 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-Aware Contrastive Learning for Noisy Time Series
Jun 07, 2024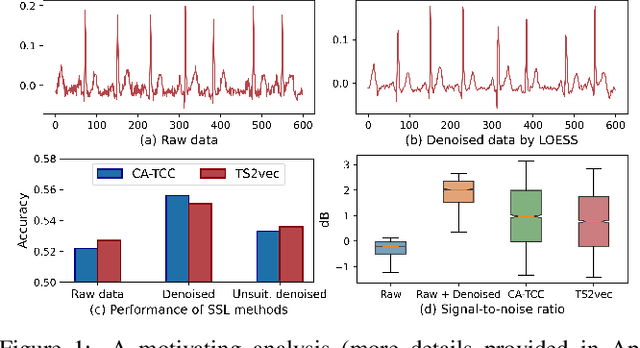



Time series self-supervised learning (SSL) aims to exploit unlabeled data for pre-training to mitigate the reliance on labels. Despite the great success in recent years, there is limited discussion on the potential noise in the time series, which can severely impair the performance of existing SSL methods. To mitigate the noise, the de facto strategy is to apply conventional denoising methods before model training. However, this pre-processing approach may not fully eliminate the effect of noise in SSL for two reasons: (i) the diverse types of noise in time series make it difficult to automatically determine suitable denoising methods; (ii) noise can be amplified after mapping raw data into latent space. In this paper, we propose denoising-aware contrastive learning (DECL), which uses contrastive learning objectives to mitigate the noise in the representation and automatically selects suitable denoising methods for every sample. Extensive experiments on various datasets verify the effectiveness of our method. The code is open-sourced.
Improving Generalizability of Graph Anomaly Detection Models via Data Augmentation
Jun 18, 2023Graph anomaly detection (GAD) is a vital task since even a few anomalies can pose huge threats to benign users. Recent semi-supervised GAD methods, which can effectively leverage the available labels as prior knowledge, have achieved superior performances than unsupervised methods. In practice, people usually need to identify anomalies on new (sub)graphs to secure their business, but they may lack labels to train an effective detection model. One natural idea is to directly adopt a trained GAD model to the new (sub)graph for testing. However, we find that existing semi-supervised GAD methods suffer from poor generalization issue, i.e., well-trained models could not perform well on an unseen area (i.e., not accessible in training) of the same graph. It may cause great troubles. In this paper, we base on the phenomenon and propose a general and novel research problem of generalized graph anomaly detection that aims to effectively identify anomalies on both the training-domain graph and unseen testing graph to eliminate potential dangers. Nevertheless, it is a challenging task since only limited labels are available, and the normal background may differ between training and testing data. Accordingly, we propose a data augmentation method named \textit{AugAN} (\uline{Aug}mentation for \uline{A}nomaly and \uline{N}ormal distributions) to enrich training data and boost the generalizability of GAD models. Experiments verify the effectiveness of our method in improving model generalizability.
* Accepted to IEEE Transactions on Knowledge and Data Engineering (TKDE). arXiv admin note: substantial text overlap with arXiv:2209.10168
Adaptation-Agnostic Meta-Training
Aug 24, 2021


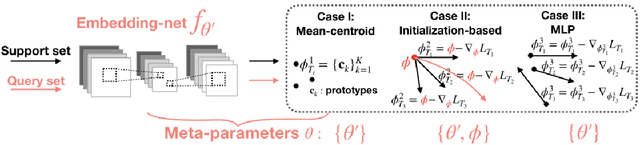
Many meta-learning algorithms can be formulated into an interleaved process, in the sense that task-specific predictors are learned during inner-task adaptation and meta-parameters are updated during meta-update. The normal meta-training strategy needs to differentiate through the inner-task adaptation procedure to optimize the meta-parameters. This leads to a constraint that the inner-task algorithms should be solved analytically. Under this constraint, only simple algorithms with analytical solutions can be applied as the inner-task algorithms, limiting the model expressiveness. To lift the limitation, we propose an adaptation-agnostic meta-training strategy. Following our proposed strategy, we can apply stronger algorithms (e.g., an ensemble of different types of algorithms) as the inner-task algorithm to achieve superior performance comparing with popular baselines. The source code is available at https://github.com/jiaxinchen666/AdaptationAgnosticMetaLearning.
Deep Network Embedding for Graph Representation Learning in Signed Networks
Jan 07, 2019



