 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedEval-LLM: Federated Evaluation of Large Language Models on Downstream Tasks with Collective Wisdom
Apr 18, 2024



Federated Learning (FL) has emerged as a promising solution for collaborative training of large language models (LLMs). However, the integration of LLMs into FL introduces new challenges, particularly concerning the evaluation of LLMs. Traditional evaluation methods that rely on labeled test sets and similarity-based metrics cover only a subset of the acceptable answers, thereby failing to accurately reflect the performance of LLMs on generative tasks. Meanwhile, although automatic evaluation methods that leverage advanced LLMs present potential, they face critical risks of data leakage due to the need to transmit data to external servers and suboptimal performance on downstream tasks due to the lack of domain knowledge. To address these issues, we propose a Federated Evaluation framework of Large Language Models, named FedEval-LLM, that provides reliable performance measurements of LLMs on downstream tasks without the reliance on labeled test sets and external tools, thus ensuring strong privacy-preserving capability. FedEval-LLM leverages a consortium of personalized LLMs from participants as referees to provide domain knowledge and collective evaluation capability, thus aligning to the respective downstream tasks and mitigating uncertainties and biases associated with a single referee. Experimental results demonstrate a significant improvement in the evaluation capability of personalized evaluation models on downstream tasks. When applied to FL, these evaluation models exhibit strong agreement with human preference and RougeL-score on meticulously curated test sets. FedEval-LLM effectively overcomes the limitations of traditional metrics and the reliance on external services, making it a promising framework for the evaluation of LLMs within collaborative training scenarios.
A Communication Theory Perspective on Prompting Engineering Methods for Large Language Models
Oct 24, 2023



The springing up of Large Language Models (LLMs) has shifted the community from single-task-orientated natural language processing (NLP) research to a holistic end-to-end multi-task learning paradigm. Along this line of research endeavors in the area, LLM-based prompting methods have attracted much attention, partially due to the technological advantages brought by prompt engineering (PE) as well as the underlying NLP principles disclosed by various prompting methods. Traditional supervised learning usually requires training a model based on labeled data and then making predictions. In contrast, PE methods directly use the powerful capabilities of existing LLMs (i.e., GPT-3 and GPT-4) via composing appropriate prompts, especially under few-shot or zero-shot scenarios. Facing the abundance of studies related to the prompting and the ever-evolving nature of this field, this article aims to (i) illustrate a novel perspective to review existing PE methods, within the well-established communication theory framework; (ii) facilitate a better/deeper understanding of developing trends of existing PE methods used in four typical tasks; (iii) shed light on promising research directions for future PE methods.
Optimizing Privacy, Utility and Efficiency in Constrained Multi-Objective Federated Learning
May 09, 2023Conventionally, federated learning aims to optimize a single objective, typically the utility. However, for a federated learning system to be trustworthy, it needs to simultaneously satisfy multiple/many objectives, such as maximizing model performance, minimizing privacy leakage and training cost, and being robust to malicious attacks. Multi-Objective Optimization (MOO) aiming to optimize multiple conflicting objectives at the same time is quite suitable for solving the optimization problem of Trustworthy Federated Learning (TFL). In this paper, we unify MOO and TFL by formulating the problem of constrained multi-objective federated learning (CMOFL). Under this formulation, existing MOO algorithms can be adapted to TFL straightforwardly. Different from existing CMOFL works focusing on utility, efficiency, fairness, and robustness, we consider optimizing privacy leakage along with utility loss and training cost, the three primary objectives of a TFL system. We develop two improved CMOFL algorithms based on NSGA-II and PSL, respectively, for effectively and efficiently finding Pareto optimal solutions, and we provide theoretical analysis on their convergence. We design specific measurements of privacy leakage, utility loss, and training cost for three privacy protection mechanisms: Randomization, BatchCrypt (An efficient version of homomorphic encryption), and Sparsification. Empirical experiments conducted under each of the three protection mechanisms demonstrate the effectiveness of our proposed algorithms.
