 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Qwen: Training Hybrid Experts for Unified Emotion and General Vision-Language Understanding
May 10, 2025Emotion understanding in videos aims to accurately recognize and interpret individuals' emotional states by integrating contextual, visual, textual, and auditory cues. While Large Multimodal Models (LMMs) have demonstrated significant progress in general vision-language (VL) tasks, their performance in emotion-specific scenarios remains limited. Moreover, fine-tuning LMMs on emotion-related tasks often leads to catastrophic forgetting, hindering their ability to generalize across diverse tasks. To address these challenges, we present Emotion-Qwen, a tailored multimodal framework designed to enhance both emotion understanding and general VL reasoning. Emotion-Qwen incorporates a sophisticated Hybrid Compressor based on the Mixture of Experts (MoE) paradigm, which dynamically routes inputs to balance emotion-specific and general-purpose processing. The model is pre-trained in a three-stage pipeline on large-scale general and emotional image datasets to support robust multimodal representations. Furthermore, we construct the Video Emotion Reasoning (VER) dataset, comprising more than 40K bilingual video clips with fine-grained descriptive annotations, to further enrich Emotion-Qwen's emotional reasoning capability. Experimental results demonstrate that Emotion-Qwen achieves state-of-the-art performance on multiple emotion recognition benchmarks, while maintaining competitive results on general VL tasks. Code and models are available at https://anonymous.4open.science/r/Emotion-Qwen-Anonymous.
SZTU-CMU at MER2024: Improving Emotion-LLaMA with Conv-Attention for Multimodal Emotion Recognition
Aug 21, 2024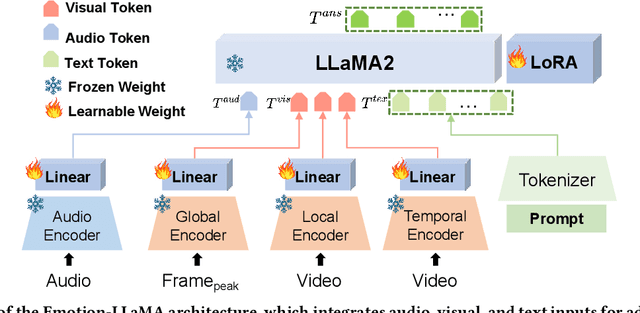



This paper presents our winning approach for the MER-NOISE and MER-OV tracks of the MER2024 Challenge on multimodal emotion recognition. Our system leverages the advanced emotional understanding capabilities of Emotion-LLaMA to generate high-quality annotations for unlabeled samples, addressing the challenge of limited labeled data. To enhance multimodal fusion while mitigating modality-specific noise, we introduce Conv-Attention, a lightweight and efficient hybrid framework. Extensive experimentation vali-dates the effectiveness of our approach. In the MER-NOISE track, our system achieves a state-of-the-art weighted average F-score of 85.30%, surpassing the second and third-place teams by 1.47% and 1.65%, respectively. For the MER-OV track, our utilization of Emotion-LLaMA for open-vocabulary annotation yields an 8.52% improvement in average accuracy and recall compared to GPT-4V, securing the highest score among all participating large multimodal models. The code and model for Emotion-LLaMA are available at https://github.com/ZebangCheng/Emotion-LLaMA.
