 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Physical Awareness to LLMs through Sounds
Jun 11, 2025Large Language Models (LLMs) have shown remarkable capabilities in text and multimodal processing, yet they fundamentally lack physical awareness--understanding of real-world physical phenomena. In this work, we present ACORN, a framework that teaches LLMs physical awareness through sound, focusing on fundamental physical phenomena like the Doppler effect, multipath effect, and spatial relationships. To overcome data scarcity, ACORN introduce a physics-based simulator combining real-world sound sources with controlled physical channels to generate diverse training data. Using this simulator, we build AQA-PHY, a comprehensive Audio Question-Answer dataset, and propose an audio encoder that processes both magnitude and phase information. By connecting our audio encoder to state-of-the-art LLMs, we demonstrate reasonable results in both simulated and real-world tasks, such as line-of-sight detection, Doppler effect estimation, and Direction-of-Arrival estimation, paving the way for enabling LLMs to understand physical world.
AIM: Acoustic Inertial Measurement for Indoor Drone Localization and Tracking
Apr 02, 2025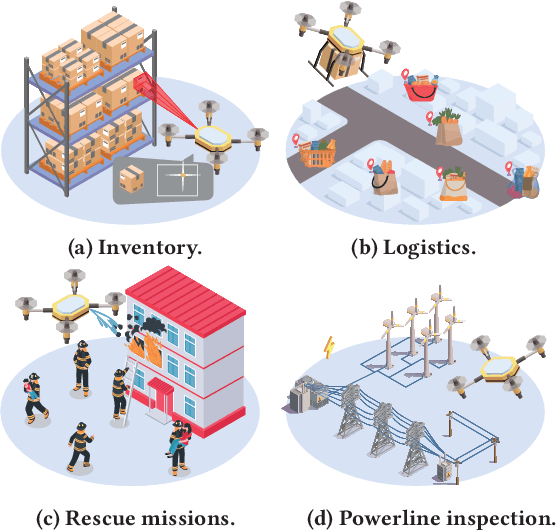

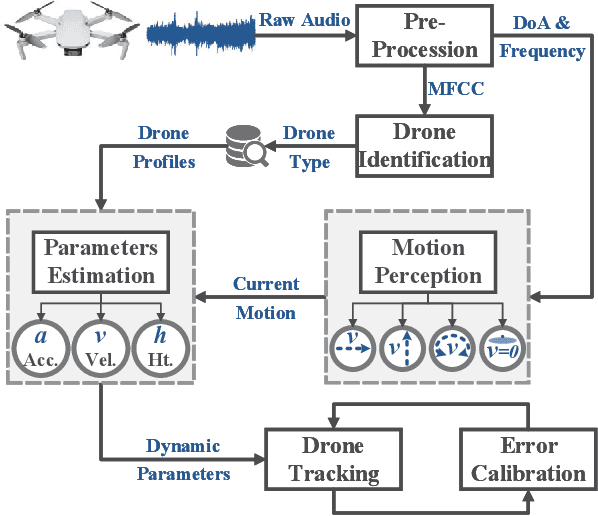
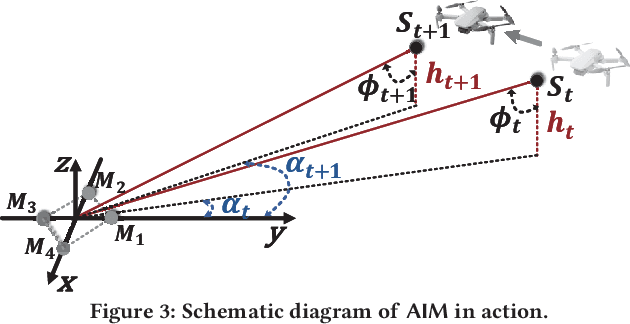
We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR). We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than commercial UWB-based systems in complex indoor scenarios, where state-of-the-art infrared systems would not even work because of NLoS settings. We further demonstrate that AIM can be extended to support indoor spaces with arbitrary ranges and layouts without loss of accuracy by deploying distributed microphone arrays.
Indoor Drone Localization and Tracking Based on Acoustic Inertial Measurement
Apr 01, 2025


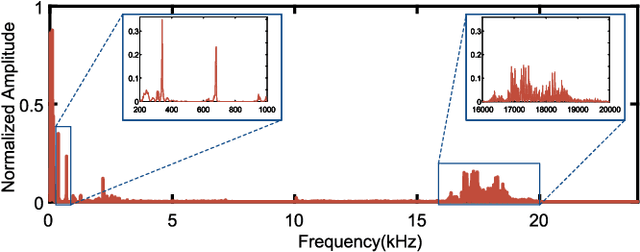
We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR) and demonstrate that AIM can support indoor spaces with arbitrary ranges and layouts. We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than that of commercial UWB-based systems in a complex 10m\times10m indoor scenario, where state-of-the-art infrared systems would not even work because of NLoS situations. When distributed microphone arrays are deployed, the mean error can be reduced to less than 0.5m in a 20m range, and even support spaces with arbitrary ranges and layouts.
