 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboTracer: Mastering Spatial Trace with Reasoning in Vision-Language Models for Robotics
Dec 15, 2025Spatial tracing, as a fundamental embodied interaction ability for robots, is inherently challenging as it requires multi-step metric-grounded reasoning compounded with complex spatial referring and real-world metric measurement. However, existing methods struggle with this compositional task. To this end, we propose RoboTracer, a 3D-aware VLM that first achieves both 3D spatial referring and measuring via a universal spatial encoder and a regression-supervised decoder to enhance scale awareness during supervised fine-tuning (SFT). Moreover, RoboTracer advances multi-step metric-grounded reasoning via reinforcement fine-tuning (RFT) with metric-sensitive process rewards, supervising key intermediate perceptual cues to accurately generate spatial traces. To support SFT and RFT training, we introduce TraceSpatial, a large-scale dataset of 30M QA pairs, spanning outdoor/indoor/tabletop scenes and supporting complex reasoning processes (up to 9 steps). We further present TraceSpatial-Bench, a challenging benchmark filling the gap to evaluate spatial tracing. Experimental results show that RoboTracer surpasses baselines in spatial understanding, measuring, and referring, with an average success rate of 79.1%, and also achieves SOTA performance on TraceSpatial-Bench by a large margin, exceeding Gemini-2.5-Pro by 36% accuracy. Notably, RoboTracer can be integrated with various control policies to execute long-horizon, dynamic tasks across diverse robots (UR5, G1 humanoid) in cluttered real-world scenes.
Enhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Mar 16, 2025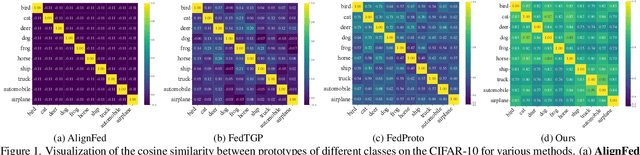
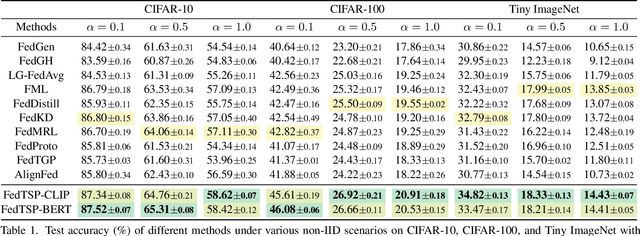
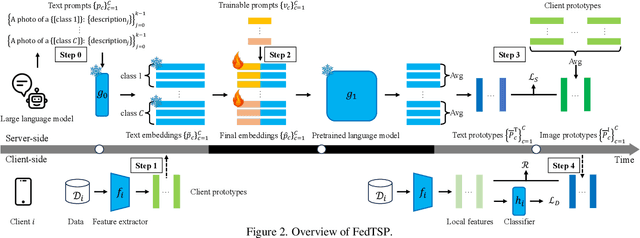
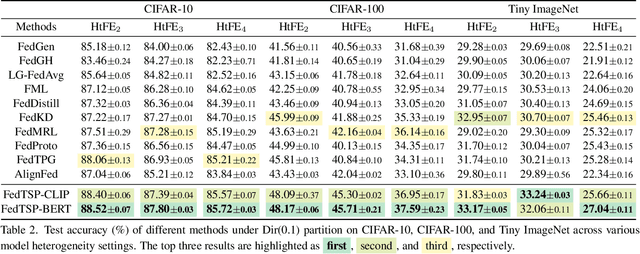
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.
REGNet V2: End-to-End REgion-based Grasp Detection Network for Grippers of Different Sizes in Point Clouds
Oct 12, 2024



Grasping has been a crucial but challenging problem in robotics for many years. One of the most important challenges is how to make grasping generalizable and robust to novel objects as well as grippers in unstructured environments. We present \regnet, a robotic grasping system that can adapt to different parallel jaws to grasp diversified objects. To support different grippers, \regnet embeds the gripper parameters into point clouds, based on which it predicts suitable grasp configurations. It includes three components: Score Network (SN), Grasp Region Network (GRN), and Refine Network (RN). In the first stage, SN is used to filter suitable points for grasping by grasp confidence scores. In the second stage, based on the selected points, GRN generates a set of grasp proposals. Finally, RN refines the grasp proposals for more accurate and robust predictions. We devise an analytic policy to choose the optimal grasp to be executed from the predicted grasp set. To train \regnet, we construct a large-scale grasp dataset containing collision-free grasp configurations using different parallel-jaw grippers. The experimental results demonstrate that \regnet with the analytic policy achieves the highest success rate of $74.98\%$ in real-world clutter scenes with $20$ objects, significantly outperforming several state-of-the-art methods, including GPD, PointNetGPD, and S4G. The code and dataset are available at https://github.com/zhaobinglei/REGNet-V2.
DualFed: Enjoying both Generalization and Personalization in Federated Learning via Hierachical Representations
Jul 25, 2024



In personalized federated learning (PFL), it is widely recognized that achieving both high model generalization and effective personalization poses a significant challenge due to their conflicting nature. As a result, existing PFL methods can only manage a trade-off between these two objectives. This raises an interesting question: Is it feasible to develop a model capable of achieving both objectives simultaneously? Our paper presents an affirmative answer, and the key lies in the observation that deep models inherently exhibit hierarchical architectures, which produce representations with various levels of generalization and personalization at different stages. A straightforward approach stemming from this observation is to select multiple representations from these layers and combine them to concurrently achieve generalization and personalization. However, the number of candidate representations is commonly huge, which makes this method infeasible due to high computational costs.To address this problem, we propose DualFed, a new method that can directly yield dual representations correspond to generalization and personalization respectively, thereby simplifying the optimization task. Specifically, DualFed inserts a personalized projection network between the encoder and classifier. The pre-projection representations are able to capture generalized information shareable across clients, and the post-projection representations are effective to capture task-specific information on local clients. This design minimizes the mutual interference between generalization and personalization, thereby achieving a win-win situation. Extensive experiments show that DualFed can outperform other FL methods. Code is available at https://github.com/GuogangZhu/DualFed.
MMRDN: Consistent Representation for Multi-View Manipulation Relationship Detection in Object-Stacked Scenes
Apr 25, 2023Manipulation relationship detection (MRD) aims to guide the robot to grasp objects in the right order, which is important to ensure the safety and reliability of grasping in object stacked scenes. Previous works infer manipulation relationship by deep neural network trained with data collected from a predefined view, which has limitation in visual dislocation in unstructured environments. Multi-view data provide more comprehensive information in space, while a challenge of multi-view MRD is domain shift. In this paper, we propose a novel multi-view fusion framework, namely multi-view MRD network (MMRDN), which is trained by 2D and 3D multi-view data. We project the 2D data from different views into a common hidden space and fit the embeddings with a set of Von-Mises-Fisher distributions to learn the consistent representations. Besides, taking advantage of position information within the 3D data, we select a set of $K$ Maximum Vertical Neighbors (KMVN) points from the point cloud of each object pair, which encodes the relative position of these two objects. Finally, the features of multi-view 2D and 3D data are concatenated to predict the pairwise relationship of objects. Experimental results on the challenging REGRAD dataset show that MMRDN outperforms the state-of-the-art methods in multi-view MRD tasks. The results also demonstrate that our model trained by synthetic data is capable to transfer to real-world scenarios.