 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-Guided Image Person Removal with Data Synthesis
Sep 29, 2022
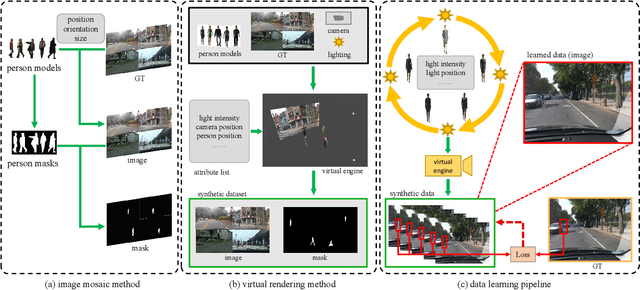
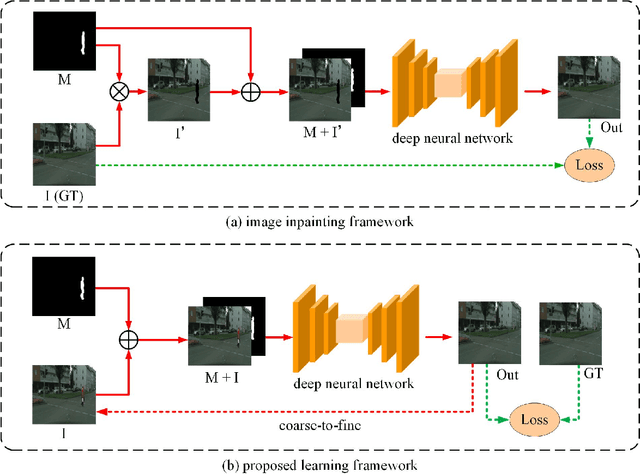

As a special case of common object removal, image person removal is playing an increasingly important role in social media and criminal investigation domains. Due to the integrity of person area and the complexity of human posture, person removal has its own dilemmas. In this paper, we propose a novel idea to tackle these problems from the perspective of data synthesis. Concerning the lack of dedicated dataset for image person removal, two dataset production methods are proposed to automatically generate images, masks and ground truths respectively. Then, a learning framework similar to local image degradation is proposed so that the masks can be used to guide the feature extraction process and more texture information can be gathered for final prediction. A coarse-to-fine training strategy is further applied to refine the details. The data synthesis and learning framework combine well with each other. Experimental results verify the effectiveness of our method quantitatively and qualitatively, and the trained network proves to have good generalization ability either on real or synthetic images.
Exemplar-Based Image Colorization with A Learning Framework
Sep 13, 2022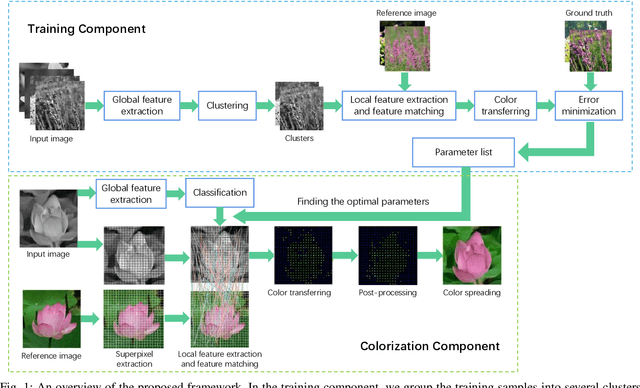



Image learning and colorization are hot spots in multimedia domain. Inspired by the learning capability of humans, in this paper, we propose an automatic colorization method with a learning framework. This method can be viewed as a hybrid of exemplar-based and learning-based method, and it decouples the colorization process and learning process so as to generate various color styles for the same gray image. The matching process in the exemplar-based colorization method can be regarded as a parameterized function, and we employ a large amount of color images as the training samples to fit the parameters. During the training process, the color images are the ground truths, and we learn the optimal parameters for the matching process by minimizing the errors in terms of the parameters for the matching function. To deal with images with various compositions, a global feature is introduced, which can be used to classify the images with respect to their compositions, and then learn the optimal matching parameters for each image category individually. What's more, a spatial consistency based post-processing is design to smooth the extracted color information from the reference image to remove matching errors. Extensive experiments are conducted to verify the effectiveness of the method, and it achieves comparable performance against the state-of-the-art colorization algorithms.
