 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Orientation and Weight Optimization for Robust Watertight Surface Reconstruction via Dirichlet-Regularized Winding Fields
Feb 14, 2026We propose Dirichlet Winding Reconstruction (DiWR), a robust method for reconstructing watertight surfaces from unoriented point clouds with non-uniform sampling, noise, and outliers. Our method uses the generalized winding number (GWN) field as the target implicit representation and jointly optimizes point orientations, per-point area weights, and confidence coefficients in a single pipeline. The optimization minimizes the Dirichlet energy of the induced winding field together with additional GWN-based constraints, allowing DiWR to compensate for non-uniform sampling, reduce the impact of noise, and downweight outliers during reconstruction, with no reliance on separate preprocessing. We evaluate DiWR on point clouds from 3D Gaussian Splatting, a computer-vision pipeline, and corrupted graphics benchmarks. Experiments show that DiWR produces plausible watertight surfaces on these challenging inputs and outperforms both traditional multi-stage pipelines and recent joint orientation-reconstruction methods.
MonoCloth: Reconstruction and Animation of Cloth-Decoupled Human Avatars from Monocular Videos
Aug 06, 2025



Reconstructing realistic 3D human avatars from monocular videos is a challenging task due to the limited geometric information and complex non-rigid motion involved. We present MonoCloth, a new method for reconstructing and animating clothed human avatars from monocular videos. To overcome the limitations of monocular input, we introduce a part-based decomposition strategy that separates the avatar into body, face, hands, and clothing. This design reflects the varying levels of reconstruction difficulty and deformation complexity across these components. Specifically, we focus on detailed geometry recovery for the face and hands. For clothing, we propose a dedicated cloth simulation module that captures garment deformation using temporal motion cues and geometric constraints. Experimental results demonstrate that MonoCloth improves both visual reconstruction quality and animation realism compared to existing methods. Furthermore, thanks to its part-based design, MonoCloth also supports additional tasks such as clothing transfer, underscoring its versatility and practical utility.
Large Motion Model for Unified Multi-Modal Motion Generation
Apr 01, 2024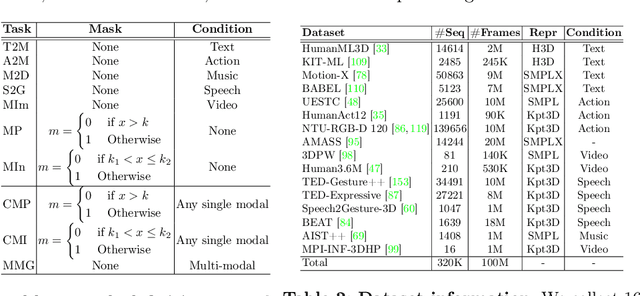
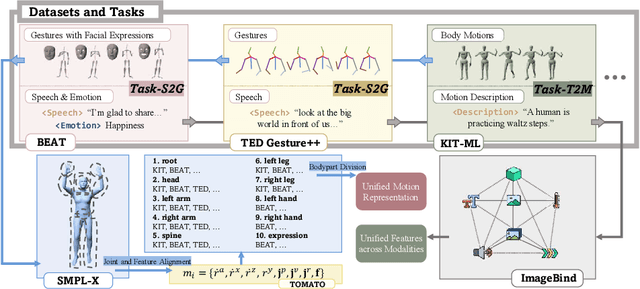
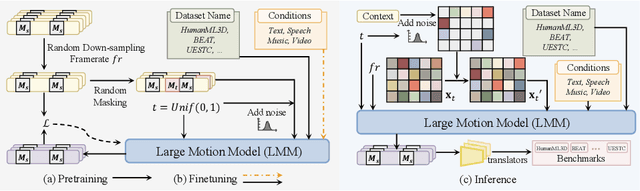
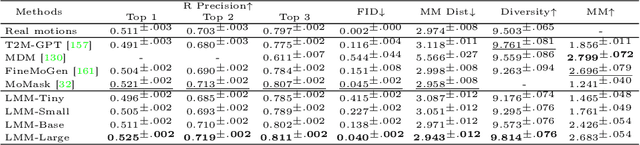
Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.