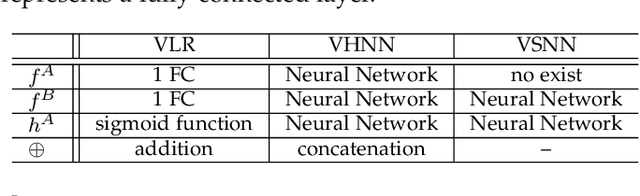
Vertical Federated Learning
Nov 24, 2022



Vertical Federated Learning (VFL) is a federated learning setting where multiple parties with different features about the same set of users jointly train machine learning models without exposing their raw data or model parameters. Motivated by the rapid growth in VFL research and real-world applications, we provide a comprehensive review of the concept and algorithms of VFL, as well as current advances and challenges in various aspects, including effectiveness, efficiency, and privacy. We provide an exhaustive categorization for VFL settings and privacy-preserving protocols and comprehensively analyze the privacy attacks and defense strategies for each protocol. In the end, we propose a unified framework, termed VFLow, which considers the VFL problem under communication, computation, privacy, and effectiveness constraints. Finally, we review the most recent advances in industrial applications, highlighting open challenges and future directions for VFL.
A Framework for Evaluating Privacy-Utility Trade-off in Vertical Federated Learning
Sep 09, 2022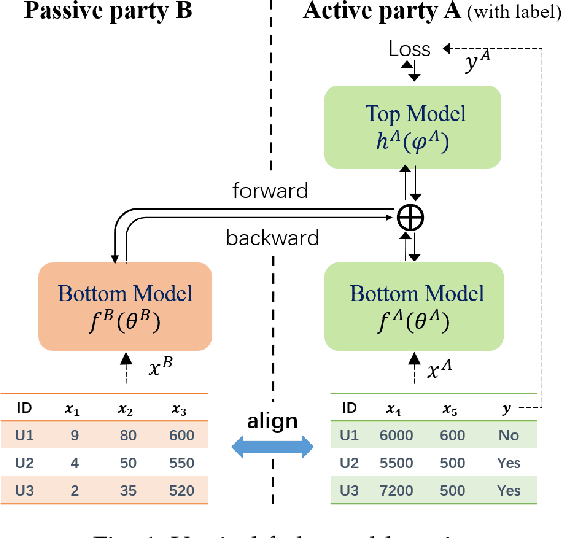

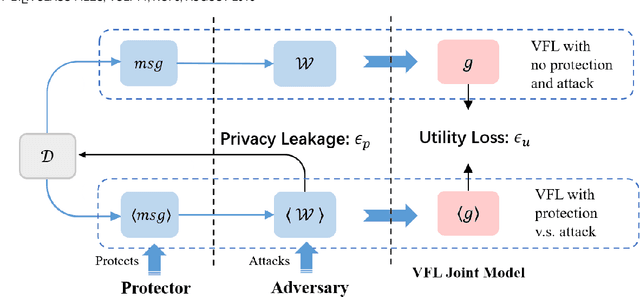
Federated learning (FL) has emerged as a practical solution to tackle data silo issues without compromising user privacy. One of its variants, vertical federated learning (VFL), has recently gained increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to build better machine learning models while preserving user privacy. Current works in VFL concentrate on developing a specific protection or attack mechanism for a particular VFL algorithm. In this work, we propose an evaluation framework that formulates the privacy-utility evaluation problem. We then use this framework as a guide to comprehensively evaluate a broad range of protection mechanisms against most of the state-of-the-art privacy attacks for three widely-deployed VFL algorithms. These evaluations may help FL practitioners select appropriate protection mechanisms given specific requirements. Our evaluation results demonstrate that: the model inversion and most of the label inference attacks can be thwarted by existing protection mechanisms; the model completion (MC) attack is difficult to be prevented, which calls for more advanced MC-targeted protection mechanisms. Based on our evaluation results, we offer concrete advice on improving the privacy-preserving capability of VFL systems.
