 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Knowledge Distillation from High-Order TSK to Low-Order TSK
Feb 16, 2023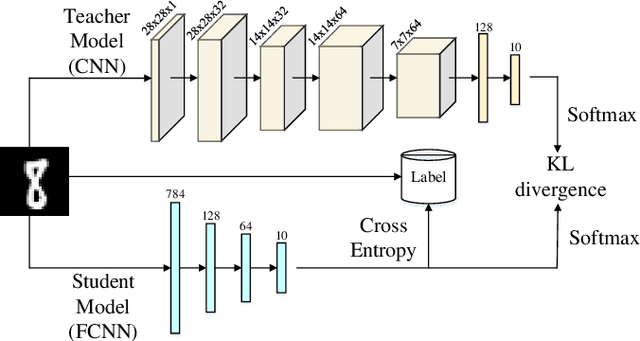
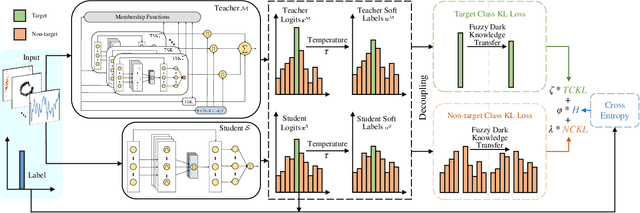

High-order Takagi-Sugeno-Kang (TSK) fuzzy classifiers possess powerful classification performance yet have fewer fuzzy rules, but always be impaired by its exponential growth training time and poorer interpretability owing to High-order polynomial used in consequent part of fuzzy rule, while Low-order TSK fuzzy classifiers run quickly with high interpretability, however they usually require more fuzzy rules and perform relatively not very well. Address this issue, a novel TSK fuzzy classifier embeded with knowledge distillation in deep learning called HTSK-LLM-DKD is proposed in this study. HTSK-LLM-DKD achieves the following distinctive characteristics: 1) It takes High-order TSK classifier as teacher model and Low-order TSK fuzzy classifier as student model, and leverages the proposed LLM-DKD (Least Learning Machine based Decoupling Knowledge Distillation) to distill the fuzzy dark knowledge from High-order TSK fuzzy classifier to Low-order TSK fuzzy classifier, which resulting in Low-order TSK fuzzy classifier endowed with enhanced performance surpassing or at least comparable to High-order TSK classifier, as well as high interpretability; specifically 2) The Negative Euclidean distance between the output of teacher model and each class is employed to obtain the teacher logits, and then it compute teacher/student soft labels by the softmax function with distillating temperature parameter; 3) By reformulating the Kullback-Leibler divergence, it decouples fuzzy dark knowledge into target class knowledge and non-target class knowledge, and transfers them to student model. The advantages of HTSK-LLM-DKD are verified on the benchmarking UCI datasets and a real dataset Cleveland heart disease, in terms of classification performance and model interpretability.
A Survey on Soft Subspace Clustering
Apr 08, 2016
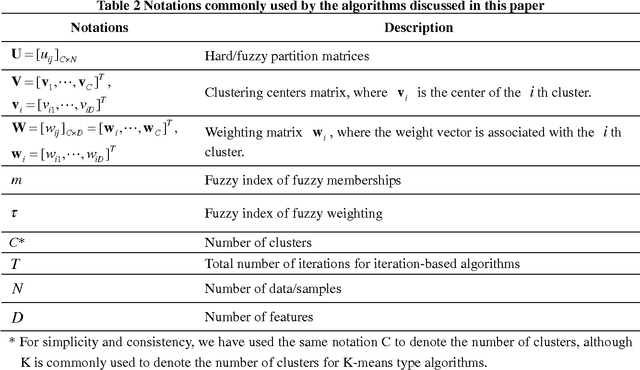


Subspace clustering (SC) is a promising clustering technology to identify clusters based on their associations with subspaces in high dimensional spaces. SC can be classified into hard subspace clustering (HSC) and soft subspace clustering (SSC). While HSC algorithms have been extensively studied and well accepted by the scientific community, SSC algorithms are relatively new but gaining more attention in recent years due to better adaptability. In the paper, a comprehensive survey on existing SSC algorithms and the recent development are presented. The SSC algorithms are classified systematically into three main categories, namely, conventional SSC (CSSC), independent SSC (ISSC) and extended SSC (XSSC). The characteristics of these algorithms are highlighted and the potential future development of SSC is also discussed.
