 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPB2FaceV2: Real-Time Audio-Guided Multi-Face Reenactment
Paper and Code
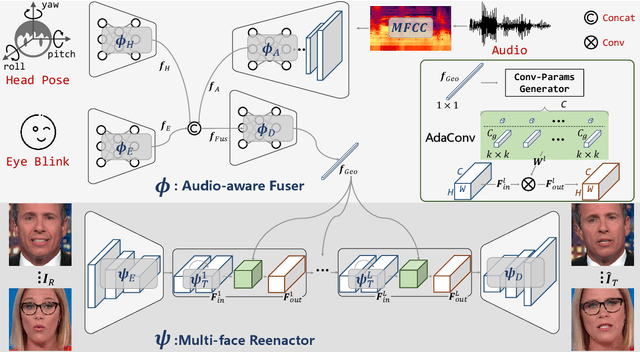
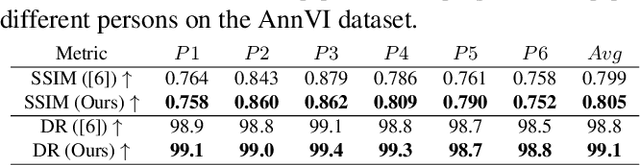


Audio-guided face reenactment aims to generate a photorealistic face that has matched facial expression with the input audio. However, current methods can only reenact a special person once the model is trained or need extra operations such as 3D rendering and image post-fusion on the premise of generating vivid faces. To solve the above challenge, we propose a novel \emph{R}eal-time \emph{A}udio-guided \emph{M}ulti-face reenactment approach named \emph{APB2FaceV2}, which can reenact different target faces among multiple persons with corresponding reference face and drive audio signal as inputs. Enabling the model to be trained end-to-end and have a faster speed, we design a novel module named Adaptive Convolution (AdaConv) to infuse audio information into the network, as well as adopt a lightweight network as our backbone so that the network can run in real time on CPU and GPU. Comparison experiments prove the superiority of our approach than existing state-of-the-art methods, and further experiments demonstrate that our method is efficient and flexible for practical applications https://github.com/zhangzjn/APB2FaceV2