 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePFLlib: Personalized Federated Learning Algorithm Library
Dec 08, 2023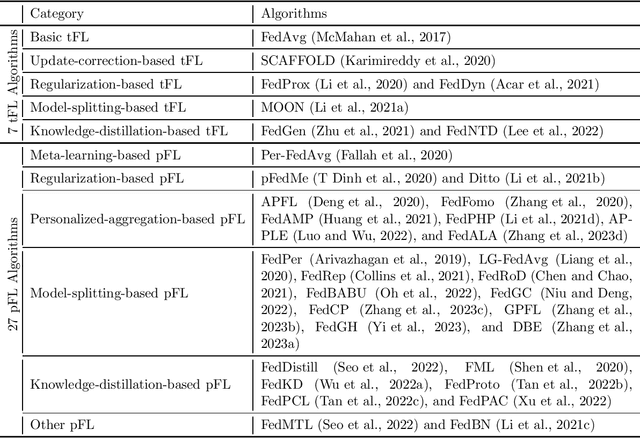

Amid the ongoing advancements in Federated Learning (FL), a machine learning paradigm that allows collaborative learning with data privacy protection, personalized FL (pFL) has gained significant prominence as a research direction within the FL domain. Whereas traditional FL (tFL) focuses on jointly learning a global model, pFL aims to achieve a balance between the global and personalized objectives of each client in FL settings. To foster the pFL research community, we propose PFLlib, a comprehensive pFL algorithm library with an integrated evaluation platform. In PFLlib, We implement 34 state-of-the-art FL algorithms (including 7 classic tFL algorithms and 27 pFL algorithms) and provide various evaluation environments with three statistically heterogeneous scenarios and 14 datasets. At present, PFLlib has already gained 850 stars and 199 forks on GitHub.
Eliminating Domain Bias for Federated Learning in Representation Space
Nov 25, 2023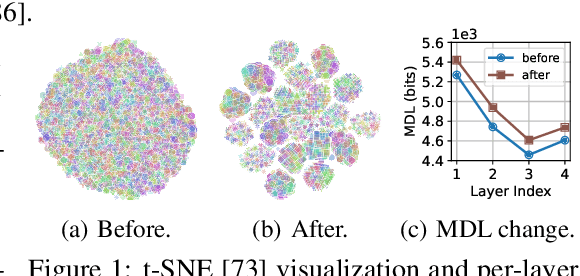
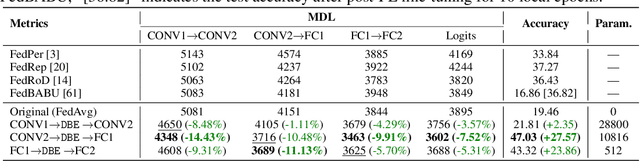
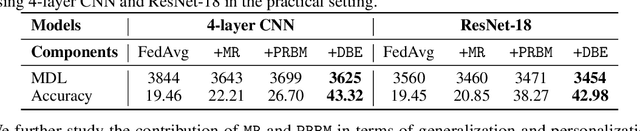
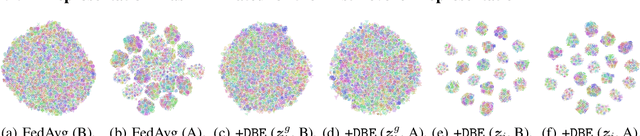
Recently, federated learning (FL) is popular for its privacy-preserving and collaborative learning abilities. However, under statistically heterogeneous scenarios, we observe that biased data domains on clients cause a representation bias phenomenon and further degenerate generic representations during local training, i.e., the representation degeneration phenomenon. To address these issues, we propose a general framework Domain Bias Eliminator (DBE) for FL. Our theoretical analysis reveals that DBE can promote bi-directional knowledge transfer between server and client, as it reduces the domain discrepancy between server and client in representation space. Besides, extensive experiments on four datasets show that DBE can greatly improve existing FL methods in both generalization and personalization abilities. The DBE-equipped FL method can outperform ten state-of-the-art personalized FL methods by a large margin. Our code is public at https://github.com/TsingZ0/DBE.
