 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILD: Physics-Informed Learning via Diffusion
Jan 29, 2026Diffusion models have emerged as powerful generative tools for modeling complex data distributions, yet their purely data-driven nature limits applicability in practical engineering and scientific problems where physical laws need to be followed. This paper proposes Physics-Informed Learning via Diffusion (PILD), a framework that unifies diffusion modeling and first-principles physical constraints by introducing a virtual residual observation sampled from a Laplace distribution to supervise generation during training. To further integrate physical laws, a conditional embedding module is incorporated to inject physical information into the denoising network at multiple layers, ensuring consistent guidance throughout the diffusion process. The proposed PILD framework is concise, modular, and broadly applicable to problems governed by ordinary differential equations, partial differential equations, as well as algebraic equations or inequality constraints. Extensive experiments across engineering and scientific tasks including estimating vehicle trajectories, tire forces, Darcy flow and plasma dynamics, demonstrate that our PILD substantially improves accuracy, stability, and generalization over existing physics-informed and diffusion-based baselines.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
Inference Acceleration of Autoregressive Normalizing Flows by Selective Jacobi Decoding
May 30, 2025Normalizing flows are promising generative models with advantages such as theoretical rigor, analytical log-likelihood computation, and end-to-end training. However, the architectural constraints to ensure invertibility and tractable Jacobian computation limit their expressive power and practical usability. Recent advancements utilize autoregressive modeling, significantly enhancing expressive power and generation quality. However, such sequential modeling inherently restricts parallel computation during inference, leading to slow generation that impedes practical deployment. In this paper, we first identify that strict sequential dependency in inference is unnecessary to generate high-quality samples. We observe that patches in sequential modeling can also be approximated without strictly conditioning on all preceding patches. Moreover, the models tend to exhibit low dependency redundancy in the initial layer and higher redundancy in subsequent layers. Leveraging these observations, we propose a selective Jacobi decoding (SeJD) strategy that accelerates autoregressive inference through parallel iterative optimization. Theoretical analyses demonstrate the method's superlinear convergence rate and guarantee that the number of iterations required is no greater than the original sequential approach. Empirical evaluations across multiple datasets validate the generality and effectiveness of our acceleration technique. Experiments demonstrate substantial speed improvements up to 4.7 times faster inference while keeping the generation quality and fidelity.
Revealing the Unseen: Guiding Personalized Diffusion Models to Expose Training Data
Oct 03, 2024
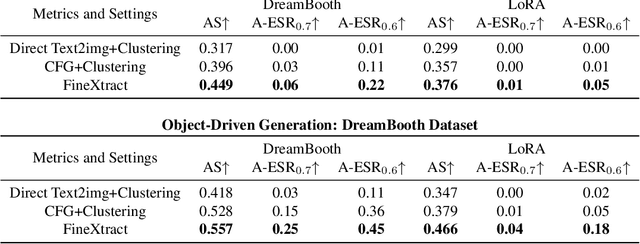
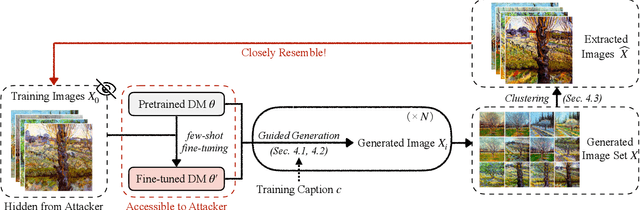

Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot fine-tuning where a pretrained DM is fine-tuned on a small set of images to capture specific styles or objects. Many people upload these personalized checkpoints online, fostering communities such as Civitai and HuggingFace. However, model owners may overlook the potential risks of data leakage by releasing their fine-tuned checkpoints. Moreover, concerns regarding copyright violations arise when unauthorized data is used during fine-tuning. In this paper, we ask: "Can training data be extracted from these fine-tuned DMs shared online?" A successful extraction would present not only data leakage threats but also offer tangible evidence of copyright infringement. To answer this, we propose FineXtract, a framework for extracting fine-tuning data. Our method approximates fine-tuning as a gradual shift in the model's learned distribution -- from the original pretrained DM toward the fine-tuning data. By extrapolating the models before and after fine-tuning, we guide the generation toward high-probability regions within the fine-tuned data distribution. We then apply a clustering algorithm to extract the most probable images from those generated using this extrapolated guidance. Experiments on DMs fine-tuned with datasets such as WikiArt, DreamBooth, and real-world checkpoints posted online validate the effectiveness of our method, extracting approximately 20% of fine-tuning data in most cases, significantly surpassing baseline performance.
