 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Selection Bias in Large Language Models via Permutation-Aware GRPO
Mar 22, 2026Large language models (LLMs) used for multiple-choice and pairwise evaluation tasks often exhibit selection bias due to non-semantic factors like option positions and label symbols. Existing inference-time debiasing is costly and may harm reasoning, while pointwise training ignores that the same question should yield consistent answers across permutations. To address this issue, we propose Permutation-Aware Group Relative Policy Optimization (PA-GRPO), which mitigates selection bias by enforcing permutation-consistent semantic reasoning. PA-GRPO constructs a permutation group for each instance by generating multiple candidate permutations, and optimizes the model using two complementary mechanisms: (1) cross-permutation advantage, which computes advantages relative to the mean reward over all permutations of the same instance, and (2) consistency-aware reward, which encourages the model to produce consistent decisions across different permutations. Experimental results demonstrate that PA-GRPO outperforms strong baselines across seven benchmarks, substantially reducing selection bias while maintaining high overall performance. The code will be made available on Github (https://github.com/ECNU-Text-Computing/PA-GRPO).
MoRI: Learning Motivation-Grounded Reasoning for Scientific Ideation in Large Language Models
Mar 19, 2026Scientific ideation aims to propose novel solutions within a given scientific context. Existing LLM-based agentic approaches emulate human research workflows, yet inadequately model scientific reasoning, resulting in surface-level conceptual recombinations that lack technical depth and scientific grounding. To address this issue, we propose \textbf{MoRI} (\textbf{Mo}tivation-grounded \textbf{R}easoning for Scientific \textbf{I}deation), a framework that enables LLMs to explicitly learn the reasoning process from research motivations to methodologies. The base LLM is initialized via supervised fine-tuning to generate a research motivation from a given context, and is subsequently trained under a composite reinforcement learning reward that approximates scientific rigor: (1) entropy-aware information gain encourages the model to uncover and elaborate high-complexity technical details grounded in ground-truth methodologies, and (2) contrastive semantic gain constrains the reasoning trajectory to maintain conceptually aligned with scientifically valid solutions. Empirical results show that MoRI significantly outperforms strong commercial LLMs and complex agentic baselines across multiple dimensions, including novelty, technical rigor, and feasibility. The code will be made available on \href{https://github.com/ECNU-Text-Computing/IdeaGeneration}{GitHub}.
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
Mar 19, 2026Prior motion generation largely follows two paradigms: continuous diffusion models that excel at kinematic control, and discrete token-based generators that are effective for semantic conditioning. To combine their strengths, we propose a three-stage framework comprising condition feature extraction (Perception), discrete token generation (Planning), and diffusion-based motion synthesis (Control). Central to this framework is MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from fine-grained reconstruction by delegating motion recovery to a diffusion decoder, enabling compact single-layer tokens while preserving motion fidelity. For kinematic conditions, coarse constraints guide token generation during planning, while fine-grained constraints are enforced during control through diffusion-based optimization. This design prevents kinematic details from disrupting semantic token planning. On HumanML3D, our method significantly improves controllability and fidelity over MaskControl while using only one-sixth of the tokens, reducing trajectory error from 0.72 cm to 0.08 cm and FID from 0.083 to 0.029. Unlike prior methods that degrade under stronger kinematic constraints, ours improves fidelity, reducing FID from 0.033 to 0.014.
From Isolated Scoring to Collaborative Ranking: A Comparison-Native Framework for LLM-Based Paper Evaluation
Mar 18, 2026Large language models (LLMs) are currently applied to scientific paper evaluation by assigning an absolute score to each paper independently. However, since score scales vary across conferences, time periods, and evaluation criteria, models trained on absolute scores are prone to fitting narrow, context-specific rules rather than developing robust scholarly judgment. To overcome this limitation, we propose shifting paper evaluation from isolated scoring to collaborative ranking. In particular, we design \textbf{C}omparison-\textbf{N}ative framework for \textbf{P}aper \textbf{E}valuation (\textbf{CNPE}), integrating comparison into both data construction and model learning. We first propose a graph-based similarity ranking algorithm to facilitate the sampling of more informative and discriminative paper pairs from a collection. We then enhance relative quality judgment through supervised fine-tuning and reinforcement learning with comparison-based rewards. At inference, the model performs pairwise comparisons over sampled paper pairs and aggregates these preference signals into a global relative quality ranking. Experimental results demonstrate that our framework achieves an average relative improvement of \textbf{21.8\%} over the strong baseline DeepReview-14B, while exhibiting robust generalization to five previously unseen datasets. \href{https://github.com/ECNU-Text-Computing/ComparisonReview}{Code}.
Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
Mar 17, 2026Vision-Language-Action (VLA) models have recently emerged as a promising paradigm for robotic manipulation, in which reliable action prediction critically depends on accurately interpreting and integrating visual observations conditioned on language instructions. Although recent works have sought to enhance the visual capabilities of VLA models, most approaches treat the LLM backbone as a black box, providing limited insight into how visual information is grounded into action generation. Therefore, we perform a systematic analysis of multiple VLA models across different action-generation paradigms and observe that sensitivity to visual tokens progressively decreases in deeper layers during action generation. Motivated by this observation, we propose \textbf{DeepVision-VLA}, built on a \textbf{Vision-Language Mixture-of-Transformers (VL-MoT)} framework. This framework enables shared attention between the vision foundation model and the VLA backbone, injecting multi-level visual features from the vision expert into deeper layers of the VLA backbone to enhance visual representations for precise and complex manipulation. In addition, we introduce \textbf{Action-Guided Visual Pruning (AGVP)}, which leverages shallow-layer attention to prune irrelevant visual tokens while preserving task-relevant ones, reinforcing critical visual cues for manipulation with minimal computational overhead. DeepVision-VLA outperforms prior state-of-the-art methods by 9.0\% and 7.5\% on simulated and real-world tasks, respectively, providing new insights for the design of visually enhanced VLA models.