Cooperative trajectory planning algorithm of USV-UAV with hull dynamic constraints
Sep 07, 2022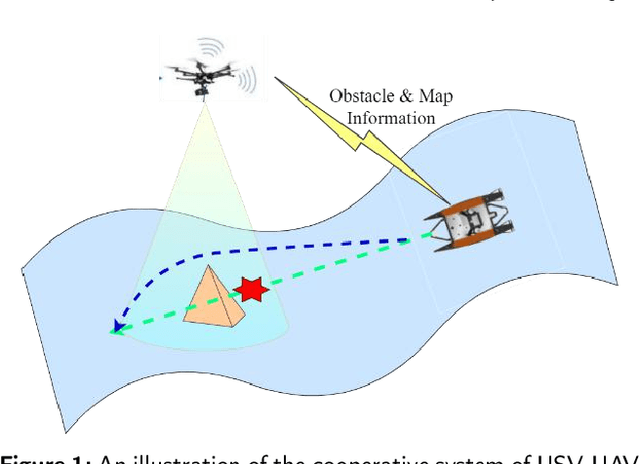

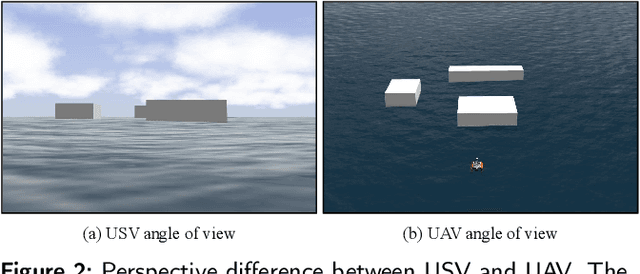
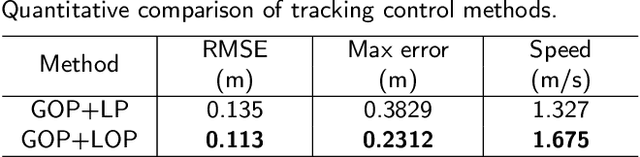
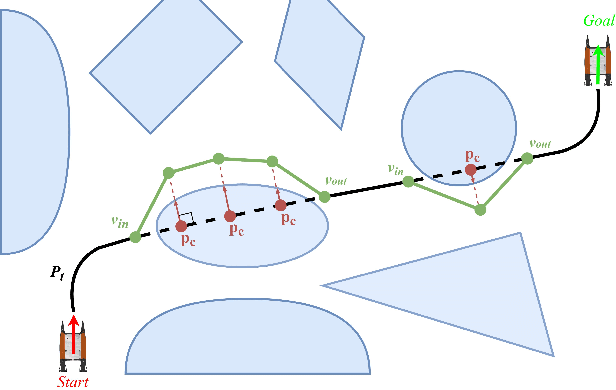
Efficient trajectory generation in complex dynamic environment stills remains an open problem in the unmanned surface vehicle (USV) domain. In this paper, a cooperative trajectory planning algorithm for the coupled USV-UAV system is proposed, to ensure that USV can execute safe and smooth path in the process of autonomous advance in multi obstacle maps. Specifically, the unmanned aerial vehicle (UAV) plays the role as a flight sensor, and it provides real-time global map and obstacle information with lightweight semantic segmentation network and 3D projection transformation. And then an initial obstacle avoidance trajectory is generated by a graph-based search method. Concerning the unique under-actuated kinematic characteristics of the USV, a numerical optimization method based on hull dynamic constraints is introduced to make the trajectory easier to be tracked for motion control. Finally, a motion control method based on NMPC with the lowest energy consumption constraint during execution is proposed. Experimental results verify the effectiveness of whole system, and the generated trajectory is locally optimal for USV with considerable tracking accuracy.
