 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
Jan 29, 2026End-to-end autonomous driving increasingly leverages self-supervised video pretraining to learn transferable planning representations. However, pretraining video world models for scene understanding has so far brought only limited improvements. This limitation is compounded by the inherent ambiguity of driving: each scene typically provides only a single human trajectory, making it difficult to learn multimodal behaviors. In this work, we propose Drive-JEPA, a framework that integrates Video Joint-Embedding Predictive Architecture (V-JEPA) with multimodal trajectory distillation for end-to-end driving. First, we adapt V-JEPA for end-to-end driving, pretraining a ViT encoder on large-scale driving videos to produce predictive representations aligned with trajectory planning. Second, we introduce a proposal-centric planner that distills diverse simulator-generated trajectories alongside human trajectories, with a momentum-aware selection mechanism to promote stable and safe behavior. When evaluated on NAVSIM, the V-JEPA representation combined with a simple transformer-based decoder outperforms prior methods by 3 PDMS in the perception-free setting. The complete Drive-JEPA framework achieves 93.3 PDMS on v1 and 87.8 EPDMS on v2, setting a new state-of-the-art.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
A Hierarchical Test Platform for Vision Language Model (VLM)-Integrated Real-World Autonomous Driving
Jun 17, 2025Vision-Language Models (VLMs) have demonstrated notable promise in autonomous driving by offering the potential for multimodal reasoning through pretraining on extensive image-text pairs. However, adapting these models from broad web-scale data to the safety-critical context of driving presents a significant challenge, commonly referred to as domain shift. Existing simulation-based and dataset-driven evaluation methods, although valuable, often fail to capture the full complexity of real-world scenarios and cannot easily accommodate repeatable closed-loop testing with flexible scenario manipulation. In this paper, we introduce a hierarchical real-world test platform specifically designed to evaluate VLM-integrated autonomous driving systems. Our approach includes a modular, low-latency on-vehicle middleware that allows seamless incorporation of various VLMs, a clearly separated perception-planning-control architecture that can accommodate both VLM-based and conventional modules, and a configurable suite of real-world testing scenarios on a closed track that facilitates controlled yet authentic evaluations. We demonstrate the effectiveness of the proposed platform`s testing and evaluation ability with a case study involving a VLM-enabled autonomous vehicle, highlighting how our test framework supports robust experimentation under diverse conditions.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024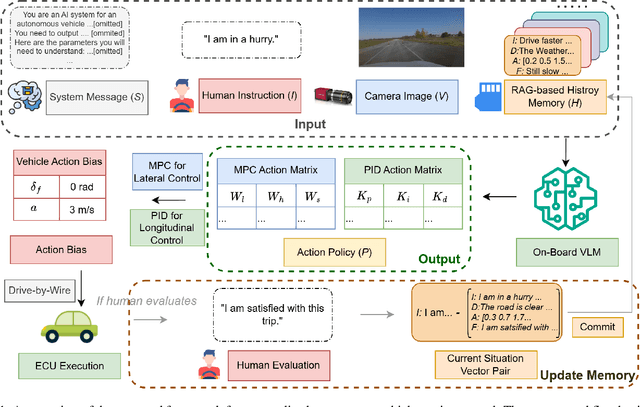
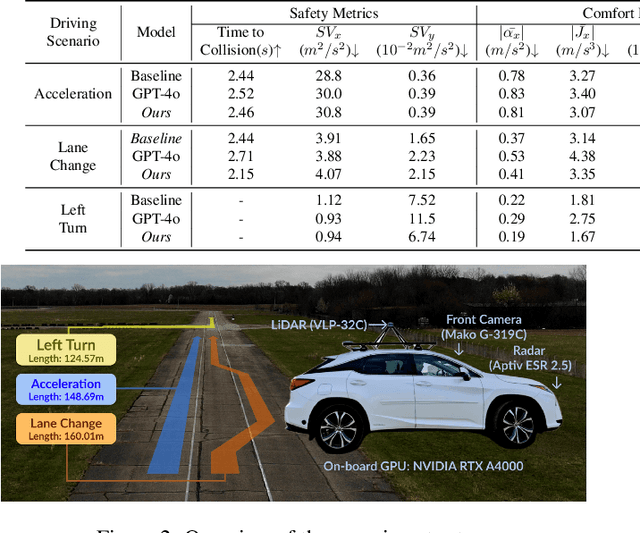

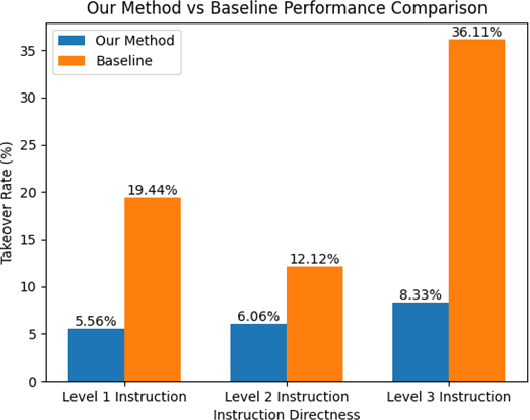
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


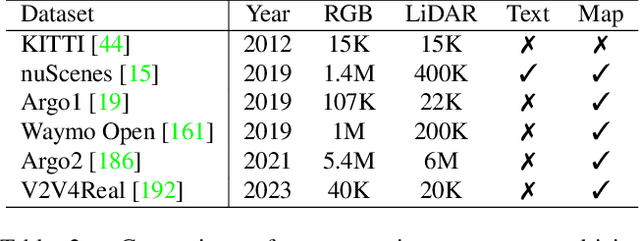
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.