Scalable Differentiable Causal Discovery in the Presence of Latent Confounders with Skeleton Posterior (Extended Version)
Jun 15, 2024



Differentiable causal discovery has made significant advancements in the learning of directed acyclic graphs. However, its application to real-world datasets remains restricted due to the ubiquity of latent confounders and the requirement to learn maximal ancestral graphs (MAGs). To date, existing differentiable MAG learning algorithms have been limited to small datasets and failed to scale to larger ones (e.g., with more than 50 variables). The key insight in this paper is that the causal skeleton, which is the undirected version of the causal graph, has potential for improving accuracy and reducing the search space of the optimization procedure, thereby enhancing the performance of differentiable causal discovery. Therefore, we seek to address a two-fold challenge to harness the potential of the causal skeleton for differentiable causal discovery in the presence of latent confounders: (1) scalable and accurate estimation of skeleton and (2) universal integration of skeleton estimation with differentiable causal discovery. To this end, we propose SPOT (Skeleton Posterior-guided OpTimization), a two-phase framework that harnesses skeleton posterior for differentiable causal discovery in the presence of latent confounders. On the contrary to a ``point-estimation'', SPOT seeks to estimate the posterior distribution of skeletons given the dataset. It first formulates the posterior inference as an instance of amortized inference problem and concretizes it with a supervised causal learning (SCL)-enabled solution to estimate the skeleton posterior. To incorporate the skeleton posterior with differentiable causal discovery, SPOT then features a skeleton posterior-guided stochastic optimization procedure to guide the optimization of MAGs. [abridged due to length limit]
Exploring Diffusion Models' Corruption Stage in Few-Shot Fine-tuning and Mitigating with Bayesian Neural Networks
May 30, 2024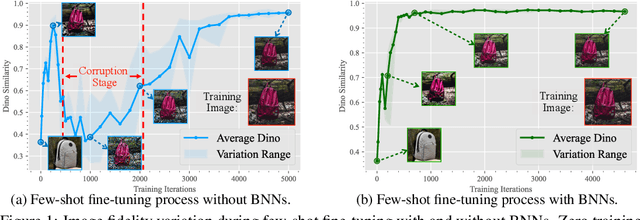
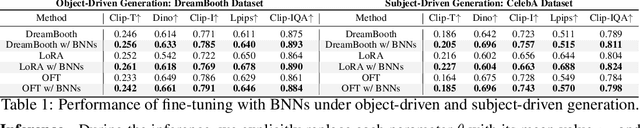
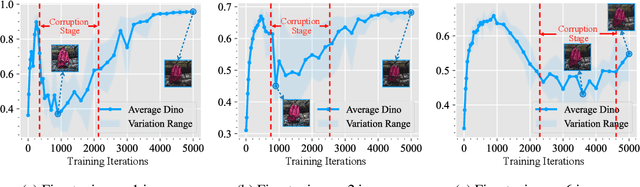
Few-shot fine-tuning of Diffusion Models (DMs) is a key advancement, significantly reducing training costs and enabling personalized AI applications. However, we explore the training dynamics of DMs and observe an unanticipated phenomenon: during the training process, image fidelity initially improves, then unexpectedly deteriorates with the emergence of noisy patterns, only to recover later with severe overfitting. We term the stage with generated noisy patterns as corruption stage. To understand this corruption stage, we begin by theoretically modeling the one-shot fine-tuning scenario, and then extend this modeling to more general cases. Through this modeling, we identify the primary cause of this corruption stage: a narrowed learning distribution inherent in the nature of few-shot fine-tuning. To tackle this, we apply Bayesian Neural Networks (BNNs) on DMs with variational inference to implicitly broaden the learned distribution, and present that the learning target of the BNNs can be naturally regarded as an expectation of the diffusion loss and a further regularization with the pretrained DMs. This approach is highly compatible with current few-shot fine-tuning methods in DMs and does not introduce any extra inference costs. Experimental results demonstrate that our method significantly mitigates corruption, and improves the fidelity, quality and diversity of the generated images in both object-driven and subject-driven generation tasks.
