 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
Action-Sketcher: From Reasoning to Action via Visual Sketches for Long-Horizon Robotic Manipulation
Jan 04, 2026Long-horizon robotic manipulation is increasingly important for real-world deployment, requiring spatial disambiguation in complex layouts and temporal resilience under dynamic interaction. However, existing end-to-end and hierarchical Vision-Language-Action (VLA) policies often rely on text-only cues while keeping plan intent latent, which undermines referential grounding in cluttered or underspecified scenes, impedes effective task decomposition of long-horizon goals with close-loop interaction, and limits causal explanation by obscuring the rationale behind action choices. To address these issues, we first introduce Visual Sketch, an implausible visual intermediate that renders points, boxes, arrows, and typed relations in the robot's current views to externalize spatial intent, connect language to scene geometry. Building on Visual Sketch, we present Action-Sketcher, a VLA framework that operates in a cyclic See-Think-Sketch-Act workflow coordinated by adaptive token-gated strategy for reasoning triggers, sketch revision, and action issuance, thereby supporting reactive corrections and human interaction while preserving real-time action prediction. To enable scalable training and evaluation, we curate diverse corpus with interleaved images, text, Visual Sketch supervision, and action sequences, and train Action-Sketcher with a multi-stage curriculum recipe that combines interleaved sequence alignment for modality unification, language-to-sketch consistency for precise linguistic grounding, and imitation learning augmented with sketch-to-action reinforcement for robustness. Extensive experiments on cluttered scenes and multi-object tasks, in simulation and on real-world tasks, show improved long-horizon success, stronger robustness to dynamic scene changes, and enhanced interpretability via editable sketches and step-wise plans. Project website: https://action-sketcher.github.io
RoboMirror: Understand Before You Imitate for Video to Humanoid Locomotion
Dec 30, 2025Humans learn locomotion through visual observation, interpreting visual content first before imitating actions. However, state-of-the-art humanoid locomotion systems rely on either curated motion capture trajectories or sparse text commands, leaving a critical gap between visual understanding and control. Text-to-motion methods suffer from semantic sparsity and staged pipeline errors, while video-based approaches only perform mechanical pose mimicry without genuine visual understanding. We propose RoboMirror, the first retargeting-free video-to-locomotion framework embodying "understand before you imitate". Leveraging VLMs, it distills raw egocentric/third-person videos into visual motion intents, which directly condition a diffusion-based policy to generate physically plausible, semantically aligned locomotion without explicit pose reconstruction or retargeting. Extensive experiments validate the effectiveness of RoboMirror, it enables telepresence via egocentric videos, drastically reduces third-person control latency by 80%, and achieves a 3.7% higher task success rate than baselines. By reframing humanoid control around video understanding, we bridge the visual understanding and action gap.
Robo-Dopamine: General Process Reward Modeling for High-Precision Robotic Manipulation
Dec 29, 2025The primary obstacle for applying reinforcement learning (RL) to real-world robotics is the design of effective reward functions. While recently learning-based Process Reward Models (PRMs) are a promising direction, they are often hindered by two fundamental limitations: their reward models lack step-aware understanding and rely on single-view perception, leading to unreliable assessments of fine-grained manipulation progress; and their reward shaping procedures are theoretically unsound, often inducing a semantic trap that misguides policy optimization. To address these, we introduce Dopamine-Reward, a novel reward modeling method for learning a general-purpose, step-aware process reward model from multi-view inputs. At its core is our General Reward Model (GRM), trained on a vast 3,400+ hour dataset, which leverages Step-wise Reward Discretization for structural understanding and Multi-Perspective Reward Fusion to overcome perceptual limitations. Building upon Dopamine-Reward, we propose Dopamine-RL, a robust policy learning framework that employs a theoretically-sound Policy-Invariant Reward Shaping method, which enables the agent to leverage dense rewards for efficient self-improvement without altering the optimal policy, thereby fundamentally avoiding the semantic trap. Extensive experiments across diverse simulated and real-world tasks validate our approach. GRM achieves state-of-the-art accuracy in reward assessment, and Dopamine-RL built on GRM significantly improves policy learning efficiency. For instance, after GRM is adapted to a new task in a one-shot manner from a single expert trajectory, the resulting reward model enables Dopamine-RL to improve the policy from near-zero to 95% success with only 150 online rollouts (approximately 1 hour of real robot interaction), while retaining strong generalization across tasks. Project website: https://robo-dopamine.github.io
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
Dec 28, 2025Recent advances in vision, language, and multimodal learning have substantially accelerated progress in robotic foundation models, with robot manipulation remaining a central and challenging problem. This survey examines robot manipulation from an algorithmic perspective and organizes recent learning-based approaches within a unified abstraction of high-level planning and low-level control. At the high level, we extend the classical notion of task planning to include reasoning over language, code, motion, affordances, and 3D representations, emphasizing their role in structured and long-horizon decision making. At the low level, we propose a training-paradigm-oriented taxonomy for learning-based control, organizing existing methods along input modeling, latent representation learning, and policy learning. Finally, we identify open challenges and prospective research directions related to scalability, data efficiency, multimodal physical interaction, and safety. Together, these analyses aim to clarify the design space of modern foundation models for robotic manipulation.