GPFL: Simultaneously Learning Global and Personalized Feature Information for Personalized Federated Learning
Aug 20, 2023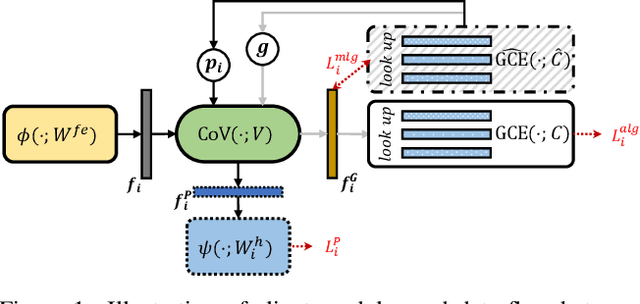
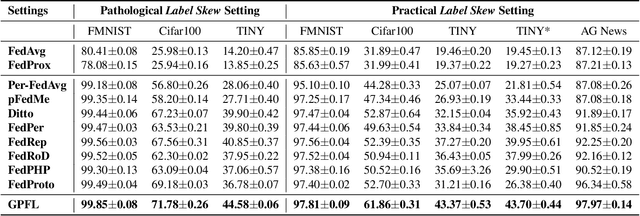
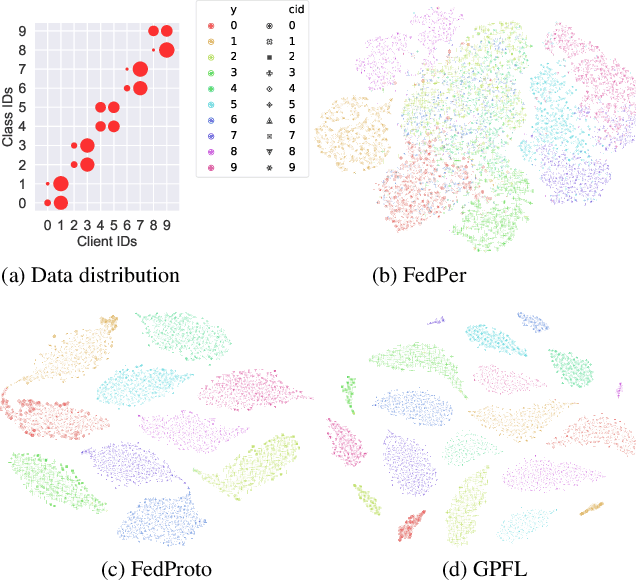
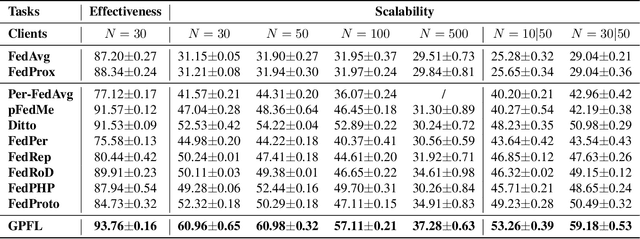
Federated Learning (FL) is popular for its privacy-preserving and collaborative learning capabilities. Recently, personalized FL (pFL) has received attention for its ability to address statistical heterogeneity and achieve personalization in FL. However, from the perspective of feature extraction, most existing pFL methods only focus on extracting global or personalized feature information during local training, which fails to meet the collaborative learning and personalization goals of pFL. To address this, we propose a new pFL method, named GPFL, to simultaneously learn global and personalized feature information on each client. We conduct extensive experiments on six datasets in three statistically heterogeneous settings and show the superiority of GPFL over ten state-of-the-art methods regarding effectiveness, scalability, fairness, stability, and privacy. Besides, GPFL mitigates overfitting and outperforms the baselines by up to 8.99% in accuracy.