CGI-DM: Digital Copyright Authentication for Diffusion Models via Contrasting Gradient Inversion
Mar 17, 2024


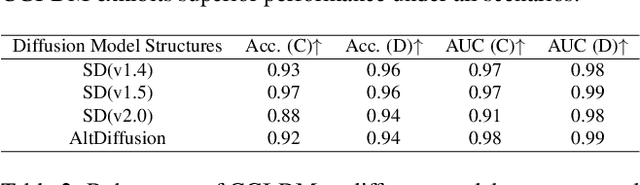
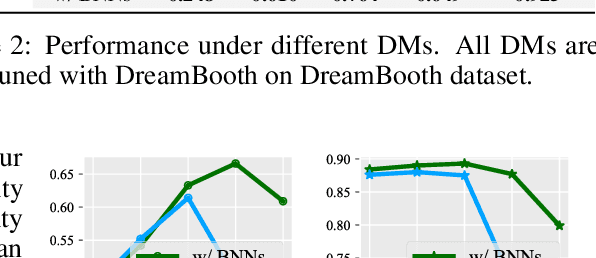
Diffusion Models (DMs) have evolved into advanced image generation tools, especially for few-shot generation where a pretrained model is fine-tuned on a small set of images to capture a specific style or object. Despite their success, concerns exist about potential copyright violations stemming from the use of unauthorized data in this process. In response, we present Contrasting Gradient Inversion for Diffusion Models (CGI-DM), a novel method featuring vivid visual representations for digital copyright authentication. Our approach involves removing partial information of an image and recovering missing details by exploiting conceptual differences between the pretrained and fine-tuned models. We formulate the differences as KL divergence between latent variables of the two models when given the same input image, which can be maximized through Monte Carlo sampling and Projected Gradient Descent (PGD). The similarity between original and recovered images serves as a strong indicator of potential infringements. Extensive experiments on the WikiArt and Dreambooth datasets demonstrate the high accuracy of CGI-DM in digital copyright authentication, surpassing alternative validation techniques. Code implementation is available at https://github.com/Nicholas0228/Revelio.
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
Feb 09, 2023



Diffusion Models (DMs) achieve state-of-the-art performance in generative tasks, boosting a wave in AI for Art. Despite the success of commercialization, DMs meanwhile provide tools for copyright violations, where infringers benefit from illegally using paintings created by human artists to train DMs and generate novel paintings in a similar style. In this paper, we show that it is possible to create an image $x'$ that is similar to an image $x$ for human vision but unrecognizable for DMs. We build a framework to define and evaluate this adversarial example for diffusion models. Based on the framework, we further propose AdvDM, an algorithm to generate adversarial examples for DMs. By optimizing upon different latent variables sampled from the reverse process of DMs, AdvDM conducts a Monte-Carlo estimation of adversarial examples for DMs. Extensive experiments show that the estimated adversarial examples can effectively hinder DMs from extracting their features. Our method can be a powerful tool for human artists to protect their copyright against infringers with DM-based AI-for-Art applications.