 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFPO: Likelihood-Free Policy Optimization for Masked Diffusion Models
Mar 02, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has achieved remarkable success in improving autoregressive models, especially in domains requiring correctness like mathematical reasoning and code generation. However, directly applying such paradigms to Diffusion Large Language Models (dLLMs) is fundamentally hindered by the intractability of exact likelihood computation, which forces existing methods to rely on high-variance approximations. To bridge this gap, we propose Likelihood-Free Policy Optimization (LFPO), a native framework that maps the concept of vector field flow matching to the discrete token space. Specifically, LFPO formulates alignment as geometric velocity rectification, which directly optimizes denoising logits via contrastive updates. This design effectively bypasses the errors inherent in likelihood approximation, yielding the precise gradient estimation. Furthermore, LFPO enforce consistency by predicting final solutions from intermediate steps, effectively straightening the probability flow to enable high-quality generation with significantly fewer iterations. Extensive experiments demonstrate that LFPO not only outperforms state-of-the-art baselines on code and reasoning benchmarks but also accelerates inference by approximately 20% through reduced diffusion steps.
ReCreate: Reasoning and Creating Domain Agents Driven by Experience
Jan 16, 2026Large Language Model agents are reshaping the industrial landscape. However, most practical agents remain human-designed because tasks differ widely, making them labor-intensive to build. This situation poses a central question: can we automatically create and adapt domain agents in the wild? While several recent approaches have sought to automate agent creation, they typically treat agent generation as a black-box procedure and rely solely on final performance metrics to guide the process. Such strategies overlook critical evidence explaining why an agent succeeds or fails, and often require high computational costs. To address these limitations, we propose ReCreate, an experience-driven framework for the automatic creation of domain agents. ReCreate systematically leverages agent interaction histories, which provide rich concrete signals on both the causes of success or failure and the avenues for improvement. Specifically, we introduce an agent-as-optimizer paradigm that effectively learns from experience via three key components: (i) an experience storage and retrieval mechanism for on-demand inspection; (ii) a reasoning-creating synergy pipeline that maps execution experience into scaffold edits; and (iii) hierarchical updates that abstract instance-level details into reusable domain patterns. In experiments across diverse domains, ReCreate consistently outperforms human-designed agents and existing automated agent generation methods, even when starting from minimal seed scaffolds.
HtFLlib: A Comprehensive Heterogeneous Federated Learning Library and Benchmark
Jun 04, 2025



As AI evolves, collaboration among heterogeneous models helps overcome data scarcity by enabling knowledge transfer across institutions and devices. Traditional Federated Learning (FL) only supports homogeneous models, limiting collaboration among clients with heterogeneous model architectures. To address this, Heterogeneous Federated Learning (HtFL) methods are developed to enable collaboration across diverse heterogeneous models while tackling the data heterogeneity issue at the same time. However, a comprehensive benchmark for standardized evaluation and analysis of the rapidly growing HtFL methods is lacking. Firstly, the highly varied datasets, model heterogeneity scenarios, and different method implementations become hurdles to making easy and fair comparisons among HtFL methods. Secondly, the effectiveness and robustness of HtFL methods are under-explored in various scenarios, such as the medical domain and sensor signal modality. To fill this gap, we introduce the first Heterogeneous Federated Learning Library (HtFLlib), an easy-to-use and extensible framework that integrates multiple datasets and model heterogeneity scenarios, offering a robust benchmark for research and practical applications. Specifically, HtFLlib integrates (1) 12 datasets spanning various domains, modalities, and data heterogeneity scenarios; (2) 40 model architectures, ranging from small to large, across three modalities; (3) a modularized and easy-to-extend HtFL codebase with implementations of 10 representative HtFL methods; and (4) systematic evaluations in terms of accuracy, convergence, computation costs, and communication costs. We emphasize the advantages and potential of state-of-the-art HtFL methods and hope that HtFLlib will catalyze advancing HtFL research and enable its broader applications. The code is released at https://github.com/TsingZ0/HtFLlib.
Towards Harnessing the Collaborative Power of Large and Small Models for Domain Tasks
Apr 24, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but they require vast amounts of data and computational resources. In contrast, smaller models (SMs), while less powerful, can be more efficient and tailored to specific domains. In this position paper, we argue that taking a collaborative approach, where large and small models work synergistically, can accelerate the adaptation of LLMs to private domains and unlock new potential in AI. We explore various strategies for model collaboration and identify potential challenges and opportunities. Building upon this, we advocate for industry-driven research that prioritizes multi-objective benchmarks on real-world private datasets and applications.
FedMABench: Benchmarking Mobile Agents on Decentralized Heterogeneous User Data
Mar 07, 2025Mobile agents have attracted tremendous research participation recently. Traditional approaches to mobile agent training rely on centralized data collection, leading to high cost and limited scalability. Distributed training utilizing federated learning offers an alternative by harnessing real-world user data, providing scalability and reducing costs. However, pivotal challenges, including the absence of standardized benchmarks, hinder progress in this field. To tackle the challenges, we introduce FedMABench, the first benchmark for federated training and evaluation of mobile agents, specifically designed for heterogeneous scenarios. FedMABench features 6 datasets with 30+ subsets, 8 federated algorithms, 10+ base models, and over 800 apps across 5 categories, providing a comprehensive framework for evaluating mobile agents across diverse environments. Through extensive experiments, we uncover several key insights: federated algorithms consistently outperform local training; the distribution of specific apps plays a crucial role in heterogeneity; and, even apps from distinct categories can exhibit correlations during training. FedMABench is publicly available at: https://github.com/wwh0411/FedMABench with the datasets at: https://huggingface.co/datasets/wwh0411/FedMABench.
FedL2G: Learning to Guide Local Training in Heterogeneous Federated Learning
Oct 09, 2024



