 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTcGAN: Semantic-Aware and Structure-Preserved GANs with Individual Vision Transformer for Fast Arbitrary One-Shot Image Generation
Feb 16, 2023



One-shot image generation (OSG) with generative adversarial networks that learn from the internal patches of a given image has attracted world wide attention. In recent studies, scholars have primarily focused on extracting features of images from probabilistically distributed inputs with pure convolutional neural networks (CNNs). However, it is quite difficult for CNNs with limited receptive domain to extract and maintain the global structural information. Therefore, in this paper, we propose a novel structure-preserved method TcGAN with individual vision transformer to overcome the shortcomings of the existing one-shot image generation methods. Specifically, TcGAN preserves global structure of an image during training to be compatible with local details while maintaining the integrity of semantic-aware information by exploiting the powerful long-range dependencies modeling capability of the transformer. We also propose a new scaling formula having scale-invariance during the calculation period, which effectively improves the generated image quality of the OSG model on image super-resolution tasks. We present the design of the TcGAN converter framework, comprehensive experimental as well as ablation studies demonstrating the ability of TcGAN to achieve arbitrary image generation with the fastest running time. Lastly, TcGAN achieves the most excellent performance in terms of applying it to other image processing tasks, e.g., super-resolution as well as image harmonization, the results further prove its superiority.
Fuzzy Knowledge Distillation from High-Order TSK to Low-Order TSK
Feb 16, 2023
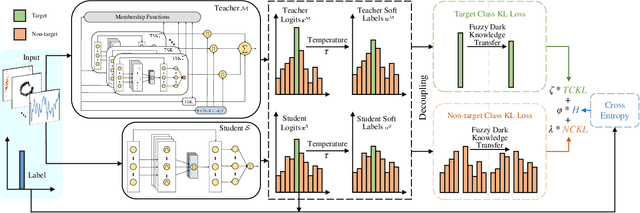

High-order Takagi-Sugeno-Kang (TSK) fuzzy classifiers possess powerful classification performance yet have fewer fuzzy rules, but always be impaired by its exponential growth training time and poorer interpretability owing to High-order polynomial used in consequent part of fuzzy rule, while Low-order TSK fuzzy classifiers run quickly with high interpretability, however they usually require more fuzzy rules and perform relatively not very well. Address this issue, a novel TSK fuzzy classifier embeded with knowledge distillation in deep learning called HTSK-LLM-DKD is proposed in this study. HTSK-LLM-DKD achieves the following distinctive characteristics: 1) It takes High-order TSK classifier as teacher model and Low-order TSK fuzzy classifier as student model, and leverages the proposed LLM-DKD (Least Learning Machine based Decoupling Knowledge Distillation) to distill the fuzzy dark knowledge from High-order TSK fuzzy classifier to Low-order TSK fuzzy classifier, which resulting in Low-order TSK fuzzy classifier endowed with enhanced performance surpassing or at least comparable to High-order TSK classifier, as well as high interpretability; specifically 2) The Negative Euclidean distance between the output of teacher model and each class is employed to obtain the teacher logits, and then it compute teacher/student soft labels by the softmax function with distillating temperature parameter; 3) By reformulating the Kullback-Leibler divergence, it decouples fuzzy dark knowledge into target class knowledge and non-target class knowledge, and transfers them to student model. The advantages of HTSK-LLM-DKD are verified on the benchmarking UCI datasets and a real dataset Cleveland heart disease, in terms of classification performance and model interpretability.