Scaling Up AI-Generated Image Detection via Generator-Aware Prototypes
Dec 15, 2025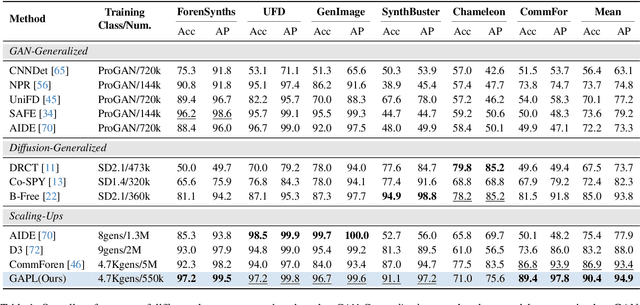
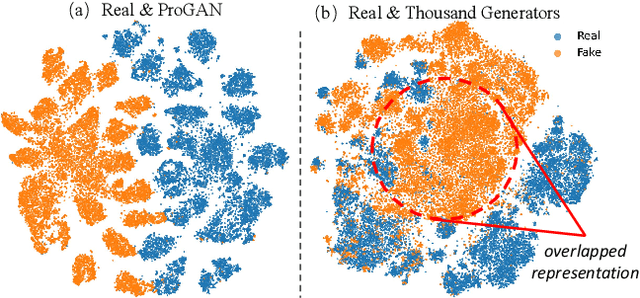
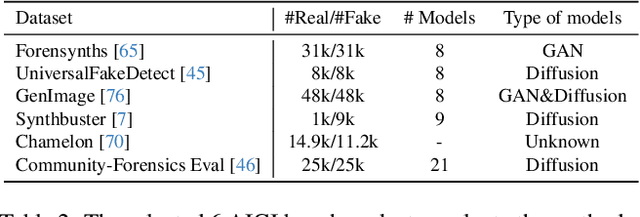
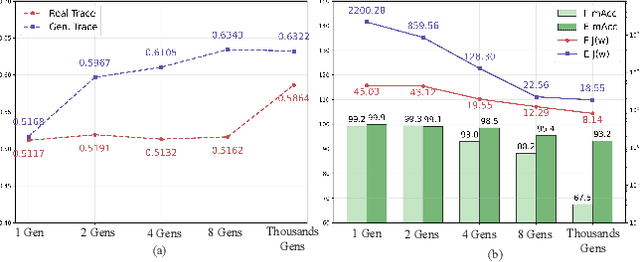
The pursuit of a universal AI-generated image (AIGI) detector often relies on aggregating data from numerous generators to improve generalization. However, this paper identifies a paradoxical phenomenon we term the Benefit then Conflict dilemma, where detector performance stagnates and eventually degrades as source diversity expands. Our systematic analysis, diagnoses this failure by identifying two core issues: severe data-level heterogeneity, which causes the feature distributions of real and synthetic images to increasingly overlap, and a critical model-level bottleneck from fixed, pretrained encoders that cannot adapt to the rising complexity. To address these challenges, we propose Generator-Aware Prototype Learning (GAPL), a framework that constrain representation with a structured learning paradigm. GAPL learns a compact set of canonical forgery prototypes to create a unified, low-variance feature space, effectively countering data heterogeneity.To resolve the model bottleneck, it employs a two-stage training scheme with Low-Rank Adaptation, enhancing its discriminative power while preserving valuable pretrained knowledge. This approach establishes a more robust and generalizable decision boundary. Through extensive experiments, we demonstrate that GAPL achieves state-of-the-art performance, showing superior detection accuracy across a wide variety of GAN and diffusion-based generators. Code is available at https://github.com/UltraCapture/GAPL
RoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
RoboOS-NeXT: A Unified Memory-based Framework for Lifelong, Scalable, and Robust Multi-Robot Collaboration
Oct 30, 2025The proliferation of collaborative robots across diverse tasks and embodiments presents a central challenge: achieving lifelong adaptability, scalable coordination, and robust scheduling in multi-agent systems. Existing approaches, from vision-language-action (VLA) models to hierarchical frameworks, fall short due to their reliance on limited or dividual-agent memory. This fundamentally constrains their ability to learn over long horizons, scale to heterogeneous teams, or recover from failures, highlighting the need for a unified memory representation. To address these limitations, we introduce RoboOS-NeXT, a unified memory-based framework for lifelong, scalable, and robust multi-robot collaboration. At the core of RoboOS-NeXT is the novel Spatio-Temporal-Embodiment Memory (STEM), which integrates spatial scene geometry, temporal event history, and embodiment profiles into a shared representation. This memory-centric design is integrated into a brain-cerebellum framework, where a high-level brain model performs global planning by retrieving and updating STEM, while low-level controllers execute actions locally. This closed loop between cognition, memory, and execution enables dynamic task allocation, fault-tolerant collaboration, and consistent state synchronization. We conduct extensive experiments spanning complex coordination tasks in restaurants, supermarkets, and households. Our results demonstrate that RoboOS-NeXT achieves superior performance across heterogeneous embodiments, validating its effectiveness in enabling lifelong, scalable, and robust multi-robot collaboration. Project website: https://flagopen.github.io/RoboOS/
