 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Auction-Based Incentive Mechanism Design for Horizontal Federated Learning with Budget Constraint
Jan 22, 2022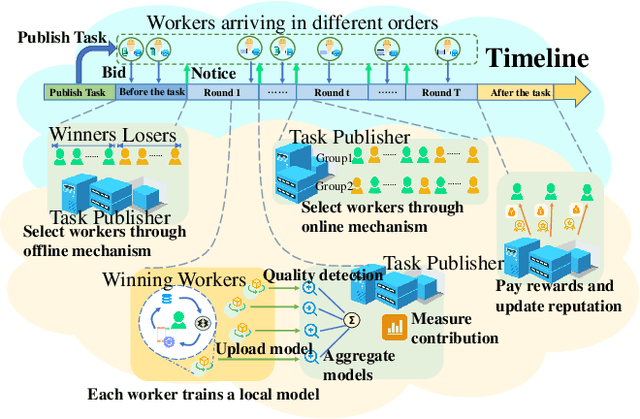
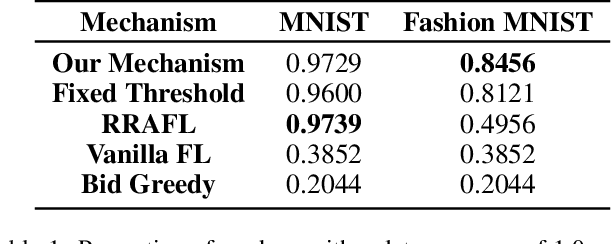
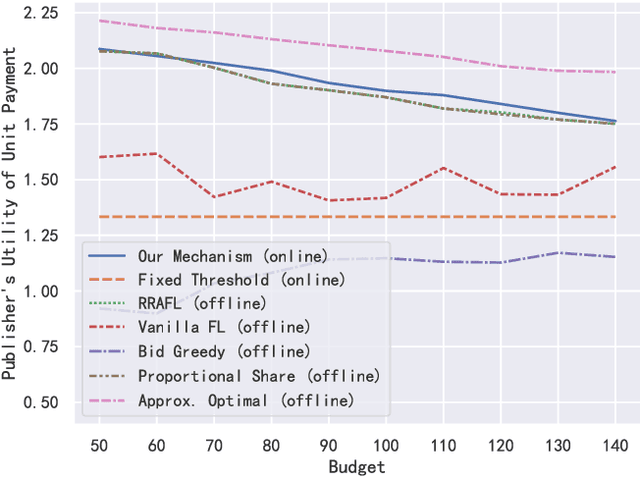
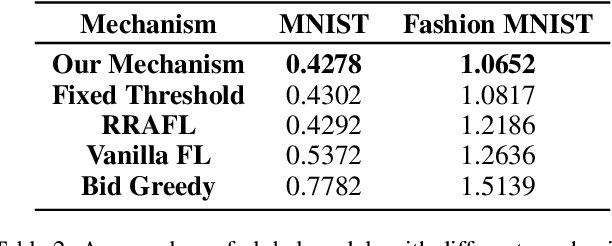
Federated learning makes it possible for all parties with data isolation to train the model collaboratively and efficiently while satisfying privacy protection. To obtain a high-quality model, an incentive mechanism is necessary to motivate more high-quality workers with data and computing power. The existing incentive mechanisms are applied in offline scenarios, where the task publisher collects all bids and selects workers before the task. However, it is practical that different workers arrive online in different orders before or during the task. Therefore, we propose a reverse auction-based online incentive mechanism for horizontal federated learning with budget constraint. Workers submit bids when they arrive online. The task publisher with a limited budget leverages the information of the arrived workers to decide on whether to select the new worker. Theoretical analysis proves that our mechanism satisfies budget feasibility, computational efficiency, individual rationality, consumer sovereignty, time truthfulness, and cost truthfulness with a sufficient budget. The experimental results show that our online mechanism is efficient and can obtain high-quality models.
