 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics Informed Viscous Value Representations
Feb 26, 2026Offline goal-conditioned reinforcement learning (GCRL) learns goal-conditioned policies from static pre-collected datasets. However, accurate value estimation remains a challenge due to the limited coverage of the state-action space. Recent physics-informed approaches have sought to address this by imposing physical and geometric constraints on the value function through regularization defined over first-order partial differential equations (PDEs), such as the Eikonal equation. However, these formulations can often be ill-posed in complex, high-dimensional environments. In this work, we propose a physics-informed regularization derived from the viscosity solution of the Hamilton-Jacobi-Bellman (HJB) equation. By providing a physics-based inductive bias, our approach grounds the learning process in optimal control theory, explicitly regularizing and bounding updates during value iterations. Furthermore, we leverage the Feynman-Kac theorem to recast the PDE solution as an expectation, enabling a tractable Monte Carlo estimation of the objective that avoids numerical instability in higher-order gradients. Experiments demonstrate that our method improves geometric consistency, making it broadly applicable to navigation and high-dimensional, complex manipulation tasks. Open-source codes are available at https://github.com/HrishikeshVish/phys-fk-value-GCRL.
Efficient and Explainable End-to-End Autonomous Driving via Masked Vision-Language-Action Diffusion
Feb 24, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged as promising candidates for end-to-end autonomous driving. However, these models typically face challenges in inference latency, action precision, and explainability. Existing autoregressive approaches struggle with slow token-by-token generation, while prior diffusion-based planners often rely on verbose, general-purpose language tokens that lack explicit geometric structure. In this work, we propose Masked Vision-Language-Action Diffusion for Autonomous Driving (MVLAD-AD), a novel framework designed to bridge the gap between efficient planning and semantic explainability via a masked vision-language-action diffusion model. Unlike methods that force actions into the language space, we introduce a discrete action tokenization strategy that constructs a compact codebook of kinematically feasible waypoints from real-world driving distributions. Moreover, we propose geometry-aware embedding learning to ensure that embeddings in the latent space approximate physical geometric metrics. Finally, an action-priority decoding strategy is introduced to prioritize trajectory generation. Extensive experiments on nuScenes and derived benchmarks demonstrate that MVLAD-AD achieves superior efficiency and outperforms state-of-the-art autoregressive and diffusion baselines in planning precision, while providing high-fidelity and explainable reasoning.
A Universal and Robust Framework for Multiple Gas Recognition Based-on Spherical Normalization-Coupled Mahalanobis Algorithm
Jan 05, 2026Electronic nose (E-nose) systems face two interconnected challenges in open-set gas recognition: feature distribution shift caused by signal drift and decision boundary failure induced by unknown gas interference. Existing methods predominantly rely on Euclidean distance or conventional classifiers, failing to account for anisotropic feature distributions and dynamic signal intensity variations. To address these issues, this study proposes the Spherical Normalization coupled Mahalanobis (SNM) module, a universal post-processing module for open-set gas recognition. First, it achieves geometric decoupling through cascaded batch and L2 normalization, projecting features onto a unit hypersphere to eliminate signal intensity fluctuations. Second, it utilizes Mahalanobis distance to construct adaptive ellipsoidal decision boundaries that conform to the anisotropic feature geometry. The architecture-agnostic SNM-Module seamlessly integrates with mainstream backbones including Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Transformer. Experiments on the public Vergara dataset demonstrate that the Transformer+SNM configuration achieves near-theoretical-limit performance in discriminating among multiple target gases, with an AUROC of 0.9977 and an unknown gas detection rate of 99.57% at 5% false positive rate, significantly outperforming state-of-the-art methods with a 3.0% AUROC improvement and 91.0% standard deviation reduction compared to Class Anchor Clustering (CAC). The module maintains exceptional robustness across five sensor positions, with standard deviations below 0.0028. This work effectively addresses the critical challenge of simultaneously achieving high accuracy and high stability in open-set gas recognition, providing solid support for industrial E-nose deployment.