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Oct 01, 2025We introduce \textsc{MathSticks}, a benchmark for Visual Symbolic Compositional Reasoning (VSCR), which unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation that must be corrected by moving one or two sticks under strict conservation rules. The benchmark includes both text-guided and purely visual settings, systematically covering digit scale, move complexity, solution multiplicity, and operator variation, with 1.4M generated instances and a curated test set. Evaluations of 14 vision--language models reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the visual regime, while humans exceed 90\% accuracy. These findings establish \textsc{MathSticks} as a rigorous testbed for advancing compositional reasoning across vision and symbols. Our code and dataset are publicly available at https://github.com/Yuheng2000/MathSticks.
VisualTrans: A Benchmark for Real-World Visual Transformation Reasoning
Aug 06, 2025Visual transformation reasoning (VTR) is a vital cognitive capability that empowers intelligent agents to understand dynamic scenes, model causal relationships, and predict future states, and thereby guiding actions and laying the foundation for advanced intelligent systems. However, existing benchmarks suffer from a sim-to-real gap, limited task complexity, and incomplete reasoning coverage, limiting their practical use in real-world scenarios. To address these limitations, we introduce VisualTrans, the first comprehensive benchmark specifically designed for VTR in real-world human-object interaction scenarios. VisualTrans encompasses 12 semantically diverse manipulation tasks and systematically evaluates three essential reasoning dimensions - spatial, procedural, and quantitative - through 6 well-defined subtask types. The benchmark features 472 high-quality question-answer pairs in various formats, including multiple-choice, open-ended counting, and target enumeration. We introduce a scalable data construction pipeline built upon first-person manipulation videos, which integrates task selection, image pair extraction, automated metadata annotation with large multimodal models, and structured question generation. Human verification ensures the final benchmark is both high-quality and interpretable. Evaluations of various state-of-the-art vision-language models show strong performance in static spatial tasks. However, they reveal notable shortcomings in dynamic, multi-step reasoning scenarios, particularly in areas like intermediate state recognition and transformation sequence planning. These findings highlight fundamental weaknesses in temporal modeling and causal reasoning, providing clear directions for future research aimed at developing more capable and generalizable VTR systems. The dataset and code are available at https://github.com/WangYipu2002/VisualTrans.