 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAACKIT: Track Annotation and Analytics with Continuous Knowledge Integration Tool
Dec 18, 2024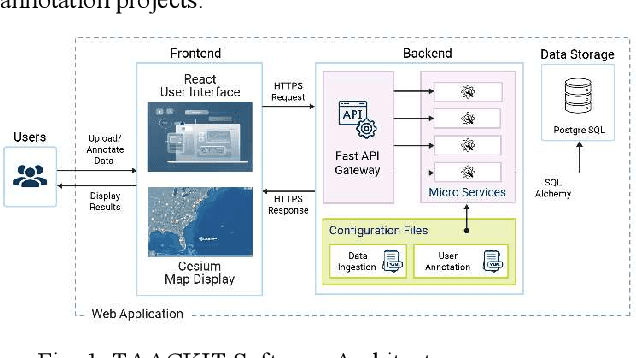
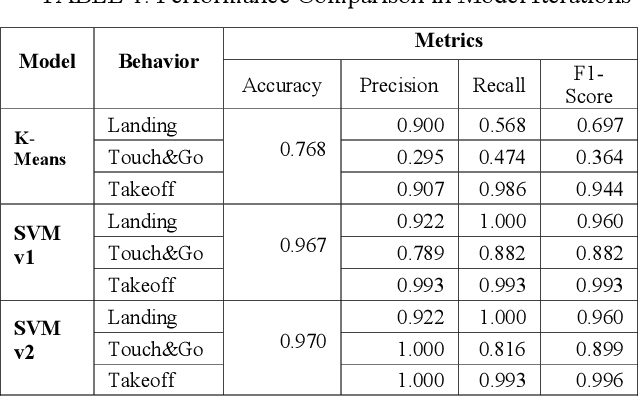
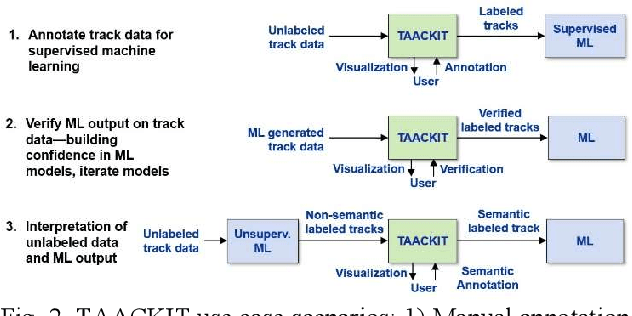
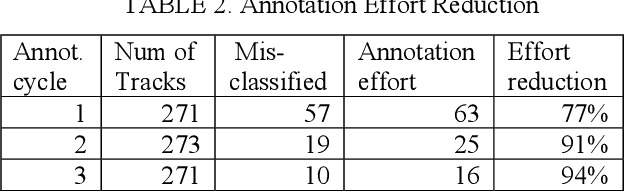
Machine learning (ML) is a powerful tool for efficiently analyzing data, detecting patterns, and forecasting trends across various domains such as text, audio, and images. The availability of annotation tools to generate reliably annotated data is crucial for advances in ML applications. In the domain of geospatial tracks, the lack of such tools to annotate and validate data impedes rapid and accessible ML application development. This paper presents Track Annotation and Analytics with Continuous Knowledge Integration Tool (TAACKIT) to serve the critically important functions of annotating geospatial track data and validating ML models. We demonstrate an ML application use case in the air traffic domain to illustrate its data annotation and model evaluation power and quantify the annotation effort reduction.
Lift3D Foundation Policy: Lifting 2D Large-Scale Pretrained Models for Robust 3D Robotic Manipulation
Nov 27, 2024



3D geometric information is essential for manipulation tasks, as robots need to perceive the 3D environment, reason about spatial relationships, and interact with intricate spatial configurations. Recent research has increasingly focused on the explicit extraction of 3D features, while still facing challenges such as the lack of large-scale robotic 3D data and the potential loss of spatial geometry. To address these limitations, we propose the Lift3D framework, which progressively enhances 2D foundation models with implicit and explicit 3D robotic representations to construct a robust 3D manipulation policy. Specifically, we first design a task-aware masked autoencoder that masks task-relevant affordance patches and reconstructs depth information, enhancing the 2D foundation model's implicit 3D robotic representation. After self-supervised fine-tuning, we introduce a 2D model-lifting strategy that establishes a positional mapping between the input 3D points and the positional embeddings of the 2D model. Based on the mapping, Lift3D utilizes the 2D foundation model to directly encode point cloud data, leveraging large-scale pretrained knowledge to construct explicit 3D robotic representations while minimizing spatial information loss. In experiments, Lift3D consistently outperforms previous state-of-the-art methods across several simulation benchmarks and real-world scenarios.
Quantum Computing for Climate Resilience and Sustainability Challenges
Jul 23, 2024