A Hybrid Self-Supervised Learning Framework for Vertical Federated Learning
Aug 18, 2022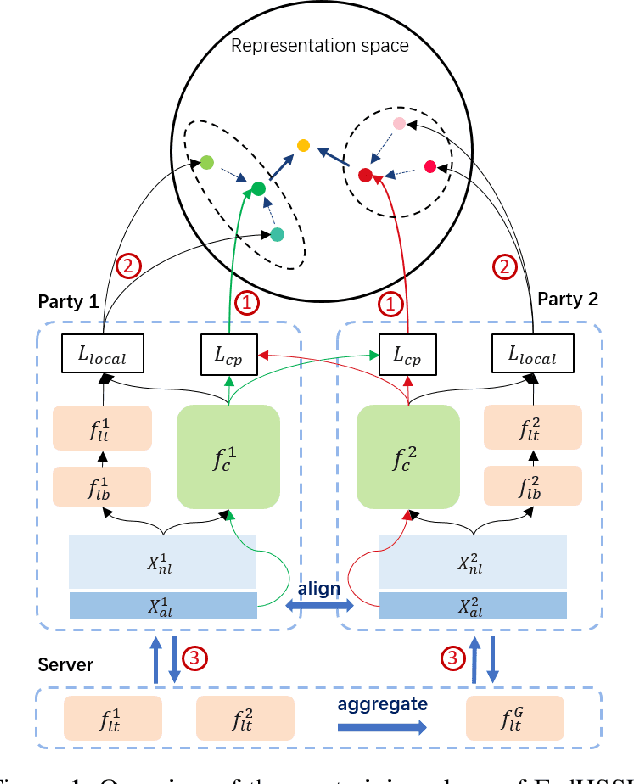


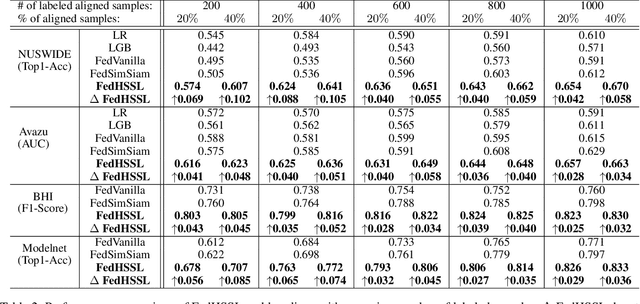
Federated learning (FL) enables independent parties to collaboratively build machine learning (ML) models while protecting data privacy. Vertical federated learning (VFL), a variant of FL, has recently drawn increasing attention as the VFL matches the enterprises' demands of leveraging more valuable features to achieve better model performance without jeopardizing data privacy. However, conventional VFL may run into data deficiency as it is only able to exploit aligned samples (belonging to different parties) with labels, leaving often the majority of unaligned and unlabeled samples unused. The data deficiency hampers the effort of the federation. In this work, we propose a Federated Hybrid Self-Supervised Learning framework, coined FedHSSL, to utilize all available data (including unaligned and unlabeled samples) of participants to train the joint VFL model. The core idea of FedHSSL is to utilize cross-party views (i.e., dispersed features) of samples aligned among parties and local views (i.e., augmentations) of samples within each party to improve the representation learning capability of the joint VFL model through SSL (e.g., SimSiam). FedHSSL further exploits generic features shared among parties to boost the performance of the joint model through partial model aggregation. We empirically demonstrate that our FedHSSL achieves significant performance gains compared with baseline methods, especially when the number of labeled samples is small. We provide an in-depth analysis of FedHSSL regarding privacy leakage, which is rarely discussed in existing self-supervised VFL works. We investigate the protection mechanism for FedHSSL. The results show our protection can thwart the state-of-the-art label inference attack.
Defending Label Inference and Backdoor Attacks in Vertical Federated Learning
Dec 10, 2021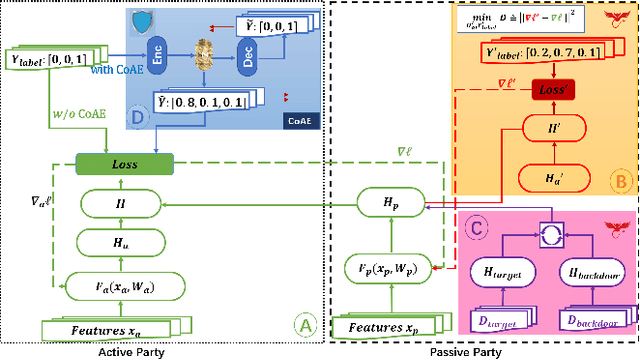

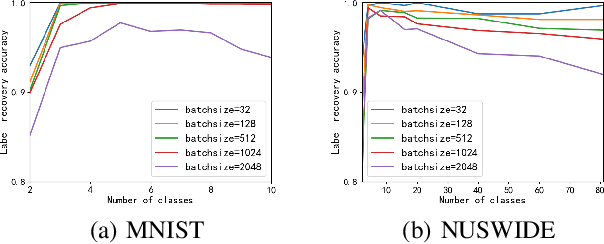
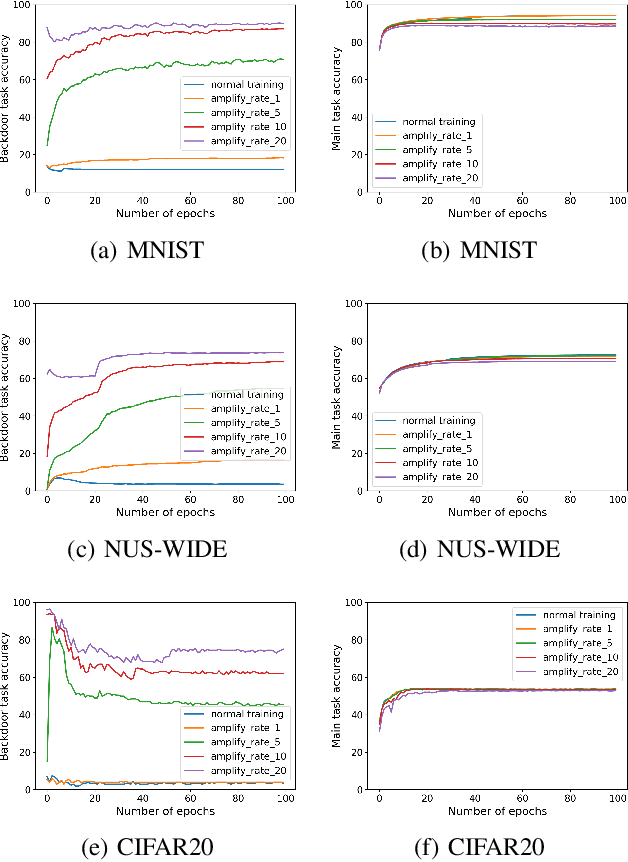
In collaborative learning settings like federated learning, curious parities might be honest but are attempting to infer other parties' private data through inference attacks while malicious parties might manipulate the learning process for their own purposes through backdoor attacks. However, most existing works only consider the federated learning scenario where data are partitioned by samples (HFL). The feature-partitioned federated learning (VFL) can be another important scenario in many real-world applications. Attacks and defenses in such scenarios are especially challenging when the attackers and the defenders are not able to access the features or model parameters of other