StyleBrush: Style Extraction and Transfer from a Single Image
Aug 18, 2024



Stylization for visual content aims to add specific style patterns at the pixel level while preserving the original structural features. Compared with using predefined styles, stylization guided by reference style images is more challenging, where the main difficulty is to effectively separate style from structural elements. In this paper, we propose StyleBrush, a method that accurately captures styles from a reference image and ``brushes'' the extracted style onto other input visual content. Specifically, our architecture consists of two branches: ReferenceNet, which extracts style from the reference image, and Structure Guider, which extracts structural features from the input image, thus enabling image-guided stylization. We utilize LLM and T2I models to create a dataset comprising 100K high-quality style images, encompassing a diverse range of styles and contents with high aesthetic score. To construct training pairs, we crop different regions of the same training image. Experiments show that our approach achieves state-of-the-art results through both qualitative and quantitative analyses. We will release our code and dataset upon acceptance of the paper.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024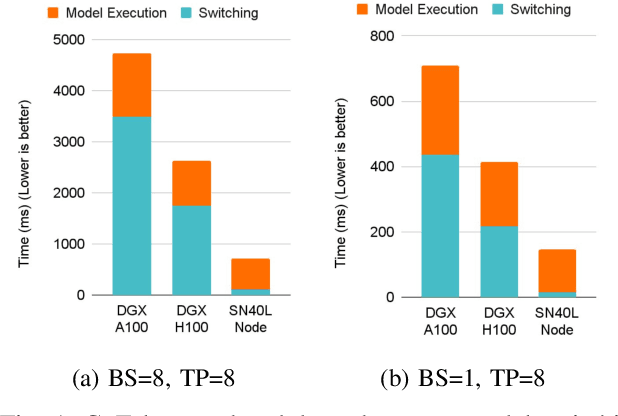
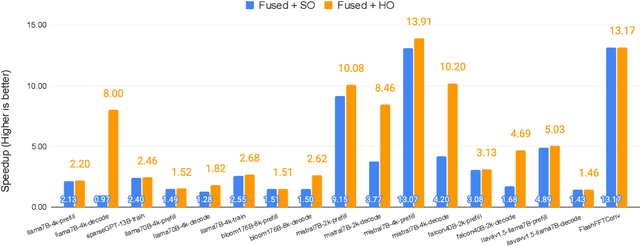
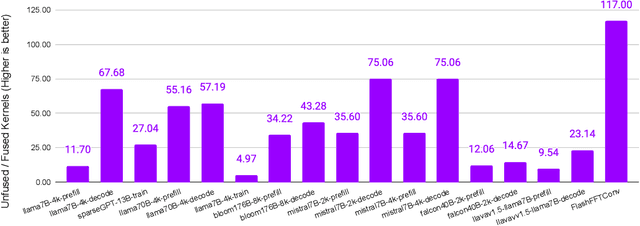
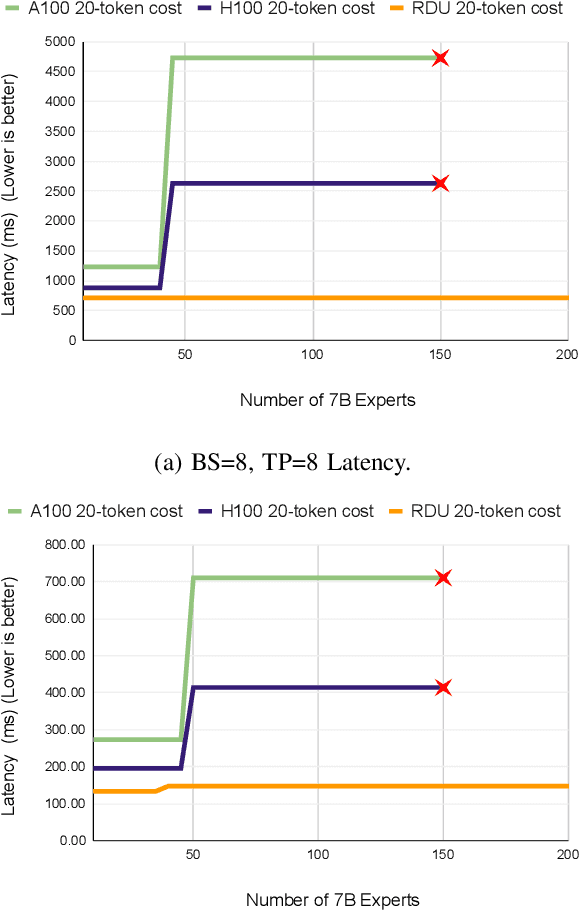
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.