Digital Twin AI: Opportunities and Challenges from Large Language Models to World Models
Jan 04, 2026Digital twins, as precise digital representations of physical systems, have evolved from passive simulation tools into intelligent and autonomous entities through the integration of artificial intelligence technologies. This paper presents a unified four-stage framework that systematically characterizes AI integration across the digital twin lifecycle, spanning modeling, mirroring, intervention, and autonomous management. By synthesizing existing technologies and practices, we distill a unified four-stage framework that systematically characterizes how AI methodologies are embedded across the digital twin lifecycle: (1) modeling the physical twin through physics-based and physics-informed AI approaches, (2) mirroring the physical system into a digital twin with real-time synchronization, (3) intervening in the physical twin through predictive modeling, anomaly detection, and optimization strategies, and (4) achieving autonomous management through large language models, foundation models, and intelligent agents. We analyze the synergy between physics-based modeling and data-driven learning, highlighting the shift from traditional numerical solvers to physics-informed and foundation models for physical systems. Furthermore, we examine how generative AI technologies, including large language models and generative world models, transform digital twins into proactive and self-improving cognitive systems capable of reasoning, communication, and creative scenario generation. Through a cross-domain review spanning eleven application domains, including healthcare, aerospace, smart manufacturing, robotics, and smart cities, we identify common challenges related to scalability, explainability, and trustworthiness, and outline directions for responsible AI-driven digital twin systems.
SNM-Net: A Universal Framework for Robust Open-Set Gas Recognition via Spherical Normalization and Mahalanobis Distance
Dec 28, 2025Electronic nose (E-nose) systems face dual challenges in open-set gas recognition: feature distribution shifts caused by signal drift and decision failures induced by unknown interference. Existing methods predominantly rely on Euclidean distance, failing to adequately account for anisotropic gas feature distributions and dynamic signal intensity variations. To address these issues, this study proposes SNM-Net, a universal deep learning framework for open-set gas recognition. The core innovation lies in a geometric decoupling mechanism achieved through cascaded batch normalization and L2 normalization, which projects high-dimensional features onto a unit hypersphere to eliminate signal intensity fluctuations. Additionally, Mahalanobis distance is introduced as the scoring mechanism, utilizing class-wise statistics to construct adaptive ellipsoidal decision boundaries. SNM-Net is architecture-agnostic and seamlessly integrates with CNN, RNN, and Transformer backbones. Systematic experiments on the Vergara dataset demonstrate that the Transformer+SNM configuration attains near-theoretical performance, achieving an AUROC of 0.9977 and an unknown gas detection rate of 99.57% (TPR at 5% FPR). This performance significantly outperforms state-of-the-art methods, showing a 3.0% improvement in AUROC and a 91.0% reduction in standard deviation compared to Class Anchor Clustering. The framework exhibits exceptional robustness across sensor positions with standard deviations below 0.0028. This work effectively resolves the trade-off between accuracy and stability, providing a solid technical foundation for industrial E-nose deployment.
FSDAM: Few-Shot Driving Attention Modeling via Vision-Language Coupling
Nov 16, 2025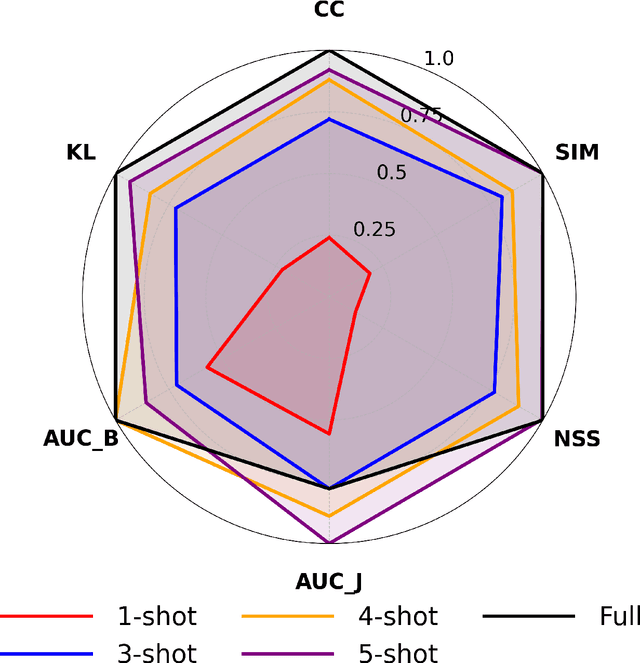

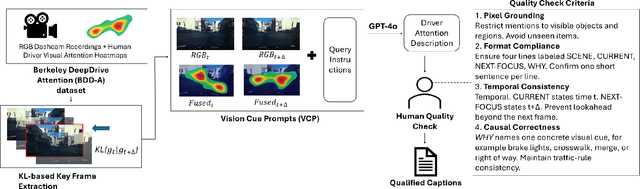
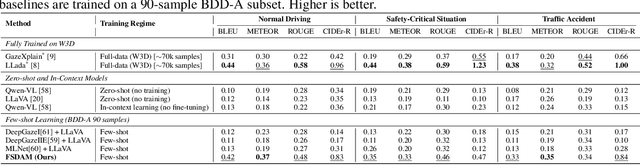
Understanding where drivers look and why they shift their attention is essential for autonomous systems that read human intent and justify their actions. Most existing models rely on large-scale gaze datasets to learn these patterns; however, such datasets are labor-intensive to collect and time-consuming to curate. We present FSDAM (Few-Shot Driver Attention Modeling), a framework that achieves joint attention prediction and caption generation with approximately 100 annotated examples, two orders of magnitude fewer than existing approaches. Our approach introduces a dual-pathway architecture where separate modules handle spatial prediction and caption generation while maintaining semantic consistency through cross-modal alignment. Despite minimal supervision, FSDAM achieves competitive performance on attention prediction, generates coherent, and context-aware explanations. The model demonstrates robust zero-shot generalization across multiple driving benchmarks. This work shows that effective attention-conditioned generation is achievable with limited supervision, opening new possibilities for practical deployment of explainable driver attention systems in data-constrained scenarios.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
