 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-LLaMAv2 and MMEVerse: A New Framework and Benchmark for Multimodal Emotion Understanding
Jan 23, 2026Understanding human emotions from multimodal signals poses a significant challenge in affective computing and human-robot interaction. While multimodal large language models (MLLMs) have excelled in general vision-language tasks, their capabilities in emotional reasoning remain limited. The field currently suffers from a scarcity of large-scale datasets with high-quality, descriptive emotion annotations and lacks standardized benchmarks for evaluation. Our preliminary framework, Emotion-LLaMA, pioneered instruction-tuned multimodal learning for emotion reasoning but was restricted by explicit face detectors, implicit fusion strategies, and low-quality training data with limited scale. To address these limitations, we present Emotion-LLaMAv2 and the MMEVerse benchmark, establishing an end-to-end pipeline together with a standardized evaluation setting for emotion recognition and reasoning. Emotion-LLaMAv2 introduces three key advances. First, an end-to-end multiview encoder eliminates external face detection and captures nuanced emotional cues via richer spatial and temporal multiview tokens. Second, a Conv Attention pre-fusion module is designed to enable simultaneous local and global multimodal feature interactions external to the LLM backbone. Third, a perception-to-cognition curriculum instruction tuning scheme within the LLaMA2 backbone unifies emotion recognition and free-form emotion reasoning. To support large-scale training and reproducible evaluation, MMEVerse aggregates twelve publicly available emotion datasets, including IEMOCAP, MELD, DFEW, and MAFW, into a unified multimodal instruction format. The data are re-annotated via a multi-agent pipeline involving Qwen2 Audio, Qwen2.5 VL, and GPT 4o, producing 130k training clips and 36k testing clips across 18 evaluation benchmarks.
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Dec 18, 2025Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6x acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6x speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
PersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
Aug 11, 2025Current diffusion models for audio-driven avatar video generation struggle to synthesize long videos with natural audio synchronization and identity consistency. This paper presents StableAvatar, the first end-to-end video diffusion transformer that synthesizes infinite-length high-quality videos without post-processing. Conditioned on a reference image and audio, StableAvatar integrates tailored training and inference modules to enable infinite-length video generation. We observe that the main reason preventing existing models from generating long videos lies in their audio modeling. They typically rely on third-party off-the-shelf extractors to obtain audio embeddings, which are then directly injected into the diffusion model via cross-attention. Since current diffusion backbones lack any audio-related priors, this approach causes severe latent distribution error accumulation across video clips, leading the latent distribution of subsequent segments to drift away from the optimal distribution gradually. To address this, StableAvatar introduces a novel Time-step-aware Audio Adapter that prevents error accumulation via time-step-aware modulation. During inference, we propose a novel Audio Native Guidance Mechanism to further enhance the audio synchronization by leveraging the diffusion's own evolving joint audio-latent prediction as a dynamic guidance signal. To enhance the smoothness of the infinite-length videos, we introduce a Dynamic Weighted Sliding-window Strategy that fuses latent over time. Experiments on benchmarks show the effectiveness of StableAvatar both qualitatively and quantitatively.
StableAnimator: High-Quality Identity-Preserving Human Image Animation
Nov 26, 2024Current diffusion models for human image animation struggle to ensure identity (ID) consistency. This paper presents StableAnimator, the first end-to-end ID-preserving video diffusion framework, which synthesizes high-quality videos without any post-processing, conditioned on a reference image and a sequence of poses. Building upon a video diffusion model, StableAnimator contains carefully designed modules for both training and inference striving for identity consistency. In particular, StableAnimator begins by computing image and face embeddings with off-the-shelf extractors, respectively and face embeddings are further refined by interacting with image embeddings using a global content-aware Face Encoder. Then, StableAnimator introduces a novel distribution-aware ID Adapter that prevents interference caused by temporal layers while preserving ID via alignment. During inference, we propose a novel Hamilton-Jacobi-Bellman (HJB) equation-based optimization to further enhance the face quality. We demonstrate that solving the HJB equation can be integrated into the diffusion denoising process, and the resulting solution constrains the denoising path and thus benefits ID preservation. Experiments on multiple benchmarks show the effectiveness of StableAnimator both qualitatively and quantitatively.
SZTU-CMU at MER2024: Improving Emotion-LLaMA with Conv-Attention for Multimodal Emotion Recognition
Aug 21, 2024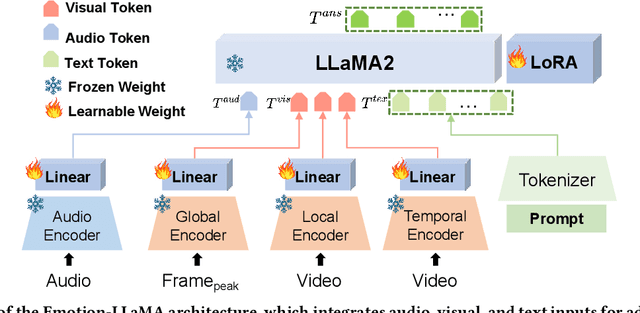