FedCP: Separating Feature Information for Personalized Federated Learning via Conditional Policy
Jul 01, 2023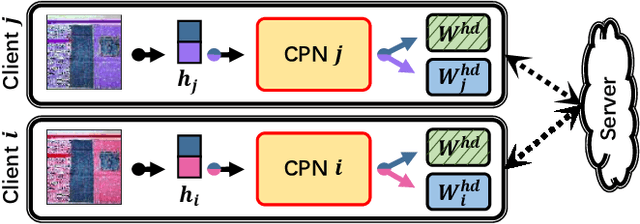

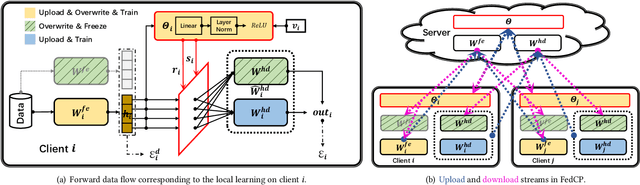
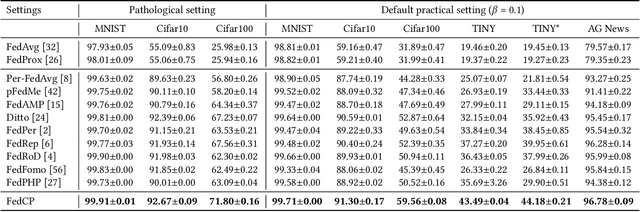
Recently, personalized federated learning (pFL) has attracted increasing attention in privacy protection, collaborative learning, and tackling statistical heterogeneity among clients, e.g., hospitals, mobile smartphones, etc. Most existing pFL methods focus on exploiting the global information and personalized information in the client-level model parameters while neglecting that data is the source of these two kinds of information. To address this, we propose the Federated Conditional Policy (FedCP) method, which generates a conditional policy for each sample to separate the global information and personalized information in its features and then processes them by a global head and a personalized head, respectively. FedCP is more fine-grained to consider personalization in a sample-specific manner than existing pFL methods. Extensive experiments in computer vision and natural language processing domains show that FedCP outperforms eleven state-of-the-art methods by up to 6.69%. Furthermore, FedCP maintains its superiority when some clients accidentally drop out, which frequently happens in mobile settings. Our code is public at https://github.com/TsingZ0/FedCP.
Adversarial Example Does Good: Preventing Painting Imitation from Diffusion Models via Adversarial Examples
Feb 09, 2023



Diffusion Models (DMs) achieve state-of-the-art performance in generative tasks, boosting a wave in AI for Art. Despite the success of commercialization, DMs meanwhile provide tools for copyright violations, where infringers benefit from illegally using paintings created by human artists to train DMs and generate novel paintings in a similar style. In this paper, we show that it is possible to create an image $x'$ that is similar to an image $x$ for human vision but unrecognizable for DMs. We build a framework to define and evaluate this adversarial example for diffusion models. Based on the framework, we further propose AdvDM, an algorithm to generate adversarial examples for DMs. By optimizing upon different latent variables sampled from the reverse process of DMs, AdvDM conducts a Monte-Carlo estimation of adversarial examples for DMs. Extensive experiments show that the estimated adversarial examples can effectively hinder DMs from extracting their features. Our method can be a powerful tool for human artists to protect their copyright against infringers with DM-based AI-for-Art applications.
FedALA: Adaptive Local Aggregation for Personalized Federated Learning
Dec 02, 2022



A key challenge in federated learning (FL) is the statistical heterogeneity that impairs the generalization of the global model on each client. To address this, we propose a method Federated learning with Adaptive Local Aggregation (FedALA) by capturing the desired information in the global model for client models in personalized FL. The key component of FedALA is an Adaptive Local Aggregation (ALA) module, which can adaptively aggregate the downloaded global model and local model towards the local objective on each client to initialize the local model before training in each iteration. To evaluate the effectiveness of FedALA, we conduct extensive experiments with five benchmark datasets in computer vision and natural language processing domains. FedALA outperforms eleven state-of-the-art baselines by up to 3.27% in test accuracy. Furthermore, we also apply ALA module to other federated learning methods and achieve up to 24.19% improvement in test accuracy.
