 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Video Generation for Disease Progression Simulation
Nov 18, 2024Modeling disease progression is crucial for improving the quality and efficacy of clinical diagnosis and prognosis, but it is often hindered by a lack of longitudinal medical image monitoring for individual patients. To address this challenge, we propose the first Medical Video Generation (MVG) framework that enables controlled manipulation of disease-related image and video features, allowing precise, realistic, and personalized simulations of disease progression. Our approach begins by leveraging large language models (LLMs) to recaption prompt for disease trajectory. Next, a controllable multi-round diffusion model simulates the disease progression state for each patient, creating realistic intermediate disease state sequence. Finally, a diffusion-based video transition generation model interpolates disease progression between these states. We validate our framework across three medical imaging domains: chest X-ray, fundus photography, and skin image. Our results demonstrate that MVG significantly outperforms baseline models in generating coherent and clinically plausible disease trajectories. Two user studies by veteran physicians, provide further validation and insights into the clinical utility of the generated sequences. MVG has the potential to assist healthcare providers in modeling disease trajectories, interpolating missing medical image data, and enhancing medical education through realistic, dynamic visualizations of disease progression.
SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts
May 13, 2024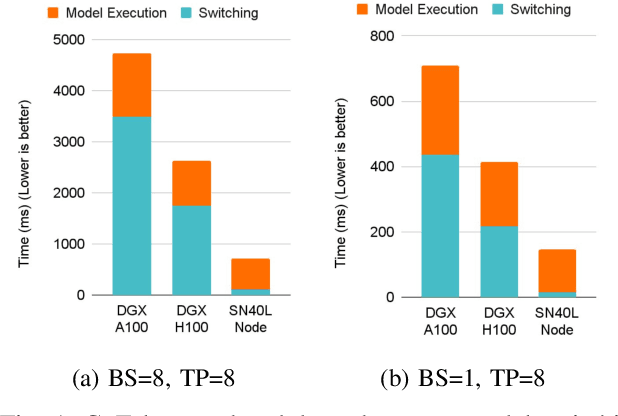
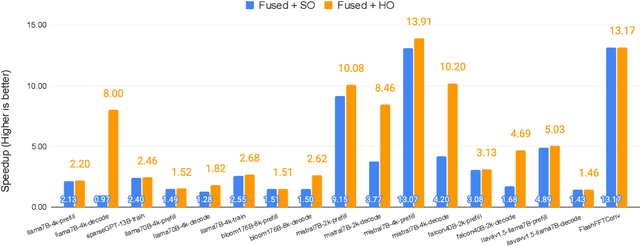
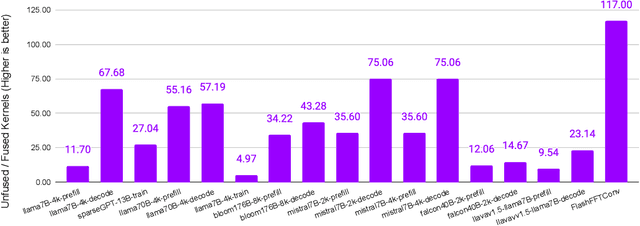
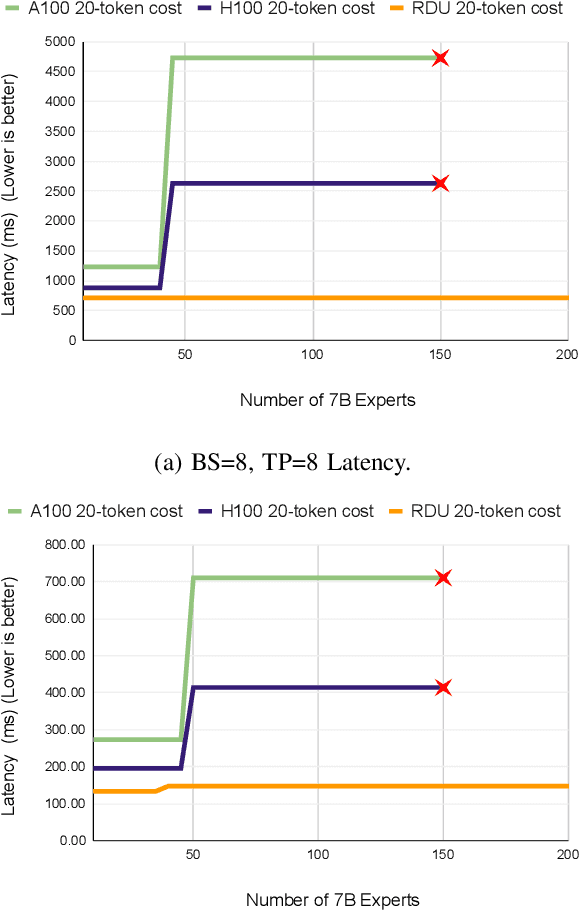
Monolithic large language models (LLMs) like GPT-4 have paved the way for modern generative AI applications. Training, serving, and maintaining monolithic LLMs at scale, however, remains prohibitively expensive and challenging. The disproportionate increase in compute-to-memory ratio of modern AI accelerators have created a memory wall, necessitating new methods to deploy AI. Composition of Experts (CoE) is an alternative modular approach that lowers the cost and complexity of training and serving. However, this approach presents two key challenges when using conventional hardware: (1) without fused operations, smaller models have lower operational intensity, which makes high utilization more challenging to achieve; and (2) hosting a large number of models can be either prohibitively expensive or slow when dynamically switching between them. In this paper, we describe how combining CoE, streaming dataflow, and a three-tier memory system scales the AI memory wall. We describe Samba-CoE, a CoE system with 150 experts and a trillion total parameters. We deploy Samba-CoE on the SambaNova SN40L Reconfigurable Dataflow Unit (RDU) - a commercial dataflow accelerator architecture that has been co-designed for enterprise inference and training applications. The chip introduces a new three-tier memory system with on-chip distributed SRAM, on-package HBM, and off-package DDR DRAM. A dedicated inter-RDU network enables scaling up and out over multiple sockets. We demonstrate speedups ranging from 2x to 13x on various benchmarks running on eight RDU sockets compared with an unfused baseline. We show that for CoE inference deployments, the 8-socket RDU Node reduces machine footprint by up to 19x, speeds up model switching time by 15x to 31x, and achieves an overall speedup of 3.7x over a DGX H100 and 6.6x over a DGX A100.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
