 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Representation with Textual Semantics: Textual Semantics-Powered Prototypes for Heterogeneous Federated Learning
Paper and Code
Mar 16, 2025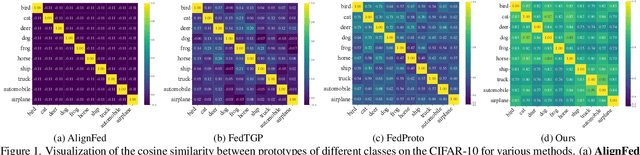
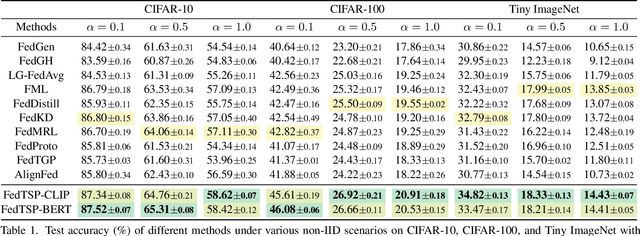
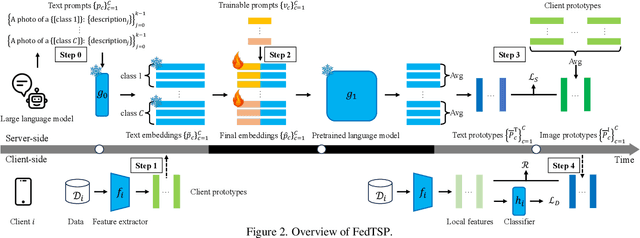
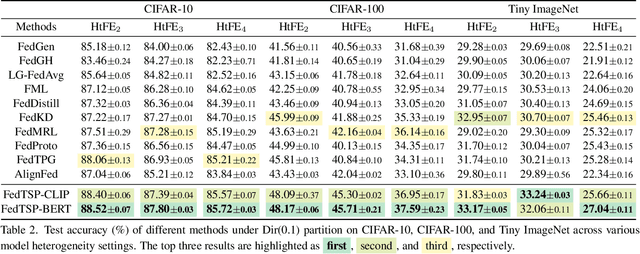
Federated Prototype Learning (FedPL) has emerged as an effective strategy for handling data heterogeneity in Federated Learning (FL). In FedPL, clients collaboratively construct a set of global feature centers (prototypes), and let local features align with these prototypes to mitigate the effects of data heterogeneity. The performance of FedPL highly depends on the quality of prototypes. Existing methods assume that larger inter-class distances among prototypes yield better performance, and thus design different methods to increase these distances. However, we observe that while these methods increase prototype distances to enhance class discrimination, they inevitably disrupt essential semantic relationships among classes, which are crucial for model generalization. This raises an important question: how to construct prototypes that inherently preserve semantic relationships among classes? Directly learning these relationships from limited and heterogeneous client data can be problematic in FL. Recently, the success of pre-trained language models (PLMs) demonstrates their ability to capture semantic relationships from vast textual corpora. Motivated by this, we propose FedTSP, a novel method that leverages PLMs to construct semantically enriched prototypes from the textual modality, enabling more effective collaboration in heterogeneous data settings. We first use a large language model (LLM) to generate fine-grained textual descriptions for each class, which are then processed by a PLM on the server to form textual prototypes. To address the modality gap between client image models and the PLM, we introduce trainable prompts, allowing prototypes to adapt better to client tasks. Extensive experiments demonstrate that FedTSP mitigates data heterogeneity while significantly accelerating convergence.