The escalating impacts of climate change and the increasing demand for sustainable development and natural resource management necessitate innovative technological solutions. Quantum computing (QC) has emerged as a promising tool with the potential to revolutionize these critical areas. This review explores the application of quantum machine learning and optimization techniques for climate change prediction and enhancing sustainable development. Traditional computational methods often fall short in handling the scale and complexity of climate models and natural resource management. Quantum advancements, however, offer significant improvements in computational efficiency and problem-solving capabilities. By synthesizing the latest research and developments, this paper highlights how QC and quantum machine learning can optimize multi-infrastructure systems towards climate neutrality. The paper also evaluates the performance of current quantum algorithms and hardware in practical applications and presents realistic cases, i.e., waste-to-energy in anaerobic digestion, disaster prevention in flooding prediction, and new material development for carbon capture. The integration of these quantum technologies promises to drive significant advancements in achieving climate resilience and sustainable development.
RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
Jun 06, 2024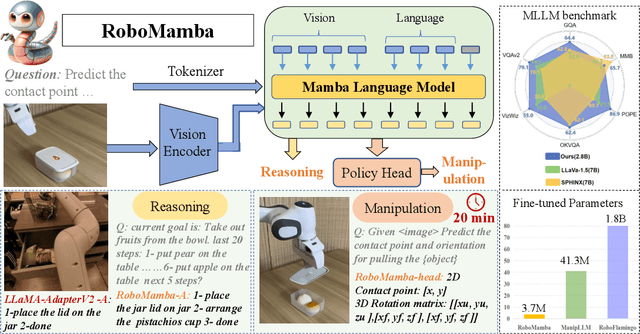



A fundamental objective in robot manipulation is to enable models to comprehend visual scenes and execute actions. Although existing robot Multimodal Large Language Models (MLLMs) can handle a range of basic tasks, they still face challenges in two areas: 1) inadequate reasoning ability to tackle complex tasks, and 2) high computational costs for MLLM fine-tuning and inference. The recently proposed state space model (SSM) known as Mamba demonstrates promising capabilities in non-trivial sequence modeling with linear inference complexity. Inspired by this, we introduce RoboMamba, an end-to-end robotic MLLM that leverages the Mamba model to deliver both robotic reasoning and action capabilities, while maintaining efficient fine-tuning and inference. Specifically, we first integrate the vision encoder with Mamba, aligning visual data with language embedding through co-training, empowering our model with visual common sense and robot-related reasoning. To further equip RoboMamba with action pose prediction abilities, we explore an efficient fine-tuning strategy with a simple policy head. We find that once RoboMamba possesses sufficient reasoning capability, it can acquire manipulation skills with minimal fine-tuning parameters (0.1\% of the model) and time (20 minutes). In experiments, RoboMamba demonstrates outstanding reasoning capabilities on general and robotic evaluation benchmarks. Meanwhile, our model showcases impressive pose prediction results in both simulation and real-world experiments, achieving inference speeds 7 times faster than existing robot MLLMs. Our project web page: https://sites.google.com/view/robomamba-web
Self-Corrected Multimodal Large Language Model for End-to-End Robot Manipulation
May 27, 2024



Robot manipulation policies have shown unsatisfactory action performance when confronted with novel task or object instances. Hence, the capability to automatically detect and self-correct failure action is essential for a practical robotic system. Recently, Multimodal Large Language Models (MLLMs) have shown promise in visual instruction following and demonstrated strong reasoning abilities in various tasks. To unleash general MLLMs as an end-to-end robotic agent, we introduce a Self-Corrected (SC)-MLLM, equipping our model not only to predict end-effector poses but also to autonomously recognize and correct failure actions. Specifically, we first conduct parameter-efficient fine-tuning to empower MLLM with pose prediction ability, which is reframed as a language modeling problem. When facing execution failures, our model learns to identify low-level action error causes (i.e., position and rotation errors) and adaptively seeks prompt feedback from experts. Based on the feedback, SC-MLLM rethinks the current failure scene and generates the corrected actions. Furthermore, we design a continuous policy learning method for successfully corrected samples, enhancing the model's adaptability to the current scene configuration and reducing the frequency of expert intervention. To evaluate our SC-MLLM, we conduct extensive experiments in both simulation and real-world settings. SC-MLLM agent significantly improve manipulation accuracy compared to previous state-of-the-art robotic MLLM (ManipLLM), increasing from 57\% to 79\% on seen object categories and from 47\% to 69\% on unseen novel categories.