 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM: Acoustic Inertial Measurement for Indoor Drone Localization and Tracking
Apr 02, 2025

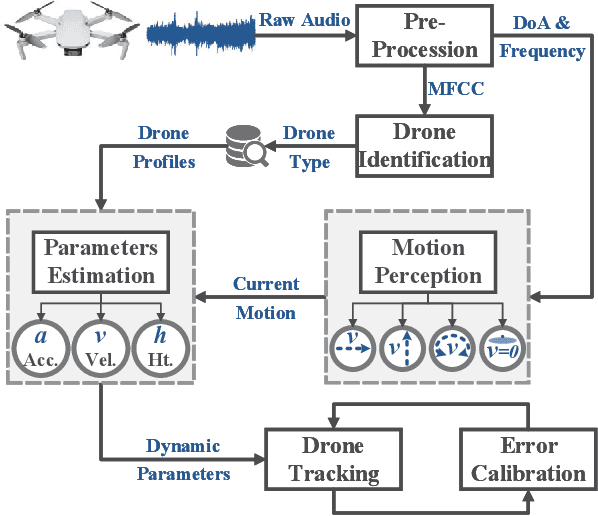
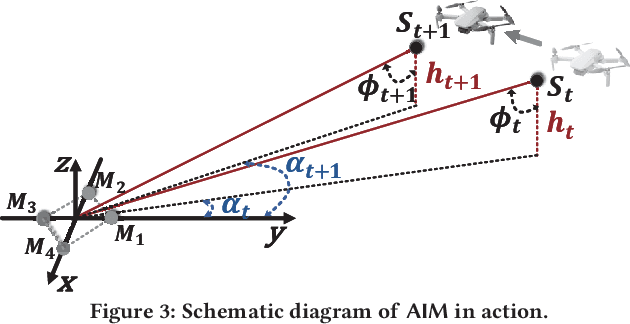
We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR). We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than commercial UWB-based systems in complex indoor scenarios, where state-of-the-art infrared systems would not even work because of NLoS settings. We further demonstrate that AIM can be extended to support indoor spaces with arbitrary ranges and layouts without loss of accuracy by deploying distributed microphone arrays.
Indoor Drone Localization and Tracking Based on Acoustic Inertial Measurement
Apr 01, 2025


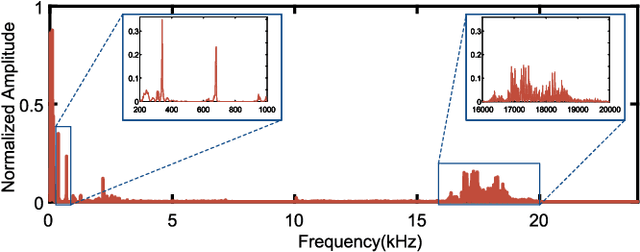
We present Acoustic Inertial Measurement (AIM), a one-of-a-kind technique for indoor drone localization and tracking. Indoor drone localization and tracking are arguably a crucial, yet unsolved challenge: in GPS-denied environments, existing approaches enjoy limited applicability, especially in Non-Line of Sight (NLoS), require extensive environment instrumentation, or demand considerable hardware/software changes on drones. In contrast, AIM exploits the acoustic characteristics of the drones to estimate their location and derive their motion, even in NLoS settings. We tame location estimation errors using a dedicated Kalman filter and the Interquartile Range rule (IQR) and demonstrate that AIM can support indoor spaces with arbitrary ranges and layouts. We implement AIM using an off-the-shelf microphone array and evaluate its performance with a commercial drone under varied settings. Results indicate that the mean localization error of AIM is 46% lower than that of commercial UWB-based systems in a complex 10m\times10m indoor scenario, where state-of-the-art infrared systems would not even work because of NLoS situations. When distributed microphone arrays are deployed, the mean error can be reduced to less than 0.5m in a 20m range, and even support spaces with arbitrary ranges and layouts.
How to Defend Against Large-scale Model Poisoning Attacks in Federated Learning: A Vertical Solution
Nov 16, 2024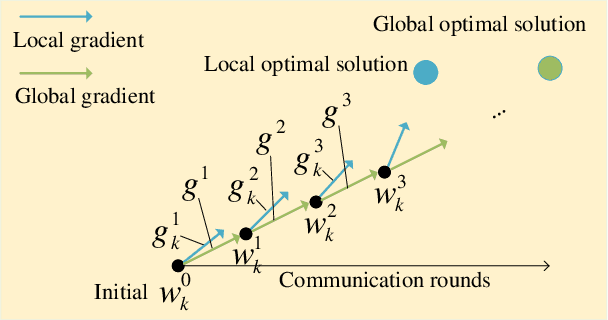

