 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple imputation using chained random forests: a preliminary study based on the empirical distribution of out-of-bag prediction errors
Apr 30, 2020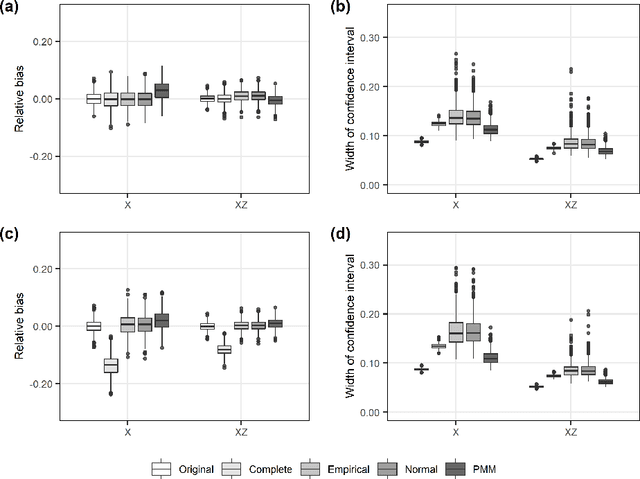
Missing data are common in data analyses in biomedical fields, and imputation methods based on random forests (RF) have become widely accepted, as the RF algorithm can achieve high accuracy without the need for specification of data distributions or relationships. However, the predictions from RF do not contain information about prediction uncertainty, which was unacceptable for multiple imputation. Available RF-based multiple imputation methods tried to do proper multiple imputation either by sampling directly from observations under predicting nodes without accounting for the prediction error or by making normality assumption about the prediction error distribution. In this study, a novel RF-based multiple imputation method was proposed by constructing conditional distributions the empirical distribution of out-of-bag prediction errors. The proposed method was compared with previous method with parametric assumptions about RF's prediction errors and predictive mean matching based on simulation studies on data with presence of interaction term. The proposed non-parametric method can deliver valid multiple imputation results. The accompanying R package for this study is publicly available.
Influence of parallel computing strategies of iterative imputation of missing data: a case study on missForest
Apr 23, 2020



Machine learning iterative imputation methods have been well accepted by researchers for imputing missing data, but they can be time-consuming when handling large datasets. To overcome this drawback, parallel computing strategies have been proposed but their impact on imputation results and subsequent statistical analyses are relatively unknown. This study examines the two parallel strategies (variable-wise distributed computation and model-wise distributed computation) implemented in the random-forest imputation method, missForest. Results from the simulation experiments showed that the two parallel strategies can influence both the imputation process and the final imputation results differently. Specifically, even though both strategies produced similar normalized root mean squared prediction errors, the variable-wise distributed strategy led to additional biases when estimating the mean and inter-correlation of the covariates and their regression coefficients.