 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Harnessing the Collaborative Power of Large and Small Models for Domain Tasks
Apr 24, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but they require vast amounts of data and computational resources. In contrast, smaller models (SMs), while less powerful, can be more efficient and tailored to specific domains. In this position paper, we argue that taking a collaborative approach, where large and small models work synergistically, can accelerate the adaptation of LLMs to private domains and unlock new potential in AI. We explore various strategies for model collaboration and identify potential challenges and opportunities. Building upon this, we advocate for industry-driven research that prioritizes multi-objective benchmarks on real-world private datasets and applications.
FuseGen: PLM Fusion for Data-generation based Zero-shot Learning
Jun 18, 2024



Data generation-based zero-shot learning, although effective in training Small Task-specific Models (STMs) via synthetic datasets generated by Pre-trained Language Models (PLMs), is often limited by the low quality of such synthetic datasets. Previous solutions have primarily focused on single PLM settings, where synthetic datasets are typically restricted to specific sub-spaces and often deviate from real-world distributions, leading to severe distribution bias. To mitigate such bias, we propose FuseGen, a novel data generation-based zero-shot learning framework that introduces a new criteria for subset selection from synthetic datasets via utilizing multiple PLMs and trained STMs. The chosen subset provides in-context feedback to each PLM, enhancing dataset quality through iterative data generation. Trained STMs are then used for sample re-weighting as well, further improving data quality. Extensive experiments across diverse tasks demonstrate that FuseGen substantially outperforms existing methods, highly effective in boosting STM performance in a PLM-agnostic way. Code is provided in https://github.com/LindaLydia/FuseGen.
VFLAIR: A Research Library and Benchmark for Vertical Federated Learning
Oct 15, 2023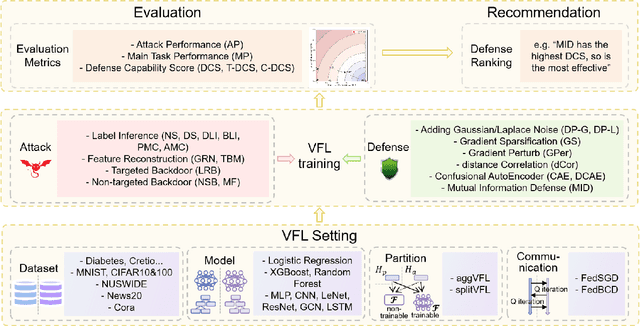


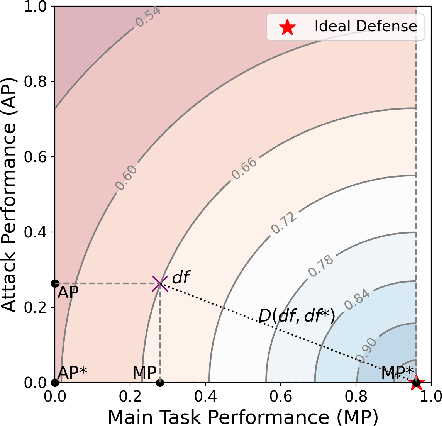
Vertical Federated Learning (VFL) has emerged as a collaborative training paradigm that allows participants with different features of the same group of users to accomplish cooperative training without exposing their raw data or model parameters. VFL has gained significant attention for its research potential and real-world applications in recent years, but still faces substantial challenges, such as in defending various kinds of data inference and backdoor attacks. Moreover, most of existing VFL projects are industry-facing and not easily used for keeping track of the current research progress. To address this need, we present an extensible and lightweight VFL framework VFLAIR (available at https://github.com/FLAIR-THU/VFLAIR), which supports VFL training with a variety of models, datasets and protocols, along with standardized modules for comprehensive evaluations of attacks and defense strategies. We also benchmark 11 attacks and 8 defenses performance under different communication and model partition settings and draw concrete insights and recommendations on the choice of defense strategies for different practical VFL deployment scenario.
Mutual Information Regularization for Vertical Federated Learning
Jan 01, 2023



Vertical Federated Learning (VFL) is widely utilized in real-world applications to enable collaborative learning while protecting data privacy and safety. However, previous works show that parties without labels (passive parties) in VFL can infer the sensitive label information owned by the party with labels (active party) or execute backdoor attacks to VFL. Meanwhile, active party can also infer sensitive feature information from passive party. All these pose new privacy and security challenges to VFL systems. We propose a new general defense method which limits the mutual information between private raw data, including both features and labels, and intermediate outputs to achieve a better trade-off between model utility and privacy. We term this defense Mutual Information Regularization Defense (MID). We theoretically and experimentally testify the effectiveness of our MID method in defending existing attacks in VFL, including label inference attacks, backdoor attacks and feature reconstruction attacks.
Vertical Federated Learning
Nov 24, 2022