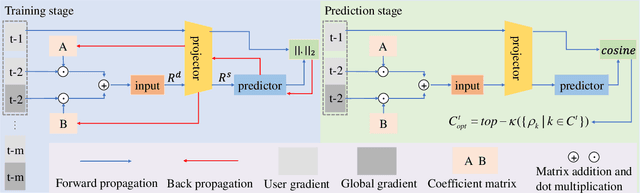
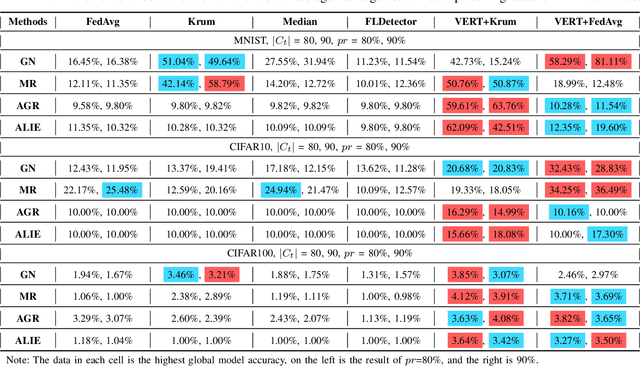
Federated learning (FL) is vulnerable to model poisoning attacks due to its distributed nature. The current defenses start from all user gradients (model updates) in each communication round and solve for the optimal aggregation gradients (horizontal solution). This horizontal solution will completely fail when facing large-scale (>50%) model poisoning attacks. In this work, based on the key insight that the convergence process of the model is a highly predictable process, we break away from the traditional horizontal solution of defense and innovatively transform the problem of solving the optimal aggregation gradients into a vertical solution problem. We propose VERT, which uses global communication rounds as the vertical axis, trains a predictor using historical gradients information to predict user gradients, and compares the similarity with actual user gradients to precisely and efficiently select the optimal aggregation gradients. In order to reduce the computational complexity of VERT, we design a low dimensional vector projector to project the user gradients to a computationally acceptable length, and then perform subsequent predictor training and prediction tasks. Exhaustive experiments show that VERT is efficient and scalable, exhibiting excellent large-scale (>=80%) model poisoning defense effects under different FL scenarios. In addition, we can design projector with different structures for different model structures to adapt to aggregation servers with different computing power.
HKTGNN: Hierarchical Knowledge Transferable Graph Neural Network-based Supply Chain Risk Assessment
Nov 07, 2023



The strength of a supply chain is an important measure of a country's or region's technical advancement and overall competitiveness. Establishing supply chain risk assessment models for effective management and mitigation of potential risks has become increasingly crucial. As the number of businesses grows, the important relationships become more complicated and difficult to measure. This emphasizes the need of extracting relevant information from graph data. Previously, academics mostly employed knowledge inference to increase the visibility of links between nodes in the supply chain. However, they have not solved the data hunger problem of single node feature characteristics. We propose a hierarchical knowledge transferable graph neural network-based (HKTGNN) supply chain risk assessment model to address these issues. Our approach is based on current graph embedding methods for assessing corporate investment risk assessment. We embed the supply chain network corresponding to individual goods in the supply chain using the graph embedding module, resulting in a directed homogeneous graph with just product nodes. This reduces the complicated supply chain network into a basic product network. It addresses difficulties using the domain difference knowledge transferable module based on centrality, which is presented by the premise that supply chain feature characteristics may be biased in the actual world. Meanwhile, the feature complement and message passing will alleviate the data hunger problem, which is driven by domain differences. Our model outperforms in experiments on a real-world supply chain dataset. We will give an equation to prove that our comparative experiment is both effective and fair.