Symphony: Localizing Multiple Acoustic Sources with a Single Microphone Array
Sep 30, 2022



Sound recognition is an important and popular function of smart devices. The location of sound is basic information associated with the acoustic source. Apart from sound recognition, whether the acoustic sources can be localized largely affects the capability and quality of the smart device's interactive functions. In this work, we study the problem of concurrently localizing multiple acoustic sources with a smart device (e.g., a smart speaker like Amazon Alexa). The existing approaches either can only localize a single source, or require deploying a distributed network of microphone arrays to function. Our proposal called Symphony is the first approach to tackle the above problem with a single microphone array. The insight behind Symphony is that the geometric layout of microphones on the array determines the unique relationship among signals from the same source along the same arriving path, while the source's location determines the DoAs (direction-of-arrival) of signals along different arriving paths. Symphony therefore includes a geometry-based filtering module to distinguish signals from different sources along different paths and a coherence-based module to identify signals from the same source. We implement Symphony with different types of commercial off-the-shelf microphone arrays and evaluate its performance under different settings. The results show that Symphony has a median localization error of 0.694m, which is 68% less than that of the state-of-the-art approach.
AdaComm: Tracing Channel Dynamics for Reliable Cross-Technology Communication
Sep 30, 2022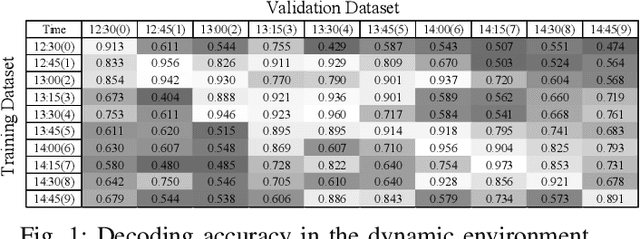
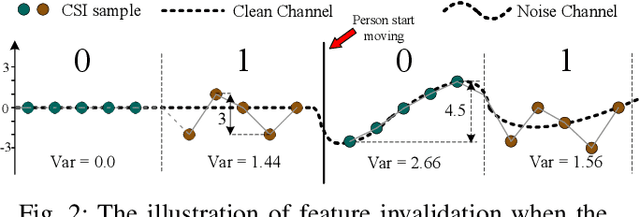
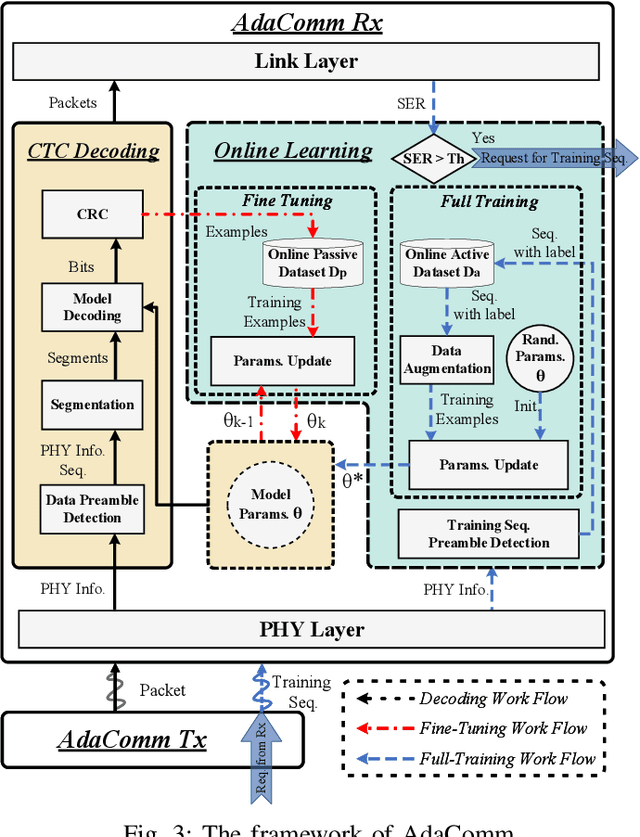
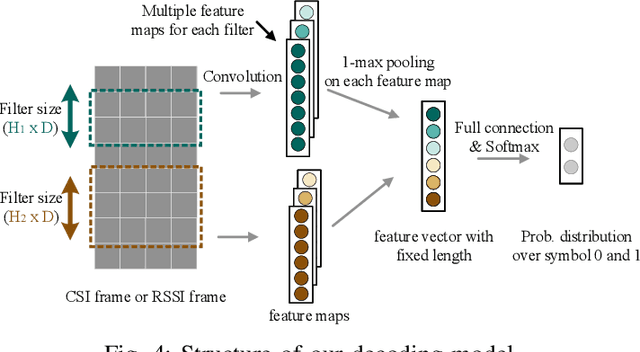
Cross-Technology Communication (CTC) is an emerging technology to support direct communication between wireless devices that follow different standards. In spite of the many different proposals from the community to enable CTC, the performance aspect of CTC is an equally important problem but has seldom been studied before. We find this problem is extremely challenging, due to the following reasons: on one hand, a link for CTC is essentially different from a conventional wireless link. The conventional link indicators like RSSI (received signal strength indicator) and SNR (signal to noise ratio) cannot be used to directly characterize a CTC link. On the other hand, the indirect indicators like PER (packet error rate), which is adopted by many existing CTC proposals, cannot capture the short-term link behavior. As a result, the existing CTC proposals fail to keep reliable performance under dynamic channel conditions. In order to address the above challenge, we in this paper propose AdaComm, a generic framework to achieve self-adaptive CTC in dynamic channels. Instead of reactively adjusting the CTC sender, AdaComm adopts online learning mechanism to adaptively adjust the decoding model at the CTC receiver. The self-adaptive decoding model automatically learns the effective features directly from the raw received signals that are embedded with the current channel state. With the lossless channel information, AdaComm further adopts the fine tuning and full training modes to cope with the continuous and abrupt channel dynamics. We implement AdaComm and integrate it with two existing CTC approaches that respectively employ CSI (channel state information) and RSSI as the information carrier. The evaluation results demonstrate that AdaComm can significantly reduce the SER (symbol error rate) by 72.9% and 49.2%, respectively, compared with the existing approaches.