Data and model heterogeneity are two core issues in Heterogeneous Federated Learning (HtFL). In scenarios with heterogeneous model architectures, aggregating model parameters becomes infeasible, leading to the use of prototypes (i.e., class representative feature vectors) for aggregation and guidance. However, they still experience a mismatch between the extra guiding objective and the client's original local objective when aligned with global prototypes. Thus, we propose a Federated Learning-to-Guide (FedL2G) method that adaptively learns to guide local training in a federated manner and ensures the extra guidance is beneficial to clients' original tasks. With theoretical guarantees, FedL2G efficiently implements the learning-to-guide process using only first-order derivatives w.r.t. model parameters and achieves a non-convex convergence rate of O(1/T). We conduct extensive experiments on two data heterogeneity and six model heterogeneity settings using 14 heterogeneous model architectures (e.g., CNNs and ViTs) to demonstrate FedL2G's superior performance compared to six counterparts.
FuseGen: PLM Fusion for Data-generation based Zero-shot Learning
Jun 18, 2024



Data generation-based zero-shot learning, although effective in training Small Task-specific Models (STMs) via synthetic datasets generated by Pre-trained Language Models (PLMs), is often limited by the low quality of such synthetic datasets. Previous solutions have primarily focused on single PLM settings, where synthetic datasets are typically restricted to specific sub-spaces and often deviate from real-world distributions, leading to severe distribution bias. To mitigate such bias, we propose FuseGen, a novel data generation-based zero-shot learning framework that introduces a new criteria for subset selection from synthetic datasets via utilizing multiple PLMs and trained STMs. The chosen subset provides in-context feedback to each PLM, enhancing dataset quality through iterative data generation. Trained STMs are then used for sample re-weighting as well, further improving data quality. Extensive experiments across diverse tasks demonstrate that FuseGen substantially outperforms existing methods, highly effective in boosting STM performance in a PLM-agnostic way. Code is provided in https://github.com/LindaLydia/FuseGen.
An Upload-Efficient Scheme for Transferring Knowledge From a Server-Side Pre-trained Generator to Clients in Heterogeneous Federated Learning
Mar 23, 2024
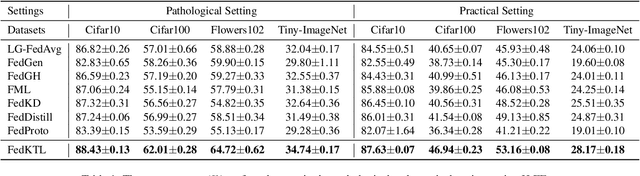
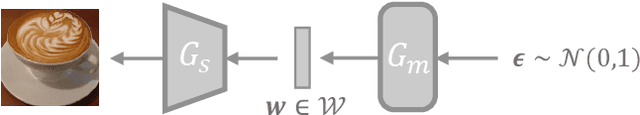
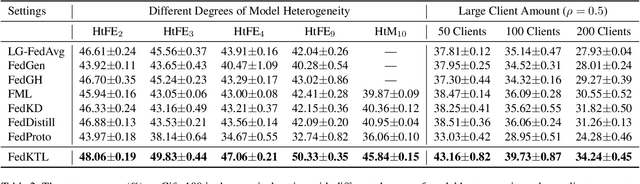
Heterogeneous Federated Learning (HtFL) enables collaborative learning on multiple clients with different model architectures while preserving privacy. Despite recent research progress, knowledge sharing in HtFL is still difficult due to data and model heterogeneity. To tackle this issue, we leverage the knowledge stored in pre-trained generators and propose a new upload-efficient knowledge transfer scheme called Federated Knowledge-Transfer Loop (FedKTL). Our FedKTL can produce client-task-related prototypical image-vector pairs via the generator's inference on the server. With these pairs, each client can transfer pre-existing knowledge from the generator to its local model through an additional supervised local task. We conduct extensive experiments on four datasets under two types of data heterogeneity with 14 kinds of models including CNNs and ViTs. Results show that our upload-efficient FedKTL surpasses seven state-of-the-art methods by up to 7.31% in accuracy. Moreover, our knowledge transfer scheme is applicable in scenarios with only one edge client. Code: https://github.com/TsingZ0/FedKTL
FedTGP: Trainable Global Prototypes with Adaptive-Margin-Enhanced Contrastive Learning for Data and Model Heterogeneity in Federated Learning
Jan 06, 2024