Vertical Federated Learning (VFL) is a federated learning setting where multiple parties with different features about the same set of users jointly train machine learning models without exposing their raw data or model parameters. Motivated by the rapid growth in VFL research and real-world applications, we provide a comprehensive review of the concept and algorithms of VFL, as well as current advances and challenges in various aspects, including effectiveness, efficiency, and privacy. We provide an exhaustive categorization for VFL settings and privacy-preserving protocols and comprehensively analyze the privacy attacks and defense strategies for each protocol. In the end, we propose a unified framework, termed VFLow, which considers the VFL problem under communication, computation, privacy, and effectiveness constraints. Finally, we review the most recent advances in industrial applications, highlighting open challenges and future directions for VFL.
Defending Label Inference and Backdoor Attacks in Vertical Federated Learning
Dec 10, 2021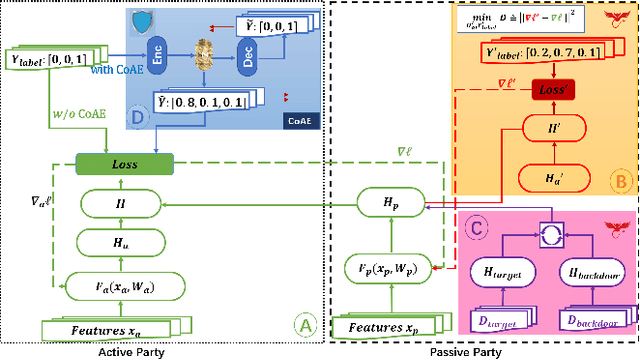

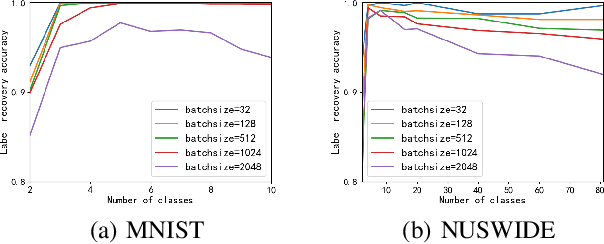
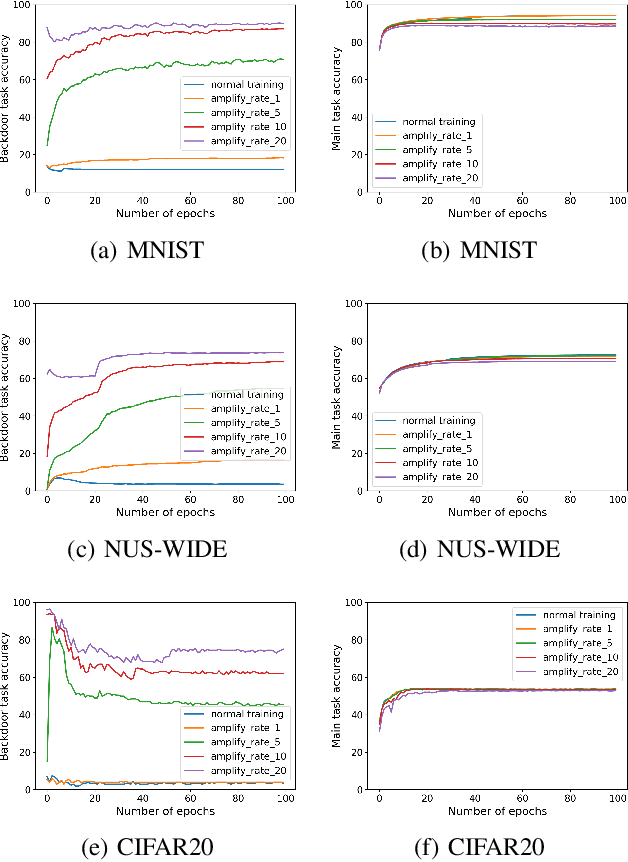
In collaborative learning settings like federated learning, curious parities might be honest but are attempting to infer other parties' private data through inference attacks while malicious parties might manipulate the learning process for their own purposes through backdoor attacks. However, most existing works only consider the federated learning scenario where data are partitioned by samples (HFL). The feature-partitioned federated learning (VFL) can be another important scenario in many real-world applications. Attacks and defenses in such scenarios are especially challenging when the attackers and the defenders are not able to access the features or model parameters of other participants. Previous works have only shown that private labels can be reconstructed from per-sample gradients. In this paper, we first show that private labels can be reconstructed when only batch-averaged gradients are revealed, which is against the common presumption. In addition, we show that a passive party in VFL can even replace its corresponding labels in the active party with a target label through a gradient-replacement attack. To defend against the first attack, we introduce a novel technique termed confusional autoencoder (CoAE), based on autoencoder and entropy regularization. We demonstrate that label inference attacks can be successfully blocked by this technique while hurting less main task accuracy compared to existing methods. Our CoAE technique is also effective in defending the gradient-replacement backdoor attack, making it an universal and practical defense strategy with no change to the original VFL protocol. We demonstrate the effectiveness of our approaches under both two-party and multi-party VFL settings. To the best of our knowledge, this is the first systematic study to deal with label inference and backdoor attacks in the feature-partitioned federated learning framework.