Auction-Based Ex-Post-Payment Incentive Mechanism Design for Horizontal Federated Learning with Reputation and Contribution Measurement
Jan 07, 2022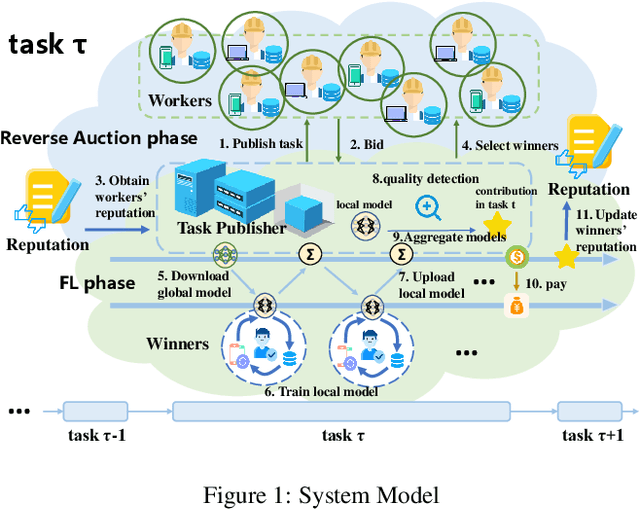
Federated learning trains models across devices with distributed data, while protecting the privacy and obtaining a model similar to that of centralized ML. A large number of workers with data and computing power are the foundation of federal learning. However, the inevitable costs prevent self-interested workers from serving for free. Moreover, due to data isolation, task publishers lack effective methods to select, evaluate and pay reliable workers with high-quality data. Therefore, we design an auction-based incentive mechanism for horizontal federated learning with reputation and contribution measurement. By designing a reasonable method of measuring contribution, we establish the reputation of workers, which is easy to decline and difficult to improve. Through reverse auctions, workers bid for tasks, and the task publisher selects workers combining reputation and bid price. With the budget constraint, winning workers are paid based on performance. We proved that our mechanism satisfies the individual rationality of the honest worker, budget feasibility, truthfulness, and computational efficiency.
Privacy-preserving Federated Adversarial Domain Adaption over Feature Groups for Interpretability
Nov 22, 2021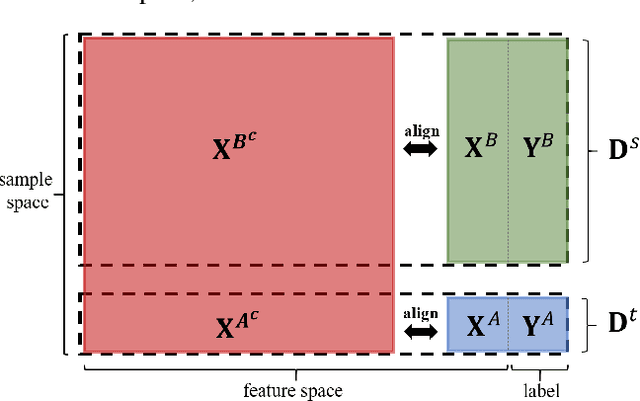
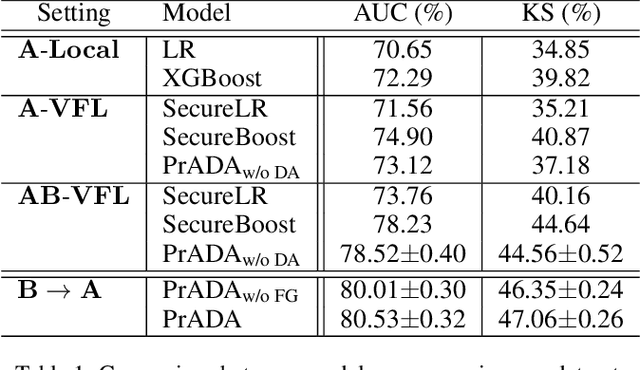
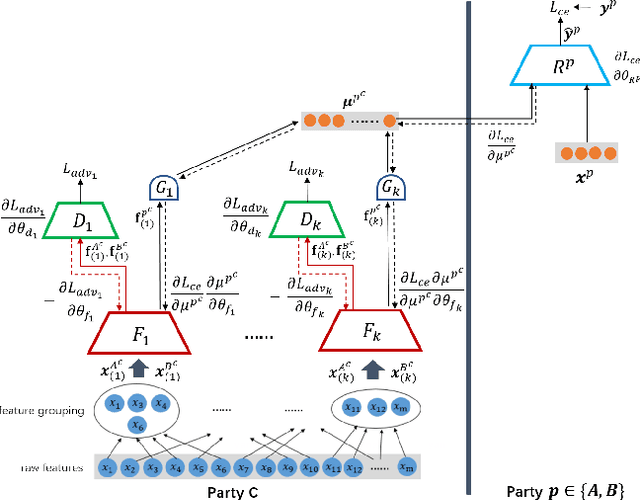
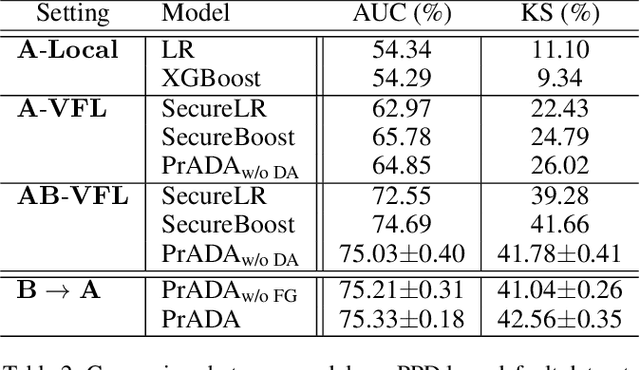