PIE: Simulating Disease Progression via Progressive Image Editing
Sep 21, 2023Disease progression simulation is a crucial area of research that has significant implications for clinical diagnosis, prognosis, and treatment. One major challenge in this field is the lack of continuous medical imaging monitoring of individual patients over time. To address this issue, we develop a novel framework termed Progressive Image Editing (PIE) that enables controlled manipulation of disease-related image features, facilitating precise and realistic disease progression simulation. Specifically, we leverage recent advancements in text-to-image generative models to simulate disease progression accurately and personalize it for each patient. We theoretically analyze the iterative refining process in our framework as a gradient descent with an exponentially decayed learning rate. To validate our framework, we conduct experiments in three medical imaging domains. Our results demonstrate the superiority of PIE over existing methods such as Stable Diffusion Walk and Style-Based Manifold Extrapolation based on CLIP score (Realism) and Disease Classification Confidence (Alignment). Our user study collected feedback from 35 veteran physicians to assess the generated progressions. Remarkably, 76.2% of the feedback agrees with the fidelity of the generated progressions. To our best knowledge, PIE is the first of its kind to generate disease progression images meeting real-world standards. It is a promising tool for medical research and clinical practice, potentially allowing healthcare providers to model disease trajectories over time, predict future treatment responses, and improve patient outcomes.
Q-ASR: Integer-only Zero-shot Quantization for Efficient Speech Recognition
Mar 31, 2021
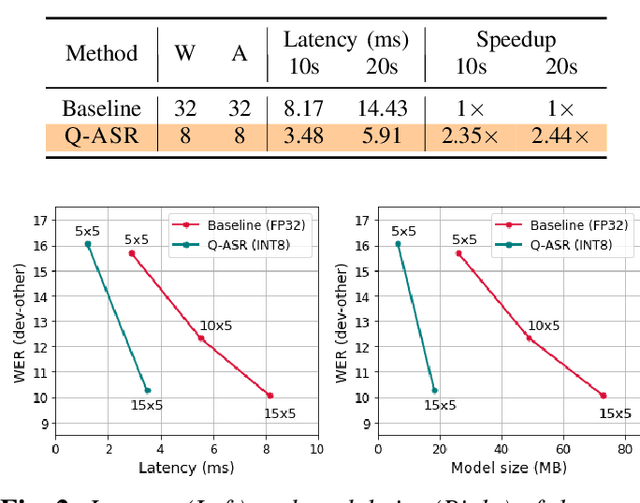

End-to-end neural network models achieve improved performance on various automatic speech recognition (ASR) tasks. However, these models perform poorly on edge hardware due to large memory and computation requirements. While quantizing model weights and/or activations to low-precision can be a promising solution, previous research on quantizing ASR models is limited. Most quantization approaches use floating-point arithmetic during inference; and thus they cannot fully exploit integer processing units, which use less power than their floating-point counterparts. Moreover, they require training/validation data during quantization for finetuning or calibration; however, this data may not be available due to security/privacy concerns. To address these limitations, we propose Q-ASR, an integer-only, zero-shot quantization scheme for ASR models. In particular, we generate synthetic data whose runtime statistics resemble the real data, and we use it to calibrate models during quantization. We then apply Q-ASR to quantize QuartzNet-15x5 and JasperDR-10x5 without any training data, and we show negligible WER change as compared to the full-precision baseline models. For INT8-only quantization, we observe a very modest WER degradation of up to 0.29%, while we achieve up to 2.44x speedup on a T4 GPU. Furthermore, Q-ASR exhibits a large compression rate of more than 4x with small WER degradation.