Demystifing Video Reasoning
Mar 17, 2026Recent advances in video generation have revealed an unexpected phenomenon: diffusion-based video models exhibit non-trivial reasoning capabilities. Prior work attributes this to a Chain-of-Frames (CoF) mechanism, where reasoning is assumed to unfold sequentially across video frames. In this work, we challenge this assumption and uncover a fundamentally different mechanism. We show that reasoning in video models instead primarily emerges along the diffusion denoising steps. Through qualitative analysis and targeted probing experiments, we find that models explore multiple candidate solutions in early denoising steps and progressively converge to a final answer, a process we term Chain-of-Steps (CoS). Beyond this core mechanism, we identify several emergent reasoning behaviors critical to model performance: (1) working memory, enabling persistent reference; (2) self-correction and enhancement, allowing recovery from incorrect intermediate solutions; and (3) perception before action, where early steps establish semantic grounding and later steps perform structured manipulation. During a diffusion step, we further uncover self-evolved functional specialization within Diffusion Transformers, where early layers encode dense perceptual structure, middle layers execute reasoning, and later layers consolidate latent representations. Motivated by these insights, we present a simple training-free strategy as a proof-of-concept, demonstrating how reasoning can be improved by ensembling latent trajectories from identical models with different random seeds. Overall, our work provides a systematic understanding of how reasoning emerges in video generation models, offering a foundation to guide future research in better exploiting the inherent reasoning dynamics of video models as a new substrate for intelligence.
TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
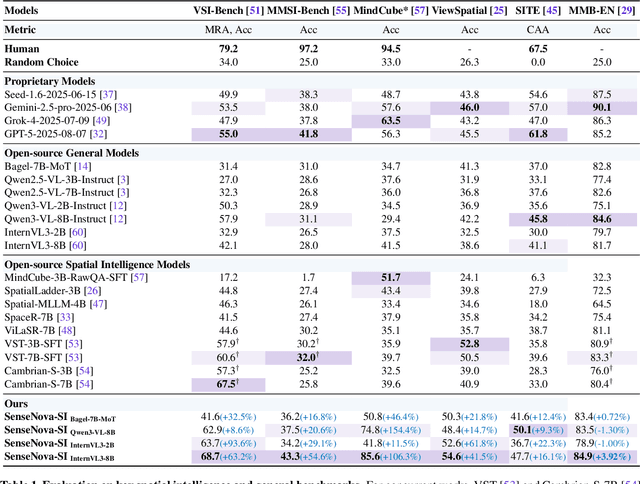


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
Causal Inspired Multi Modal Recommendation
Oct 14, 2025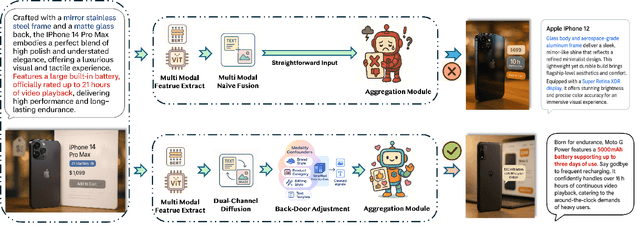
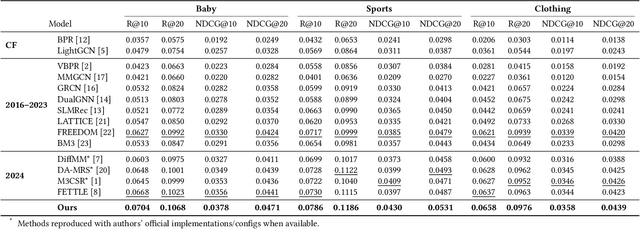
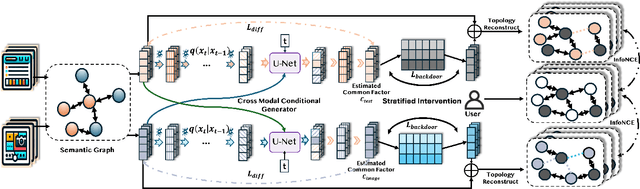
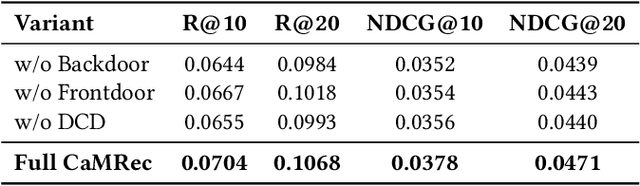
Multimodal recommender systems enhance personalized recommendations in e-commerce and online advertising by integrating visual, textual, and user-item interaction data. However, existing methods often overlook two critical biases: (i) modal confounding, where latent factors (e.g., brand style or product category) simultaneously drive multiple modalities and influence user preference, leading to spurious feature-preference associations; (ii) interaction bias, where genuine user preferences are mixed with noise from exposure effects and accidental clicks. To address these challenges, we propose a Causal-inspired multimodal Recommendation framework. Specifically, we introduce a dual-channel cross-modal diffusion module to identify hidden modal confounders, utilize back-door adjustment with hierarchical matching and vector-quantized codebooks to block confounding paths, and apply front-door adjustment combined with causal topology reconstruction to build a deconfounded causal subgraph. Extensive experiments on three real-world e-commerce datasets demonstrate that our method significantly outperforms state-of-the-art baselines while maintaining strong interpretability.