 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed Viscous Value Representations
Feb 26, 2026Offline goal-conditioned reinforcement learning (GCRL) learns goal-conditioned policies from static pre-collected datasets. However, accurate value estimation remains a challenge due to the limited coverage of the state-action space. Recent physics-informed approaches have sought to address this by imposing physical and geometric constraints on the value function through regularization defined over first-order partial differential equations (PDEs), such as the Eikonal equation. However, these formulations can often be ill-posed in complex, high-dimensional environments. In this work, we propose a physics-informed regularization derived from the viscosity solution of the Hamilton-Jacobi-Bellman (HJB) equation. By providing a physics-based inductive bias, our approach grounds the learning process in optimal control theory, explicitly regularizing and bounding updates during value iterations. Furthermore, we leverage the Feynman-Kac theorem to recast the PDE solution as an expectation, enabling a tractable Monte Carlo estimation of the objective that avoids numerical instability in higher-order gradients. Experiments demonstrate that our method improves geometric consistency, making it broadly applicable to navigation and high-dimensional, complex manipulation tasks. Open-source codes are available at https://github.com/HrishikeshVish/phys-fk-value-GCRL.
A Hierarchical Test Platform for Vision Language Model (VLM)-Integrated Real-World Autonomous Driving
Jun 17, 2025Vision-Language Models (VLMs) have demonstrated notable promise in autonomous driving by offering the potential for multimodal reasoning through pretraining on extensive image-text pairs. However, adapting these models from broad web-scale data to the safety-critical context of driving presents a significant challenge, commonly referred to as domain shift. Existing simulation-based and dataset-driven evaluation methods, although valuable, often fail to capture the full complexity of real-world scenarios and cannot easily accommodate repeatable closed-loop testing with flexible scenario manipulation. In this paper, we introduce a hierarchical real-world test platform specifically designed to evaluate VLM-integrated autonomous driving systems. Our approach includes a modular, low-latency on-vehicle middleware that allows seamless incorporation of various VLMs, a clearly separated perception-planning-control architecture that can accommodate both VLM-based and conventional modules, and a configurable suite of real-world testing scenarios on a closed track that facilitates controlled yet authentic evaluations. We demonstrate the effectiveness of the proposed platform`s testing and evaluation ability with a case study involving a VLM-enabled autonomous vehicle, highlighting how our test framework supports robust experimentation under diverse conditions.
Inference Acceleration of Autoregressive Normalizing Flows by Selective Jacobi Decoding
May 30, 2025Normalizing flows are promising generative models with advantages such as theoretical rigor, analytical log-likelihood computation, and end-to-end training. However, the architectural constraints to ensure invertibility and tractable Jacobian computation limit their expressive power and practical usability. Recent advancements utilize autoregressive modeling, significantly enhancing expressive power and generation quality. However, such sequential modeling inherently restricts parallel computation during inference, leading to slow generation that impedes practical deployment. In this paper, we first identify that strict sequential dependency in inference is unnecessary to generate high-quality samples. We observe that patches in sequential modeling can also be approximated without strictly conditioning on all preceding patches. Moreover, the models tend to exhibit low dependency redundancy in the initial layer and higher redundancy in subsequent layers. Leveraging these observations, we propose a selective Jacobi decoding (SeJD) strategy that accelerates autoregressive inference through parallel iterative optimization. Theoretical analyses demonstrate the method's superlinear convergence rate and guarantee that the number of iterations required is no greater than the original sequential approach. Empirical evaluations across multiple datasets validate the generality and effectiveness of our acceleration technique. Experiments demonstrate substantial speed improvements up to 4.7 times faster inference while keeping the generation quality and fidelity.
Quantifying Uncertainty in Motion Prediction with Variational Bayesian Mixture
Apr 04, 2024