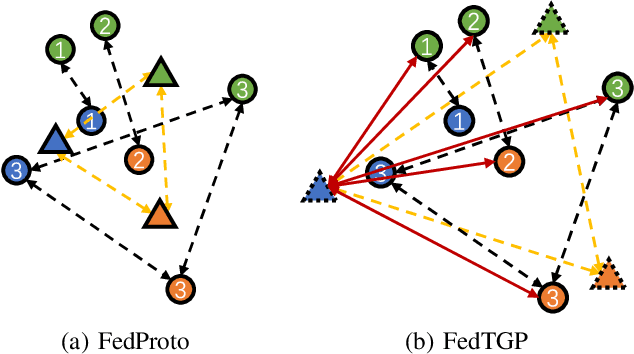

Recently, Heterogeneous Federated Learning (HtFL) has attracted attention due to its ability to support heterogeneous models and data. To reduce the high communication cost of transmitting model parameters, a major challenge in HtFL, prototype-based HtFL methods are proposed to solely share class representatives, a.k.a, prototypes, among heterogeneous clients while maintaining the privacy of clients' models. However, these prototypes are naively aggregated into global prototypes on the server using weighted averaging, resulting in suboptimal global knowledge which negatively impacts the performance of clients. To overcome this challenge, we introduce a novel HtFL approach called FedTGP, which leverages our Adaptive-margin-enhanced Contrastive Learning (ACL) to learn Trainable Global Prototypes (TGP) on the server. By incorporating ACL, our approach enhances prototype separability while preserving semantic meaning. Extensive experiments with twelve heterogeneous models demonstrate that our FedTGP surpasses state-of-the-art methods by up to 9.08% in accuracy while maintaining the communication and privacy advantages of prototype-based HtFL. Our code is available at https://github.com/TsingZ0/FedTGP.
PFLlib: Personalized Federated Learning Algorithm Library
Dec 08, 2023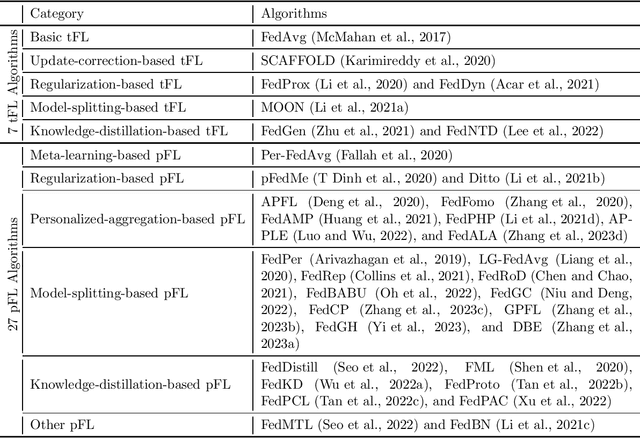

Amid the ongoing advancements in Federated Learning (FL), a machine learning paradigm that allows collaborative learning with data privacy protection, personalized FL (pFL) has gained significant prominence as a research direction within the FL domain. Whereas traditional FL (tFL) focuses on jointly learning a global model, pFL aims to achieve a balance between the global and personalized objectives of each client in FL settings. To foster the pFL research community, we propose PFLlib, a comprehensive pFL algorithm library with an integrated evaluation platform. In PFLlib, We implement 34 state-of-the-art FL algorithms (including 7 classic tFL algorithms and 27 pFL algorithms) and provide various evaluation environments with three statistically heterogeneous scenarios and 14 datasets. At present, PFLlib has already gained 850 stars and 199 forks on GitHub.