 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Paper and Code
Jun 06, 2024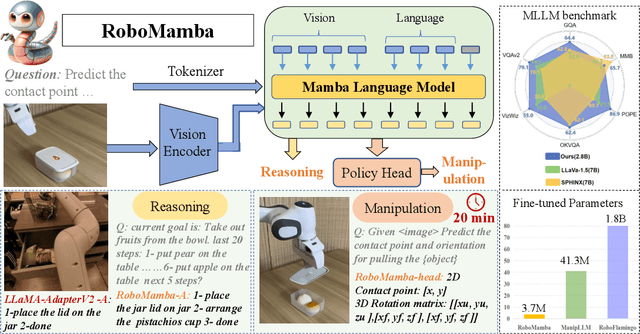



A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web