Safety and robustness are crucial factors in developing trustworthy autonomous vehicles. One essential aspect of addressing these factors is to equip vehicles with the capability to predict future trajectories for all moving objects in the surroundings and quantify prediction uncertainties. In this paper, we propose the Sequential Neural Variational Agent (SeNeVA), a generative model that describes the distribution of future trajectories for a single moving object. Our approach can distinguish Out-of-Distribution data while quantifying uncertainty and achieving competitive performance compared to state-of-the-art methods on the Argoverse 2 and INTERACTION datasets. Specifically, a 0.446 meters minimum Final Displacement Error, a 0.203 meters minimum Average Displacement Error, and a 5.35% Miss Rate are achieved on the INTERACTION test set. Extensive qualitative and quantitative analysis is also provided to evaluate the proposed model. Our open-source code is available at https://github.com/PurdueDigitalTwin/seneva.
Towards Generalizable and Interpretable Motion Prediction: A Deep Variational Bayes Approach
Mar 10, 2024Estimating the potential behavior of the surrounding human-driven vehicles is crucial for the safety of autonomous vehicles in a mixed traffic flow. Recent state-of-the-art achieved accurate prediction using deep neural networks. However, these end-to-end models are usually black boxes with weak interpretability and generalizability. This paper proposes the Goal-based Neural Variational Agent (GNeVA), an interpretable generative model for motion prediction with robust generalizability to out-of-distribution cases. For interpretability, the model achieves target-driven motion prediction by estimating the spatial distribution of long-term destinations with a variational mixture of Gaussians. We identify a causal structure among maps and agents' histories and derive a variational posterior to enhance generalizability. Experiments on motion prediction datasets validate that the fitted model can be interpretable and generalizable and can achieve comparable performance to state-of-the-art results.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
LaMPilot: An Open Benchmark Dataset for Autonomous Driving with Language Model Programs
Dec 07, 2023We present LaMPilot, a novel framework for planning in the field of autonomous driving, rethinking the task as a code-generation process that leverages established behavioral primitives. This approach aims to address the challenge of interpreting and executing spontaneous user instructions such as "overtake the car ahead," which have typically posed difficulties for existing frameworks. We introduce the LaMPilot benchmark specifically designed to quantitatively evaluate the efficacy of Large Language Models (LLMs) in translating human directives into actionable driving policies. We then evaluate a wide range of state-of-the-art code generation language models on tasks from the LaMPilot Benchmark. The results of the experiments showed that GPT-4, with human feedback, achieved an impressive task completion rate of 92.7% and a minimal collision rate of 0.9%. To encourage further investigation in this area, our code and dataset will be made available.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


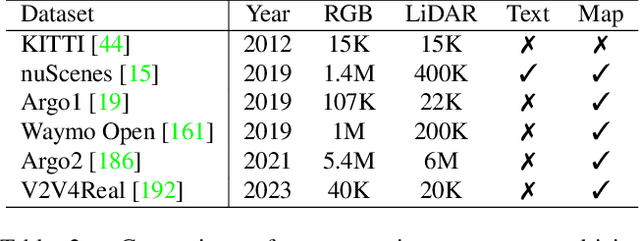
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
MACP: Efficient Model Adaptation for Cooperative Perception
Nov 07, 2023Vehicle-to-vehicle (V2V) communications have greatly enhanced the perception capabilities of connected and automated vehicles (CAVs) by enabling information sharing to "see through the occlusions", resulting in significant performance improvements. However, developing and training complex multi-agent perception models from scratch can be expensive and unnecessary when existing single-agent models show remarkable generalization capabilities. In this paper, we propose a new framework termed MACP, which equips a single-agent pre-trained model with cooperation capabilities. We approach this objective by identifying the key challenges of shifting from single-agent to cooperative settings, adapting the model by freezing most of its parameters and adding a few lightweight modules. We demonstrate in our experiments that the proposed framework can effectively utilize cooperative observations and outperform other state-of-the-art approaches in both simulated and real-world cooperative perception benchmarks while requiring substantially fewer tunable parameters with reduced communication costs. Our source code is available at https://github.com/PurdueDigitalTwin/MACP.
Radar Enlighten the Dark: Enhancing Low-Visibility Perception for Automated Vehicles with Camera-Radar Fusion
May 27, 2023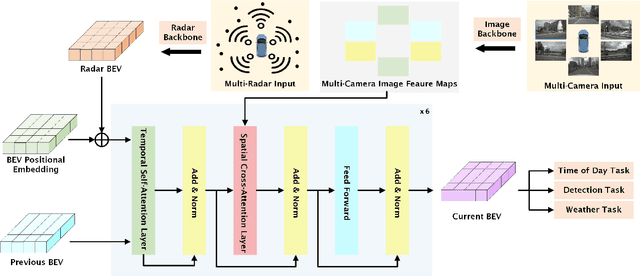
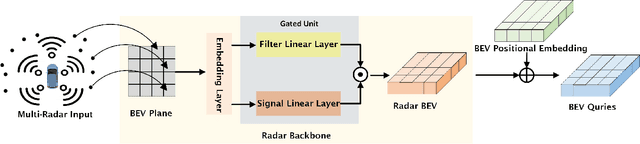


Sensor fusion is a crucial augmentation technique for improving the accuracy and reliability of perception systems for automated vehicles under diverse driving conditions. However, adverse weather and low-light conditions remain challenging, where sensor performance degrades significantly, exposing vehicle safety to potential risks. Advanced sensors such as LiDARs can help mitigate the issue but with extremely high marginal costs. In this paper, we propose a novel transformer-based 3D object detection model "REDFormer" to tackle low visibility conditions, exploiting the power of a more practical and cost-effective solution by leveraging bird's-eye-view camera-radar fusion. Using the nuScenes dataset with multi-radar point clouds, weather information, and time-of-day data, our model outperforms state-of-the-art (SOTA) models on classification and detection accuracy. Finally, we provide extensive ablation studies of each model component on their contributions to address the above-mentioned challenges. Particularly, it is shown in the experiments that our model achieves a significant performance improvement over the baseline model in low-visibility scenarios, specifically exhibiting a 31.31% increase in rainy scenes and a 46.99% enhancement in nighttime scenes.The source code of this study is publicly available.