A Hierarchical Test Platform for Vision Language Model (VLM)-Integrated Real-World Autonomous Driving
Jun 17, 2025Vision-Language Models (VLMs) have demonstrated notable promise in autonomous driving by offering the potential for multimodal reasoning through pretraining on extensive image-text pairs. However, adapting these models from broad web-scale data to the safety-critical context of driving presents a significant challenge, commonly referred to as domain shift. Existing simulation-based and dataset-driven evaluation methods, although valuable, often fail to capture the full complexity of real-world scenarios and cannot easily accommodate repeatable closed-loop testing with flexible scenario manipulation. In this paper, we introduce a hierarchical real-world test platform specifically designed to evaluate VLM-integrated autonomous driving systems. Our approach includes a modular, low-latency on-vehicle middleware that allows seamless incorporation of various VLMs, a clearly separated perception-planning-control architecture that can accommodate both VLM-based and conventional modules, and a configurable suite of real-world testing scenarios on a closed track that facilitates controlled yet authentic evaluations. We demonstrate the effectiveness of the proposed platform`s testing and evaluation ability with a case study involving a VLM-enabled autonomous vehicle, highlighting how our test framework supports robust experimentation under diverse conditions.
Inference Acceleration of Autoregressive Normalizing Flows by Selective Jacobi Decoding
May 30, 2025Normalizing flows are promising generative models with advantages such as theoretical rigor, analytical log-likelihood computation, and end-to-end training. However, the architectural constraints to ensure invertibility and tractable Jacobian computation limit their expressive power and practical usability. Recent advancements utilize autoregressive modeling, significantly enhancing expressive power and generation quality. However, such sequential modeling inherently restricts parallel computation during inference, leading to slow generation that impedes practical deployment. In this paper, we first identify that strict sequential dependency in inference is unnecessary to generate high-quality samples. We observe that patches in sequential modeling can also be approximated without strictly conditioning on all preceding patches. Moreover, the models tend to exhibit low dependency redundancy in the initial layer and higher redundancy in subsequent layers. Leveraging these observations, we propose a selective Jacobi decoding (SeJD) strategy that accelerates autoregressive inference through parallel iterative optimization. Theoretical analyses demonstrate the method's superlinear convergence rate and guarantee that the number of iterations required is no greater than the original sequential approach. Empirical evaluations across multiple datasets validate the generality and effectiveness of our acceleration technique. Experiments demonstrate substantial speed improvements up to 4.7 times faster inference while keeping the generation quality and fidelity.
ALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving
May 21, 2025Recent advances have explored integrating large language models (LLMs) into end-to-end autonomous driving systems to enhance generalization and interpretability. However, most existing approaches are limited to either driving performance or vision-language reasoning, making it difficult to achieve both simultaneously. In this paper, we propose ALN-P3, a unified co-distillation framework that introduces cross-modal alignment between "fast" vision-based autonomous driving systems and "slow" language-driven reasoning modules. ALN-P3 incorporates three novel alignment mechanisms: Perception Alignment (P1A), Prediction Alignment (P2A), and Planning Alignment (P3A), which explicitly align visual tokens with corresponding linguistic outputs across the full perception, prediction, and planning stack. All alignment modules are applied only during training and incur no additional costs during inference. Extensive experiments on four challenging benchmarks-nuScenes, Nu-X, TOD3Cap, and nuScenes QA-demonstrate that ALN-P3 significantly improves both driving decisions and language reasoning, achieving state-of-the-art results.