 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeCo: Enhancing LLM-Empowered Multi-Robot Collaboration via Similar Task Memoization
Jan 28, 2026Multi-robot systems have been widely deployed in real-world applications, providing significant improvements in efficiency and reductions in labor costs. However, most existing multi-robot collaboration methods rely on extensive task-specific training, which limits their adaptability to new or diverse scenarios. Recent research leverages the language understanding and reasoning capabilities of large language models (LLMs) to enable more flexible collaboration without specialized training. Yet, current LLM-empowered approaches remain inefficient: when confronted with identical or similar tasks, they must replan from scratch because they omit task-level similarities. To address this limitation, we propose MeCo, a similarity-aware multi-robot collaboration framework that applies the principle of ``cache and reuse'' (a.k.a., memoization) to reduce redundant computation. Unlike simple task repetition, identifying and reusing solutions for similar but not identical tasks is far more challenging, particularly in multi-robot settings. To this end, MeCo introduces a new similarity testing method that retrieves previously solved tasks with high relevance, enabling effective plan reuse without re-invoking LLMs. Furthermore, we present MeCoBench, the first benchmark designed to evaluate performance on similar-task collaboration scenarios. Experimental results show that MeCo substantially reduces planning costs and improves success rates compared with state-of-the-art approaches.
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
Dec 28, 2025Recent advances in vision, language, and multimodal learning have substantially accelerated progress in robotic foundation models, with robot manipulation remaining a central and challenging problem. This survey examines robot manipulation from an algorithmic perspective and organizes recent learning-based approaches within a unified abstraction of high-level planning and low-level control. At the high level, we extend the classical notion of task planning to include reasoning over language, code, motion, affordances, and 3D representations, emphasizing their role in structured and long-horizon decision making. At the low level, we propose a training-paradigm-oriented taxonomy for learning-based control, organizing existing methods along input modeling, latent representation learning, and policy learning. Finally, we identify open challenges and prospective research directions related to scalability, data efficiency, multimodal physical interaction, and safety. Together, these analyses aim to clarify the design space of modern foundation models for robotic manipulation.
Scaling Up AI-Generated Image Detection via Generator-Aware Prototypes
Dec 15, 2025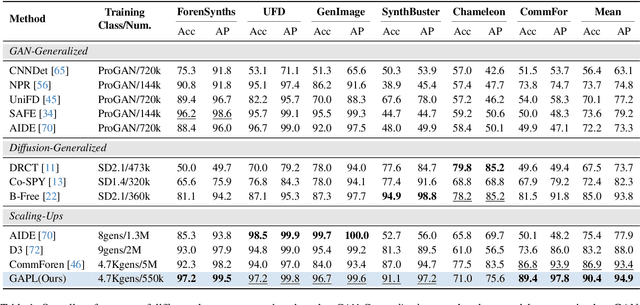
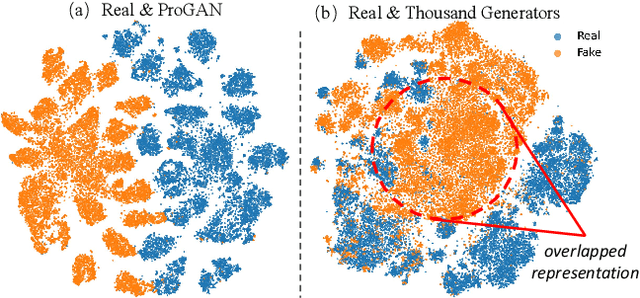
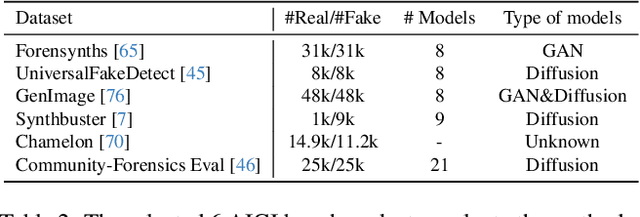
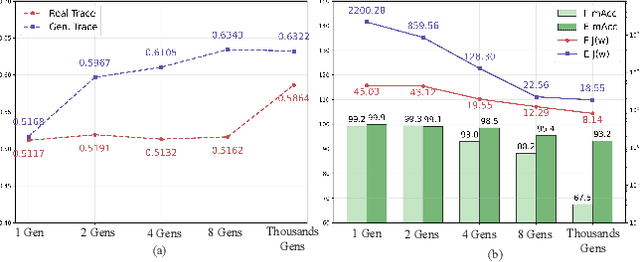
The pursuit of a universal AI-generated image (AIGI) detector often relies on aggregating data from numerous generators to improve generalization. However, this paper identifies a paradoxical phenomenon we term the Benefit then Conflict dilemma, where detector performance stagnates and eventually degrades as source diversity expands. Our systematic analysis, diagnoses this failure by identifying two core issues: severe data-level heterogeneity, which causes the feature distributions of real and synthetic images to increasingly overlap, and a critical model-level bottleneck from fixed, pretrained encoders that cannot adapt to the rising complexity. To address these challenges, we propose Generator-Aware Prototype Learning (GAPL), a framework that constrain representation with a structured learning paradigm. GAPL learns a compact set of canonical forgery prototypes to create a unified, low-variance feature space, effectively countering data heterogeneity.To resolve the model bottleneck, it employs a two-stage training scheme with Low-Rank Adaptation, enhancing its discriminative power while preserving valuable pretrained knowledge. This approach establishes a more robust and generalizable decision boundary. Through extensive experiments, we demonstrate that GAPL achieves state-of-the-art performance, showing superior detection accuracy across a wide variety of GAN and diffusion-based generators. Code is available at https://github.com/UltraCapture/GAPL
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Oct 01, 2025We introduce \textsc{MathSticks}, a benchmark for Visual Symbolic Compositional Reasoning (VSCR), which unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation that must be corrected by moving one or two sticks under strict conservation rules. The benchmark includes both text-guided and purely visual settings, systematically covering digit scale, move complexity, solution multiplicity, and operator variation, with 1.4M generated instances and a curated test set. Evaluations of 14 vision--language models reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the visual regime, while humans exceed 90\% accuracy. These findings establish \textsc{MathSticks} as a rigorous testbed for advancing compositional reasoning across vision and symbols. Our code and dataset are publicly available at https://github.com/Yuheng2000/MathSticks.