Robust Geometry and Reflectance Disentanglement for 3D Face Reconstruction from Sparse-view Images
Dec 11, 2023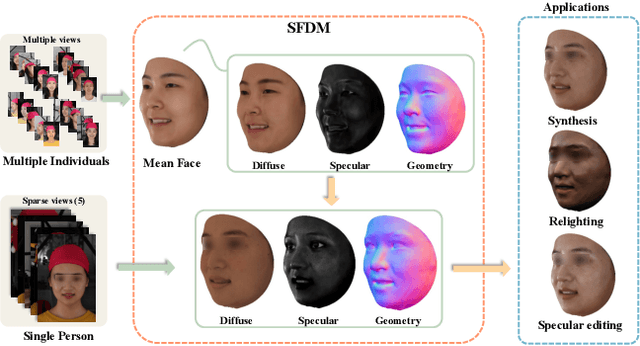
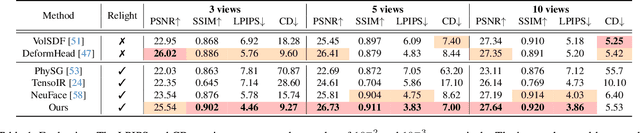
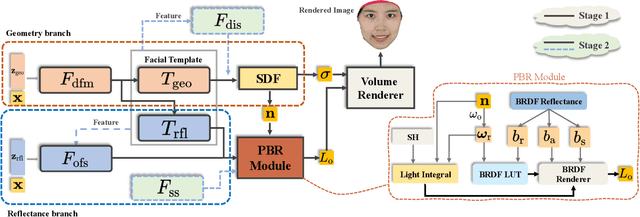
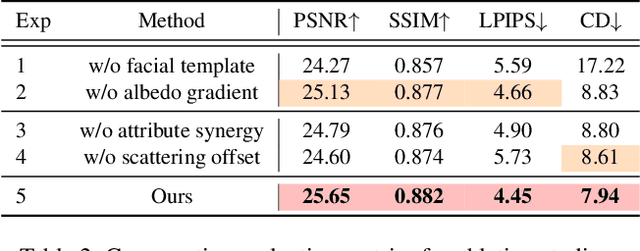
This paper presents a novel two-stage approach for reconstructing human faces from sparse-view images, a task made challenging by the unique geometry and complex skin reflectance of each individual. Our method focuses on decomposing key facial attributes, including geometry, diffuse reflectance, and specular reflectance, from ambient light. Initially, we create a general facial template from a diverse collection of individual faces, capturing essential geometric and reflectance characteristics. Guided by this template, we refine each specific face model in the second stage, which further considers the interaction between geometry and reflectance, as well as the subsurface scattering effects on facial skin. Our method enables the reconstruction of high-quality facial representations from as few as three images, offering improved geometric accuracy and reflectance detail. Through comprehensive evaluations and comparisons, our method demonstrates superiority over existing techniques. Our method effectively disentangles geometry and reflectance components, leading to enhanced quality in synthesizing new views and opening up possibilities for applications such as relighting and reflectance editing. We will make the code publicly available.
Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
Jun 18, 2021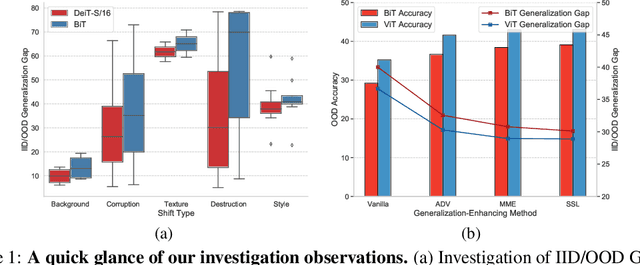
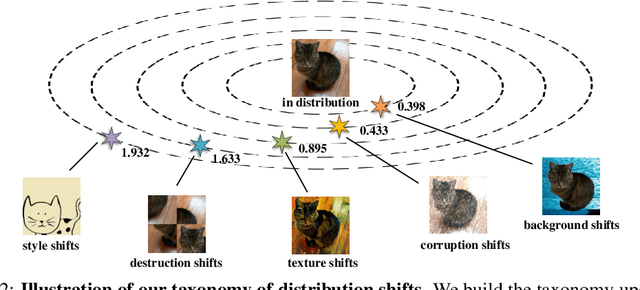

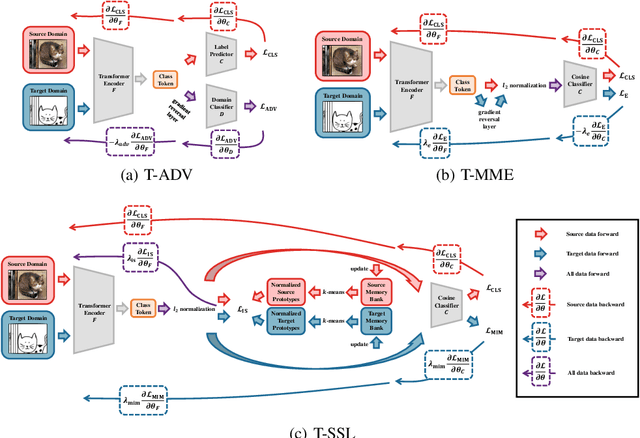
Recently, Vision Transformers (ViTs) have achieved impressive results on various vision tasks. Yet, their generalization ability under different distribution shifts is rarely understood. In this work, we provide a comprehensive study on the out-of-distribution generalization of ViTs. To support a systematic investigation, we first present a taxonomy of distribution shifts by categorizing them into five conceptual groups: corruption shift, background shift, texture shift, destruction shift, and style shift. Then we perform extensive evaluations of ViT variants under different groups of distribution shifts and compare their generalization ability with CNNs. Several important observations are obtained: 1) ViTs generalize better than CNNs under multiple distribution shifts. With the same or fewer parameters, ViTs are ahead of corresponding CNNs by more than 5% in top-1 accuracy under most distribution shifts. 2) Larger ViTs gradually narrow the in-distribution and out-of-distribution performance gap. To further improve the generalization of ViTs, we design the Generalization-Enhanced ViTs by integrating adversarial learning, information theory, and self-supervised learning. By investigating three types of generalization-enhanced ViTs, we observe their gradient-sensitivity and design a smoother learning strategy to achieve a stable training process. With modified training schemes, we achieve improvements on performance towards out-of-distribution data by 4% from vanilla ViTs. We comprehensively compare three generalization-enhanced ViTs with their corresponding CNNs, and observe that: 1) For the enhanced model, larger ViTs still benefit more for the out-of-distribution generalization. 2) generalization-enhanced ViTs are more sensitive to the hyper-parameters than corresponding CNNs. We hope our comprehensive study could shed light on the design of more generalizable learning architectures.