Efficient Trajectory Planning and Control for USV with Vessel Dynamics and Differential Flatness
Sep 07, 2022
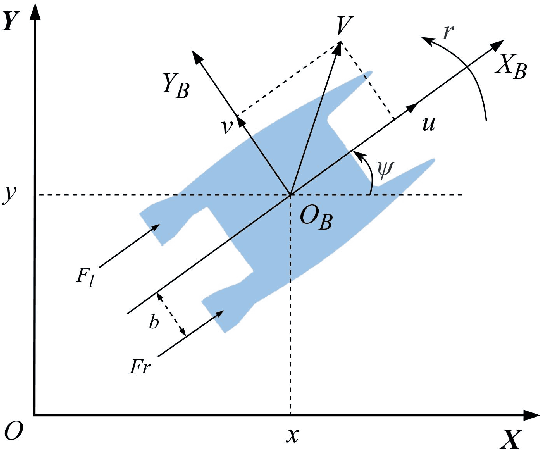
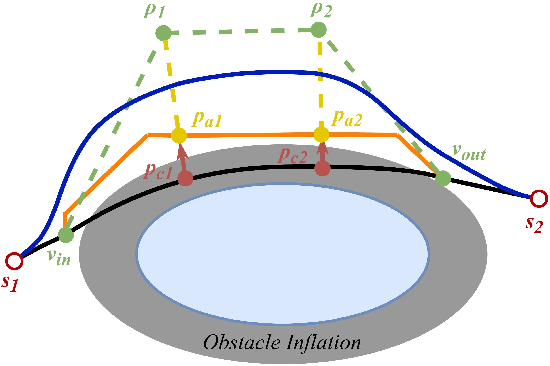
Unmanned surface vessels (USVs) are widely used in ocean exploration and environmental protection fields. To ensure that USV can successfully perform its mission, trajectory planning and motion tracking are the two most critical technologies. In this paper, we propose a novel trajectory generation and tracking method for USV based on optimization theory. Specifically, the USV dynamic model is described with differential flatness, so that the trajectory can be generated by dynamic RRT* in a linear invariant system expression form under the objective of optimal boundary value. To reduce the sample number and improve efficiency, we adjust the trajectory through local optimization. The dynamic constraints are considered in the optimization process so that the generated trajectory conforms to the kinematic characteristics of the under-actuated hull, and makes it easier to be tracked. Finally, motion tracking is added with model predictive control under a sequential quadratic programming problem. Experimental results show the planned trajectory is more in line with the kinematic characteristics of USV, and the tracking accuracy remains a higher level.
Learning to simulate complex scenes
Jun 25, 2020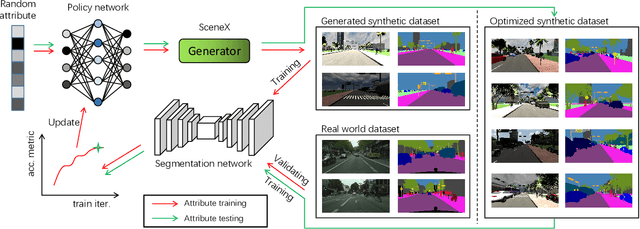


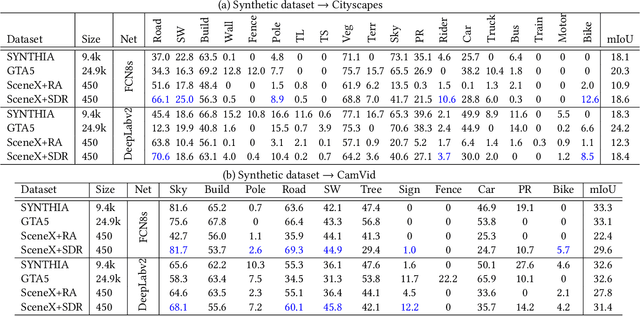
Data simulation engines like Unity are becoming an increasingly important data source that allows us to acquire ground truth labels conveniently. Moreover, we can flexibly edit the content of an image in the engine, such as objects (position, orientation) and environments (illumination, occlusion). When using simulated data as training sets, its editable content can be leveraged to mimic the distribution of real-world data, and thus reduce the content difference between the synthetic and real domains. This paper explores content adaptation in the context of semantic segmentation, where the complex street scenes are fully synthesized using 19 classes of virtual objects from a first person driver perspective and controlled by 23 attributes. To optimize the attribute values and obtain a training set of similar content to real-world data, we propose a scalable discretization-and-relaxation (SDR) approach. Under a reinforcement learning framework, we formulate attribute optimization as a random-to-optimized mapping problem using a neural network. Our method has three characteristics. 1) Instead of editing attributes of individual objects, we focus on global attributes that have large influence on the scene structure, such as object density and illumination. 2) Attributes are quantized to discrete values, so as to reduce search space and training complexity. 3) Correlated attributes are jointly optimized in a group, so as to avoid meaningless scene structures and find better convergence points. Experiment shows our system can generate reasonable and useful scenes, from which we obtain promising real-world segmentation accuracy compared with existing synthetic training sets.