This paper presents our winning approach for the MER-NOISE and MER-OV tracks of the MER2024 Challenge on multimodal emotion recognition. Our system leverages the advanced emotional understanding capabilities of Emotion-LLaMA to generate high-quality annotations for unlabeled samples, addressing the challenge of limited labeled data. To enhance multimodal fusion while mitigating modality-specific noise, we introduce Conv-Attention, a lightweight and efficient hybrid framework. Extensive experimentation vali-dates the effectiveness of our approach. In the MER-NOISE track, our system achieves a state-of-the-art weighted average F-score of 85.30%, surpassing the second and third-place teams by 1.47% and 1.65%, respectively. For the MER-OV track, our utilization of Emotion-LLaMA for open-vocabulary annotation yields an 8.52% improvement in average accuracy and recall compared to GPT-4V, securing the highest score among all participating large multimodal models. The code and model for Emotion-LLaMA are available at https://github.com/ZebangCheng/Emotion-LLaMA.
MotionFollower: Editing Video Motion via Lightweight Score-Guided Diffusion
May 30, 2024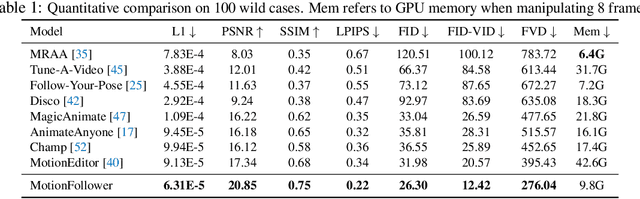
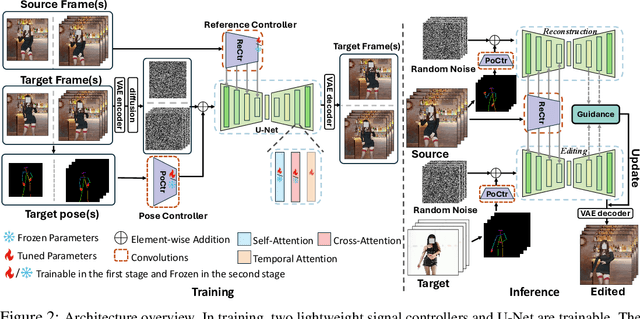
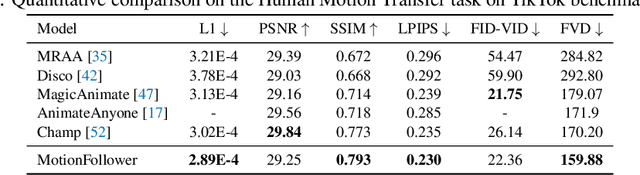

Despite impressive advancements in diffusion-based video editing models in altering video attributes, there has been limited exploration into modifying motion information while preserving the original protagonist's appearance and background. In this paper, we propose MotionFollower, a lightweight score-guided diffusion model for video motion editing. To introduce conditional controls to the denoising process, MotionFollower leverages two of our proposed lightweight signal controllers, one for poses and the other for appearances, both of which consist of convolution blocks without involving heavy attention calculations. Further, we design a score guidance principle based on a two-branch architecture, including the reconstruction and editing branches, which significantly enhance the modeling capability of texture details and complicated backgrounds. Concretely, we enforce several consistency regularizers and losses during the score estimation. The resulting gradients thus inject appropriate guidance to the intermediate latents, forcing the model to preserve the original background details and protagonists' appearances without interfering with the motion modification. Experiments demonstrate the competitive motion editing ability of MotionFollower qualitatively and quantitatively. Compared with MotionEditor, the most advanced motion editing model, MotionFollower achieves an approximately 80% reduction in GPU memory while delivering superior motion editing performance and exclusively supporting large camera movements and actions.
MotionEditor: Editing Video Motion via Content-Aware Diffusion
Nov 30, 2023



Existing diffusion-based video editing models have made gorgeous advances for editing attributes of a source video over time but struggle to manipulate the motion information while preserving the original protagonist's appearance and background. To address this, we propose MotionEditor, a diffusion model for video motion editing. MotionEditor incorporates a novel content-aware motion adapter into ControlNet to capture temporal motion correspondence. While ControlNet enables direct generation based on skeleton poses, it encounters challenges when modifying the source motion in the inverted noise due to contradictory signals between the noise (source) and the condition (reference). Our adapter complements ControlNet by involving source content to transfer adapted control signals seamlessly. Further, we build up a two-branch architecture (a reconstruction branch and an editing branch) with a high-fidelity attention injection mechanism facilitating branch interaction. This mechanism enables the editing branch to query the key and value from the reconstruction branch in a decoupled manner, making the editing branch retain the original background and protagonist appearance. We also propose a skeleton alignment algorithm to address the discrepancies in pose size and position. Experiments demonstrate the promising motion editing ability of MotionEditor, both qualitatively and quantitatively.
Implicit Temporal Modeling with Learnable Alignment for Video Recognition
Apr 20, 2023



Contrastive language-image pretraining (CLIP) has demonstrated remarkable success in various image tasks. However, how to extend CLIP with effective temporal modeling is still an open and crucial problem. Existing factorized or joint spatial-temporal modeling trades off between the efficiency and performance. While modeling temporal information within straight through tube is widely adopted in literature, we find that simple frame alignment already provides enough essence without temporal attention. To this end, in this paper, we proposed a novel Implicit Learnable Alignment (ILA) method, which minimizes the temporal modeling effort while achieving incredibly high performance. Specifically, for a frame pair, an interactive point is predicted in each frame, serving as a mutual information rich region. By enhancing the features around the interactive point, two frames are implicitly aligned. The aligned features are then pooled into a single token, which is leveraged in the subsequent spatial self-attention. Our method allows eliminating the costly or insufficient temporal self-attention in video. Extensive experiments on benchmarks demonstrate the superiority and generality of our module. Particularly, the proposed ILA achieves a top-1 accuracy of 88.7% on Kinetics-400 with much fewer FLOPs compared with Swin-L and ViViT-H. Code is released at https://github.com/Francis-Rings/ILA .