stream} introduces multiple \emph{adaptive instance normalization} (AdaIN) layers to integrate multi-level motion information that are processed by linear layers. In the testing stage, videos with the same content but various motion information can be generated by different \emph{normalized motion vectors} based on only one input image. We further conduct experiments on Sky Time-lapse dataset, and the results demonstrate the superiority of our approach over the state-of-the-art methods for generating high-quality and dynamic videos, as well as the variety for generating videos with various motion information.