When Deepfakes Look Real: Detecting AI-Generated Faces with Unlabeled Data due to Annotation Challenges
Aug 12, 2025Existing deepfake detection methods heavily depend on labeled training data. However, as AI-generated content becomes increasingly realistic, even \textbf{human annotators struggle to distinguish} between deepfakes and authentic images. This makes the labeling process both time-consuming and less reliable. Specifically, there is a growing demand for approaches that can effectively utilize large-scale unlabeled data from online social networks. Unlike typical unsupervised learning tasks, where categories are distinct, AI-generated faces closely mimic real image distributions and share strong similarities, causing performance drop in conventional strategies. In this paper, we introduce the Dual-Path Guidance Network (DPGNet), to tackle two key challenges: (1) bridging the domain gap between faces from different generation models, and (2) utilizing unlabeled image samples. The method features two core modules: text-guided cross-domain alignment, which uses learnable prompts to unify visual and textual embeddings into a domain-invariant feature space, and curriculum-driven pseudo label generation, which dynamically exploit more informative unlabeled samples. To prevent catastrophic forgetting, we also facilitate bridging between domains via cross-domain knowledge distillation. Extensive experiments on \textbf{11 popular datasets}, show that DPGNet outperforms SoTA approaches by \textbf{6.3\%}, highlighting its effectiveness in leveraging unlabeled data to address the annotation challenges posed by the increasing realism of deepfakes.
VisualTrans: A Benchmark for Real-World Visual Transformation Reasoning
Aug 06, 2025Visual transformation reasoning (VTR) is a vital cognitive capability that empowers intelligent agents to understand dynamic scenes, model causal relationships, and predict future states, and thereby guiding actions and laying the foundation for advanced intelligent systems. However, existing benchmarks suffer from a sim-to-real gap, limited task complexity, and incomplete reasoning coverage, limiting their practical use in real-world scenarios. To address these limitations, we introduce VisualTrans, the first comprehensive benchmark specifically designed for VTR in real-world human-object interaction scenarios. VisualTrans encompasses 12 semantically diverse manipulation tasks and systematically evaluates three essential reasoning dimensions - spatial, procedural, and quantitative - through 6 well-defined subtask types. The benchmark features 472 high-quality question-answer pairs in various formats, including multiple-choice, open-ended counting, and target enumeration. We introduce a scalable data construction pipeline built upon first-person manipulation videos, which integrates task selection, image pair extraction, automated metadata annotation with large multimodal models, and structured question generation. Human verification ensures the final benchmark is both high-quality and interpretable. Evaluations of various state-of-the-art vision-language models show strong performance in static spatial tasks. However, they reveal notable shortcomings in dynamic, multi-step reasoning scenarios, particularly in areas like intermediate state recognition and transformation sequence planning. These findings highlight fundamental weaknesses in temporal modeling and causal reasoning, providing clear directions for future research aimed at developing more capable and generalizable VTR systems. The dataset and code are available at https://github.com/WangYipu2002/VisualTrans.