ChordMics: Acoustic Signal Purification with Distributed Microphones
Sep 30, 2022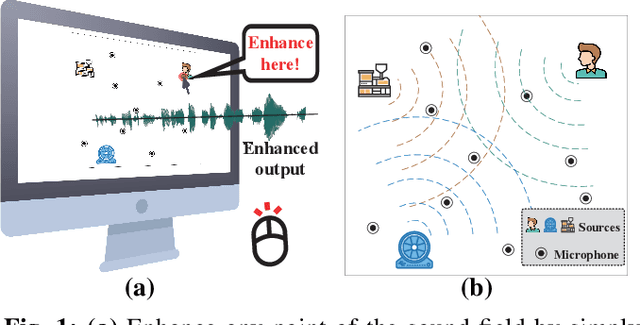
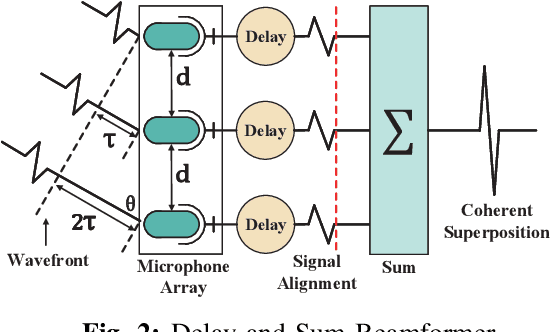
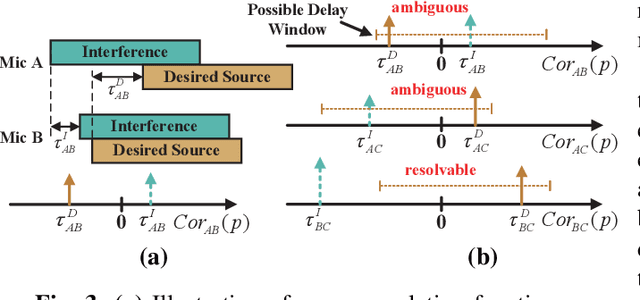
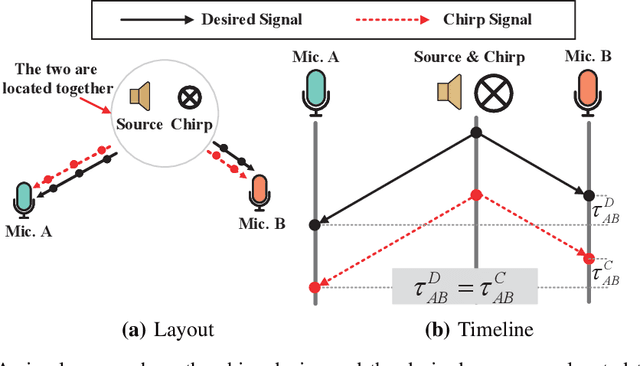
Acoustic signal acts as an essential input to many systems. However, the pure acoustic signal is very difficult to extract, especially in noisy environments. Existing beamforming systems are able to extract the signal transmitted from certain directions. However, since microphones are centrally deployed, these systems have limited coverage and low spatial resolution. We overcome the above limitations and present ChordMics, a distributed beamforming system. By leveraging the spatial diversity of the distributed microphones, ChordMics is able to extract the acoustic signal from arbitrary points. To realize such a system, we further address the fundamental challenge in distributed beamforming: aligning the signals captured by distributed and unsynchronized microphones. We implement ChordMics and evaluate its performance under both LOS and NLOS scenarios. The evaluation results tell that ChordMics can deliver higher SINR than the centralized microphone array. The average performance gain is up to 15dB.