Quantifying consensus of rankings based on q-support patterns
May 30, 2019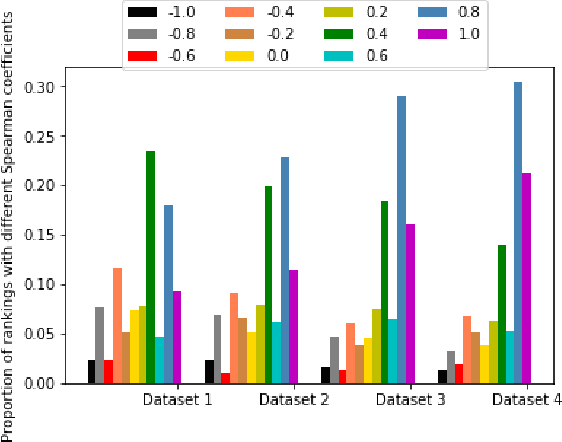
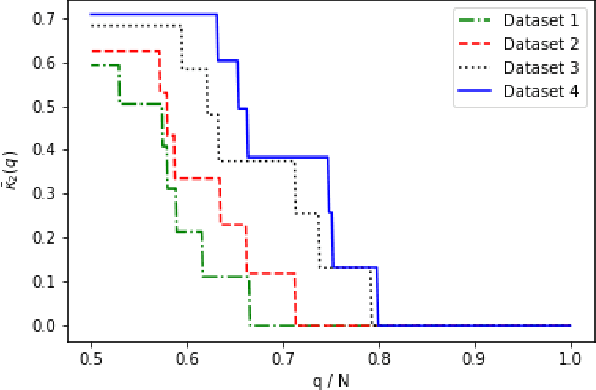
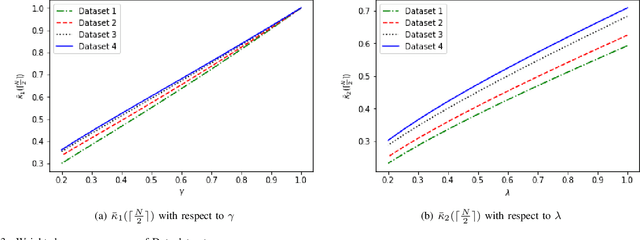
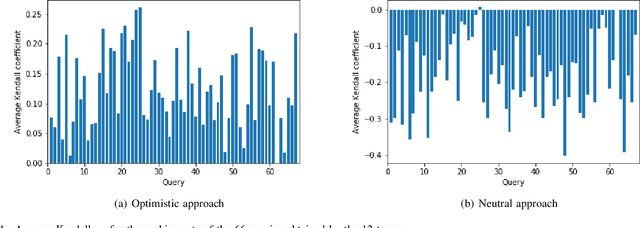
Rankings, representing preferences over a set of candidates, are widely used in many information systems, e.g., group decision making. It is of great importance to evaluate the consensus of the obtained rankings from multiple agents. There is often no ground truth available for a ranking task. An overall measure of the consensus degree enables us to have a clear cognition about the ranking data. Moreover, it could provide a quantitative indicator for consensus comparison between groups and further improvement of a ranking system. In this paper, a novel consensus quantifying approach, without the need for any correlation or distance functions, is proposed based on a concept of q-support patterns of rankings. The q-support patterns represent the commonality embedded in a set of rankings. A method for detecting outliers in a set of rankings is naturally derived from the proposed consensus quantifying approach. Experimental studies are conducted to demonstrate the effectiveness of the proposed approach.