CRC-SGAD: Conformal Risk Control for Supervised Graph Anomaly Detection
Apr 03, 2025



Graph Anomaly Detection (GAD) is critical in security-sensitive domains, yet faces reliability challenges: miscalibrated confidence estimation (underconfidence in normal nodes, overconfidence in anomalies), adversarial vulnerability of derived confidence score under structural perturbations, and limited efficacy of conventional calibration methods for sparse anomaly patterns. Thus we propose CRC-SGAD, a framework integrating statistical risk control into GAD via two innovations: (1) A Dual-Threshold Conformal Risk Control mechanism that provides theoretically guaranteed bounds for both False Negative Rate (FNR) and False Positive Rate (FPR) through providing prediction sets; (2) A Subgraph-aware Spectral Graph Neural Calibrator (SSGNC) that optimizes node representations through adaptive spectral filtering while reducing the size of prediction sets via hybrid loss optimization. Experiments on four datasets and five GAD models demonstrate statistically significant improvements in FNR and FPR control and prediction set size. CRC-SGAD establishes a paradigm for statistically rigorous anomaly detection in graph-structured security applications.
Alleviating Performance Disparity in Adversarial Spatiotemporal Graph Learning Under Zero-Inflated Distribution
Apr 01, 2025Spatiotemporal Graph Learning (SGL) under Zero-Inflated Distribution (ZID) is crucial for urban risk management tasks, including crime prediction and traffic accident profiling. However, SGL models are vulnerable to adversarial attacks, compromising their practical utility. While adversarial training (AT) has been widely used to bolster model robustness, our study finds that traditional AT exacerbates performance disparities between majority and minority classes under ZID, potentially leading to irreparable losses due to underreporting critical risk events. In this paper, we first demonstrate the smaller top-k gradients and lower separability of minority class are key factors contributing to this disparity. To address these issues, we propose MinGRE, a framework for Minority Class Gradients and Representations Enhancement. MinGRE employs a multi-dimensional attention mechanism to reweight spatiotemporal gradients, minimizing the gradient distribution discrepancies across classes. Additionally, we introduce an uncertainty-guided contrastive loss to improve the inter-class separability and intra-class compactness of minority representations with higher uncertainty. Extensive experiments demonstrate that the MinGRE framework not only significantly reduces the performance disparity across classes but also achieves enhanced robustness compared to existing baselines. These findings underscore the potential of our method in fostering the development of more equitable and robust models.
RoboBrain: A Unified Brain Model for Robotic Manipulation from Abstract to Concrete
Feb 28, 2025Recent advancements in Multimodal Large Language Models (MLLMs) have shown remarkable capabilities across various multimodal contexts. However, their application in robotic scenarios, particularly for long-horizon manipulation tasks, reveals significant limitations. These limitations arise from the current MLLMs lacking three essential robotic brain capabilities: Planning Capability, which involves decomposing complex manipulation instructions into manageable sub-tasks; Affordance Perception, the ability to recognize and interpret the affordances of interactive objects; and Trajectory Prediction, the foresight to anticipate the complete manipulation trajectory necessary for successful execution. To enhance the robotic brain's core capabilities from abstract to concrete, we introduce ShareRobot, a high-quality heterogeneous dataset that labels multi-dimensional information such as task planning, object affordance, and end-effector trajectory. ShareRobot's diversity and accuracy have been meticulously refined by three human annotators. Building on this dataset, we developed RoboBrain, an MLLM-based model that combines robotic and general multi-modal data, utilizes a multi-stage training strategy, and incorporates long videos and high-resolution images to improve its robotic manipulation capabilities. Extensive experiments demonstrate that RoboBrain achieves state-of-the-art performance across various robotic tasks, highlighting its potential to advance robotic brain capabilities.
AdvLoRA: Adversarial Low-Rank Adaptation of Vision-Language Models
Apr 20, 2024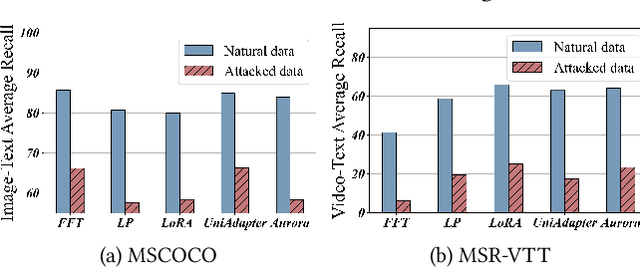



Vision-Language Models (VLMs) are a significant technique for Artificial General Intelligence (AGI). With the fast growth of AGI, the security problem become one of the most important challenges for VLMs. In this paper, through extensive experiments, we demonstrate the vulnerability of the conventional adaptation methods for VLMs, which may bring significant security risks. In addition, as the size of the VLMs increases, performing conventional adversarial adaptation techniques on VLMs results in high computational costs. To solve these problems, we propose a parameter-efficient \underline{Adv}ersarial adaptation method named \underline{AdvLoRA} by \underline{Lo}w-\underline{R}ank \underline{A}daptation. At first, we investigate and reveal the intrinsic low-rank property during the adversarial adaptation for VLMs. Different from LoRA, we improve the efficiency and robustness of adversarial adaptation by designing a novel reparameterizing method based on parameter clustering and parameter alignment. In addition, an adaptive parameter update strategy is proposed to further improve the robustness. By these settings, our proposed AdvLoRA alleviates the model security and high resource waste problems. Extensive experiments demonstrate the effectiveness and efficiency of the AdvLoRA.