participants. Previous works have only shown that private labels can be reconstructed from per-sample gradients. In this paper, we first show that private labels can be reconstructed when only batch-averaged gradients are revealed, which is against the common presumption. In addition, we show that a passive party in VFL can even replace its corresponding labels in the active party with a target label through a gradient-replacement attack. To defend against the first attack, we introduce a novel technique termed confusional autoencoder (CoAE), based on autoencoder and entropy regularization. We demonstrate that label inference attacks can be successfully blocked by this technique while hurting less main task accuracy compared to existing methods. Our CoAE technique is also effective in defending the gradient-replacement backdoor attack, making it an universal and practical defense strategy with no change to the original VFL protocol. We demonstrate the effectiveness of our approaches under both two-party and multi-party VFL settings. To the best of our knowledge, this is the first systematic study to deal with label inference and backdoor attacks in the feature-partitioned federated learning framework.
FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning
Nov 16, 2021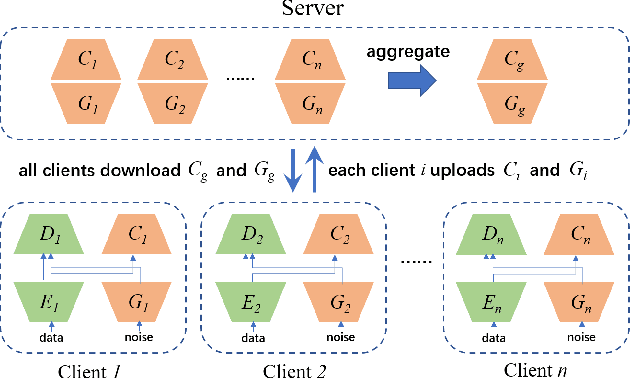
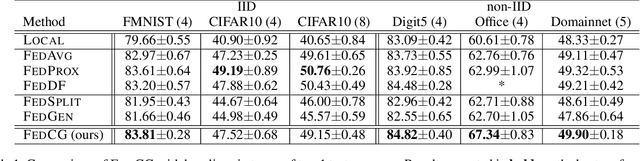
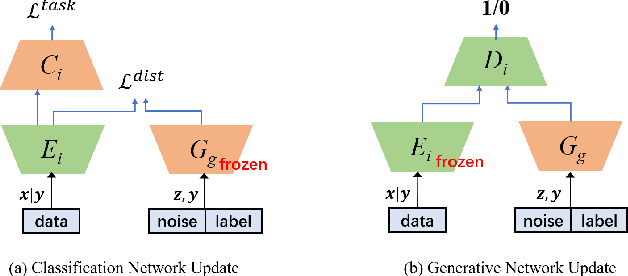

Federated learning (FL) aims to protect data privacy by enabling clients to collaboratively build machine learning models without sharing their private data. However, recent works demonstrate that FL is vulnerable to gradient-based data recovery attacks. Varieties of privacy-preserving technologies have been leveraged to further enhance the privacy of FL. Nonetheless, they either are computational or communication expensive (e.g., homomorphic encryption) or suffer from precision loss (e.g., differential privacy). In this work, we propose \textsc{FedCG}, a novel \underline{fed}erated learning method that leverages \underline{c}onditional \underline{g}enerative adversarial networks to achieve high-level privacy protection while still maintaining competitive model performance. More specifically, \textsc{FedCG} decomposes each client's local network into a private extractor and a public classifier and keeps the extractor local to protect privacy. Instead of exposing extractors which is the culprit of privacy leakage, \textsc{FedCG} shares clients' generators with the server for aggregating common knowledge aiming to enhance the performance of clients' local networks. Extensive experiments demonstrate that \textsc{FedCG} can achieve competitive model performance compared with baseline FL methods, and numerical privacy analysis shows that \textsc{FedCG} has high-level privacy-preserving capability.