Towards Overcoming False Positives in Visual Relationship Detection
Dec 24, 2020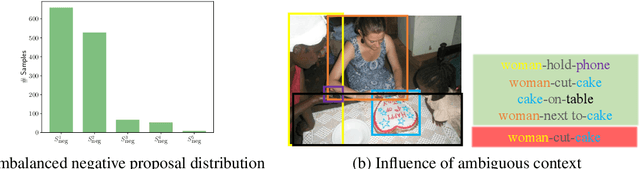
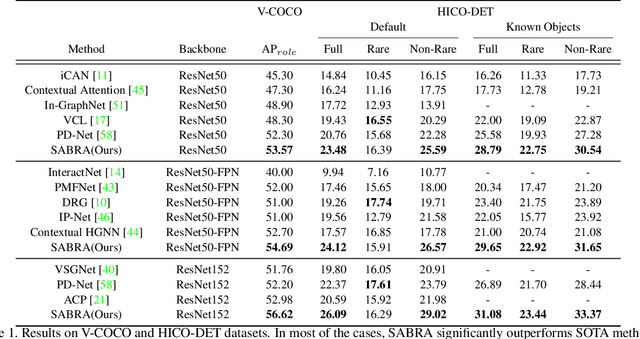
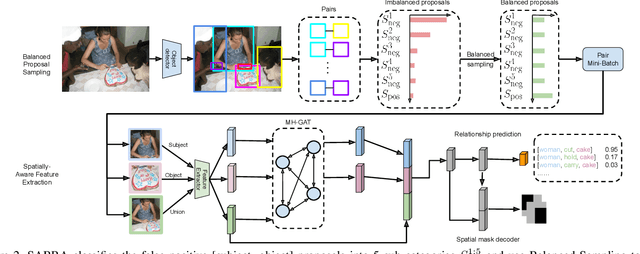
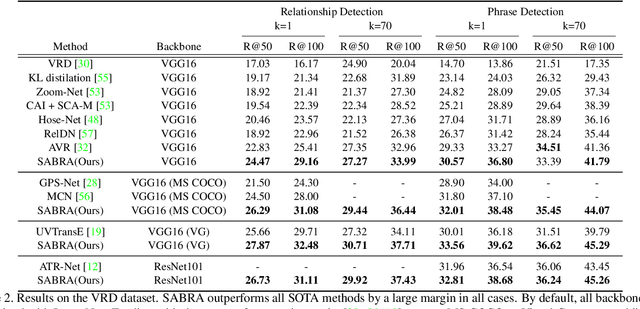
In this paper, we investigate the cause of the high false positive rate in Visual Relationship Detection (VRD). We observe that during training, the relationship proposal distribution is highly imbalanced: most of the negative relationship proposals are easy to identify, e.g., the inaccurate object detection, which leads to the under-fitting of low-frequency difficult proposals. This paper presents Spatially-Aware Balanced negative pRoposal sAmpling (SABRA), a robust VRD framework that alleviates the influence of false positives. To effectively optimize the model under imbalanced distribution, SABRA adopts Balanced Negative Proposal Sampling (BNPS) strategy for mini-batch sampling. BNPS divides proposals into 5 well defined sub-classes and generates a balanced training distribution according to the inverse frequency. BNPS gives an easier optimization landscape and significantly reduces the number of false positives. To further resolve the low-frequency challenging false positive proposals with high spatial ambiguity, we improve the spatial modeling ability of SABRA on two aspects: a simple and efficient multi-head heterogeneous graph attention network (MH-GAT) that models the global spatial interactions of objects, and a spatial mask decoder that learns the local spatial configuration. SABRA outperforms SOTA methods by a large margin on two human-object interaction (HOI) datasets and one general VRD dataset.