Transfer Prototype-based Fuzzy Clustering
Apr 05, 2016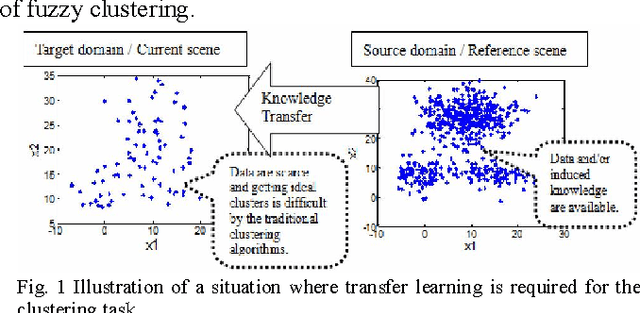
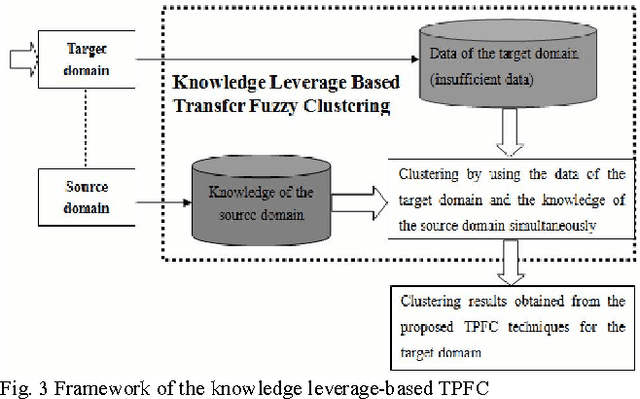
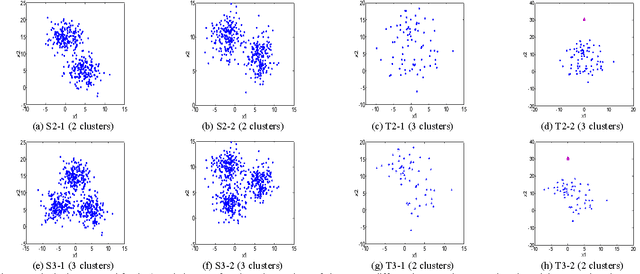
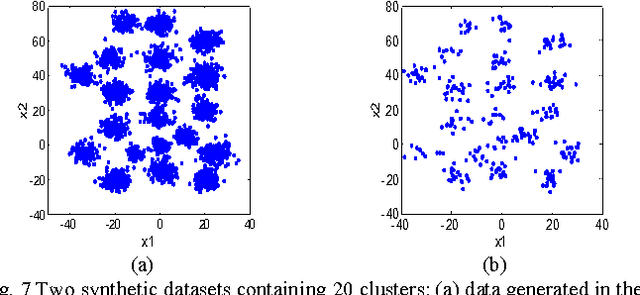
The traditional prototype based clustering methods, such as the well-known fuzzy c-mean (FCM) algorithm, usually need sufficient data to find a good clustering partition. If the available data is limited or scarce, most of the existing prototype based clustering algorithms will no longer be effective. While the data for the current clustering task may be scarce, there is usually some useful knowledge available in the related scenes/domains. In this study, the concept of transfer learning is applied to prototype based fuzzy clustering (PFC). Specifically, the idea of leveraging knowledge from the source domain is exploited to develop a set of transfer prototype based fuzzy clustering (TPFC) algorithms. Three prototype based fuzzy clustering algorithms, namely, FCM, fuzzy k-plane clustering (FKPC) and fuzzy subspace clustering (FSC), have been chosen to incorporate with knowledge leveraging mechanism to develop the corresponding transfer clustering algorithms. Novel objective functions are proposed to integrate the knowledge of source domain with the data of target domain for clustering in the target domain. The proposed algorithms have been validated on different synthetic and real-world datasets and the results demonstrate their effectiveness when compared with both the original prototype based fuzzy clustering algorithms and the related clustering algorithms like multi-task clustering and co-clustering.