 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridVLA: Collaborative Diffusion and Autoregression in a Unified Vision-Language-Action Model
Mar 13, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods leverage large-scale pretrained knowledge, they disrupt the continuity of actions. Meanwhile, some VLA methods incorporate an additional diffusion head to predict continuous actions, relying solely on VLM-extracted features, which limits their reasoning capabilities. In this paper, we introduce HybridVLA, a unified framework that seamlessly integrates the strengths of both autoregressive and diffusion policies within a single large language model, rather than simply connecting them. To bridge the generation gap, a collaborative training recipe is proposed that injects the diffusion modeling directly into the next-token prediction. With this recipe, we find that these two forms of action prediction not only reinforce each other but also exhibit varying performance across different tasks. Therefore, we design a collaborative action ensemble mechanism that adaptively fuses these two predictions, leading to more robust control. In experiments, HybridVLA outperforms previous state-of-the-art VLA methods across various simulation and real-world tasks, including both single-arm and dual-arm robots, while demonstrating stable manipulation in previously unseen configurations.
RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
Feb 28, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: Planning Capability, which involves decomposing complex manipulation instructions into manageable sub-tasks; Affordance Perception, the ability to recognize and interpret the affordances of interactive objects; and Trajectory Prediction, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024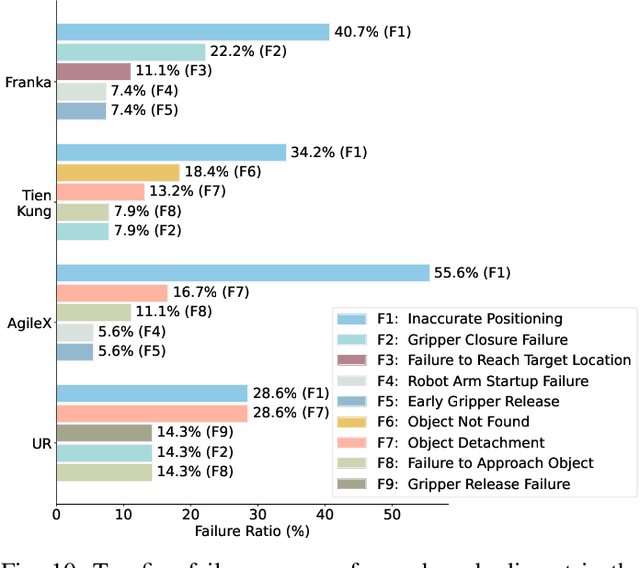
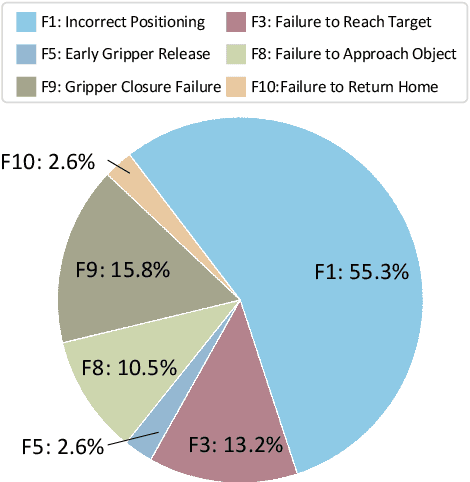
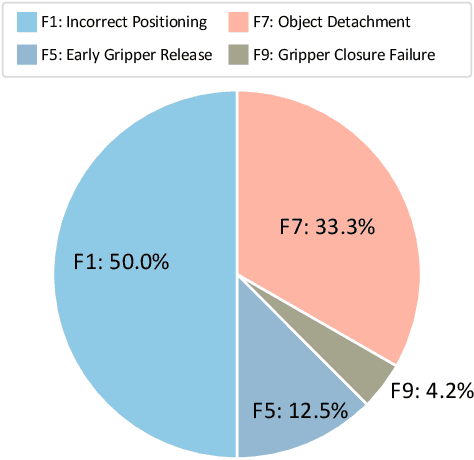
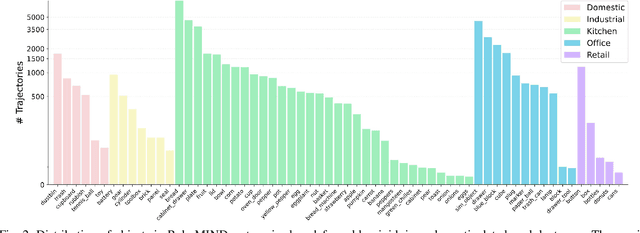
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Jun 06, 2024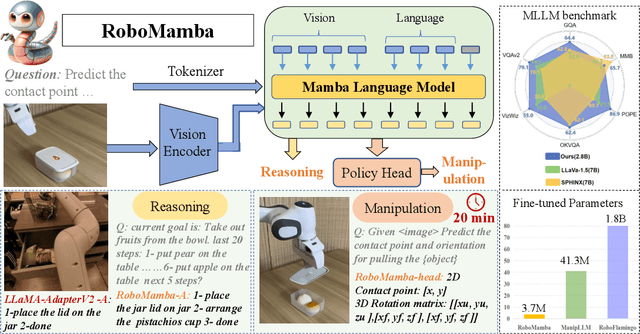



A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web
$\textit{S}^3$Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
May 30, 2024



Photorealistic 3D reconstruction of street scenes is a critical technique for developing real-world simulators for autonomous driving. Despite the efficacy of Neural Radiance Fields (NeRF) for driving scenes, 3D Gaussian Splatting (3DGS) emerges as a promising direction due to its faster speed and more explicit representation. However, most existing street 3DGS methods require tracked 3D vehicle bounding boxes to decompose the static and dynamic elements for effective reconstruction, limiting their applications for in-the-wild scenarios. To facilitate efficient 3D scene reconstruction without costly annotations, we propose a self-supervised street Gaussian ($\textit{S}^3$Gaussian) method to decompose dynamic and static elements from 4D consistency. We represent each scene with 3D Gaussians to preserve the explicitness and further accompany them with a spatial-temporal field network to compactly model the 4D dynamics. We conduct extensive experiments on the challenging Waymo-Open dataset to evaluate the effectiveness of our method. Our $\textit{S}^3$Gaussian demonstrates the ability to decompose static and dynamic scenes and achieves the best performance without using 3D annotations. Code is available at: https://github.com/nnanhuang/S3Gaussian/.