Network embedding has attracted an increasing attention over the past few years. As an effective approach to solve graph mining problems, network embedding aims to learn a low-dimensional feature vector representation for each node of a given network. The vast majority of existing network embedding algorithms, however, are only designed for unsigned networks, and the signed networks containing both positive and negative links, have pretty distinct properties from the unsigned counterpart. In this paper, we propose a deep network embedding model to learn the low-dimensional node vector representations with structural balance preservation for the signed networks. The model employs a semi-supervised stacked auto-encoder to reconstruct the adjacency connections of a given signed network. As the adjacency connections are overwhelmingly positive in the real-world signed networks, we impose a larger penalty to make the auto-encoder focus more on reconstructing the scarce negative links than the abundant positive links. In addition, to preserve the structural balance property of signed networks, we design the pairwise constraints to make the positively connected nodes much closer than the negatively connected nodes in the embedding space. Based on the network representations learned by the proposed model, we conduct link sign prediction and community detection in signed networks. Extensive experimental results in real-world datasets demonstrate the superiority of the proposed model over the state-of-the-art network embedding algorithms for graph representation learning in signed networks.
Transfer Prototype-based Fuzzy Clustering
Apr 05, 2016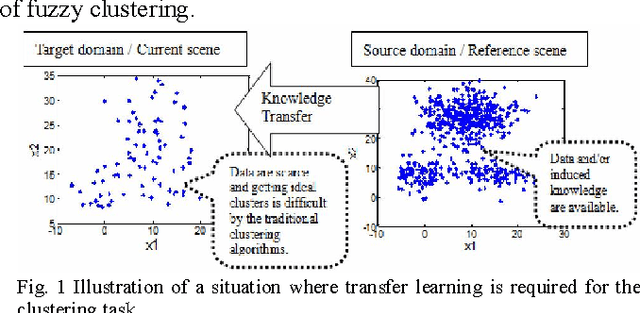
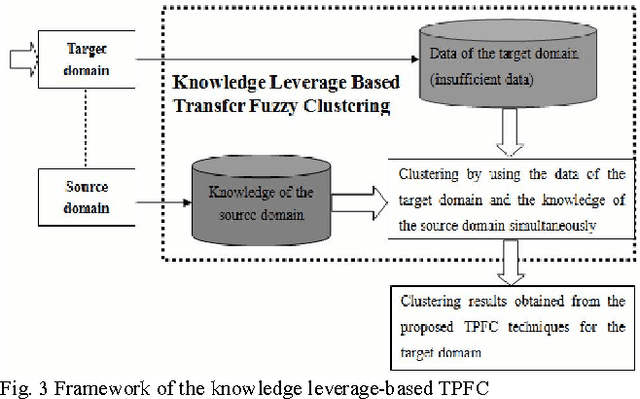
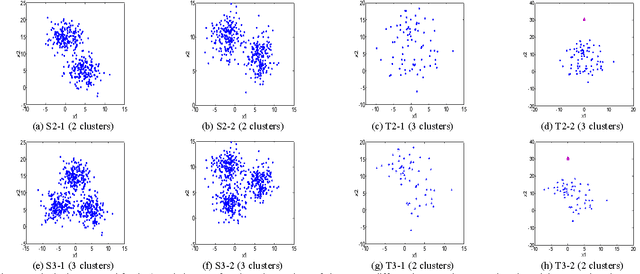
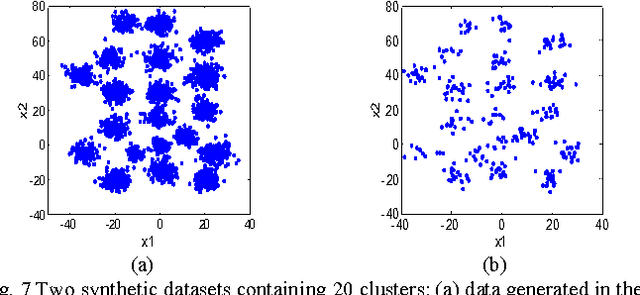
The traditional prototype based clustering methods, such as the well-known fuzzy c-mean (FCM) algorithm, usually need sufficient data to find a good clustering partition. If the available data is limited or scarce, most of the existing prototype based clustering algorithms will no longer be effective. While the data for the current clustering task may be scarce, there is usually some useful knowledge available in the related scenes/domains. In this study, the concept of transfer learning is applied to prototype based fuzzy clustering (PFC). Specifically, the idea of leveraging knowledge from the source domain is exploited to develop a set of transfer prototype based fuzzy clustering (TPFC) algorithms. Three prototype based fuzzy clustering algorithms, namely, FCM, fuzzy k-plane clustering (FKPC) and fuzzy subspace clustering (FSC), have been chosen to incorporate with knowledge leveraging mechanism to develop the corresponding transfer clustering algorithms. Novel objective functions are proposed to integrate the knowledge of source domain with the data of target domain for clustering in the target domain. The proposed algorithms have been validated on different synthetic and real-world datasets and the results demonstrate their effectiveness when compared with both the original prototype based fuzzy clustering algorithms and the related clustering algorithms like multi-task clustering and co-clustering.