Self-supervised Cross-silo Federated Neural Architecture Search
Feb 18, 2021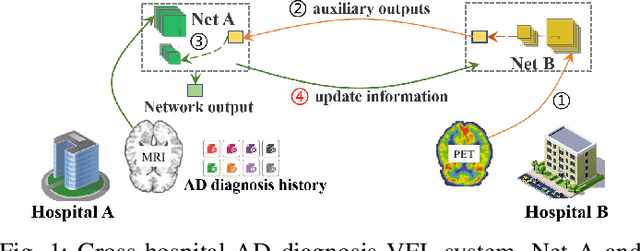
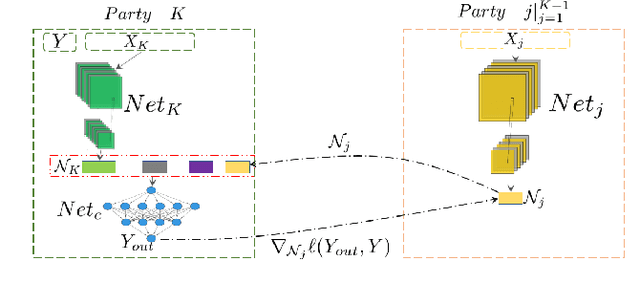
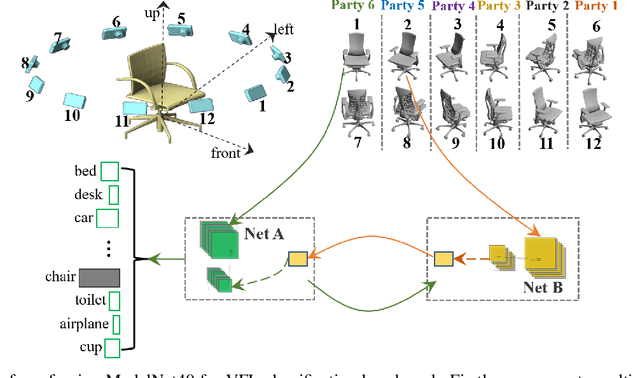
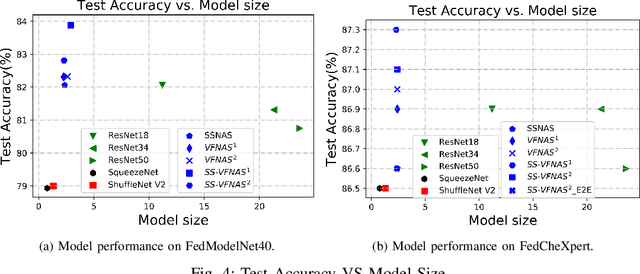
Federated Learning (FL) provides both model performance and data privacy for machine learning tasks where samples or features are distributed among different parties. In the training process of FL, no party has a global view of data distributions or model architectures of other parties. Thus the manually-designed architectures may not be optimal. In the past, Neural Architecture Search (NAS) has been applied to FL to address this critical issue. However, existing Federated NAS approaches require prohibitive communication and computation effort, as well as the availability of high-quality labels. In this work, we present Self-supervised Vertical Federated Neural Architecture Search (SS-VFNAS) for automating FL where participants hold feature-partitioned data, a common cross-silo scenario called Vertical Federated Learning (VFL). In the proposed framework, each party first conducts NAS using self-supervised approach to find a local optimal architecture with its own data. Then, parties collaboratively improve the local optimal architecture in a VFL framework with supervision. We demonstrate experimentally that our approach has superior performance, communication efficiency and privacy compared to Federated NAS and is capable of generating high-performance and highly-transferable heterogeneous architectures even with insufficient overlapping samples, providing automation for those parties without deep learning expertise.