We present a novel privacy-preserving federated adversarial domain adaptation approach ($\textbf{PrADA}$) to address an under-studied but practical cross-silo federated domain adaptation problem, in which the party of the target domain is insufficient in both samples and features. We address the lack-of-feature issue by extending the feature space through vertical federated learning with a feature-rich party and tackle the sample-scarce issue by performing adversarial domain adaptation from the sample-rich source party to the target party. In this work, we focus on financial applications where interpretability is critical. However, existing adversarial domain adaptation methods typically apply a single feature extractor to learn feature representations that are low-interpretable with respect to the target task. To improve interpretability, we exploit domain expertise to split the feature space into multiple groups that each holds relevant features, and we learn a semantically meaningful high-order feature from each feature group. In addition, we apply a feature extractor (along with a domain discriminator) for each feature group to enable a fine-grained domain adaptation. We design a secure protocol that enables performing the PrADA in a secure and efficient manner. We evaluate our approach on two tabular datasets. Experiments demonstrate both the effectiveness and practicality of our approach.
FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning
Nov 16, 2021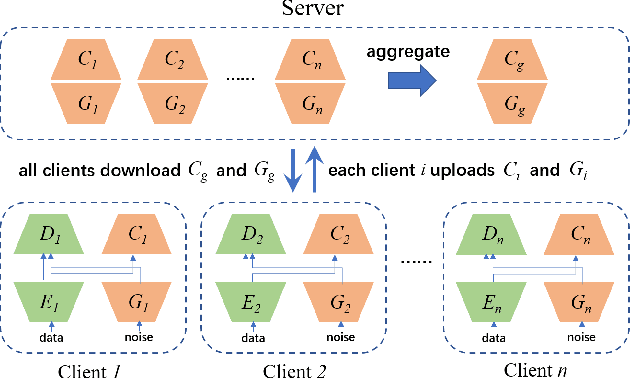
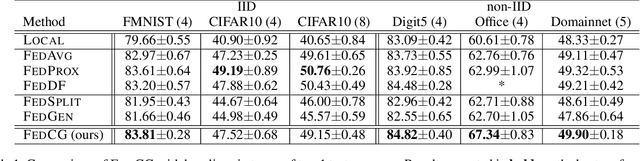
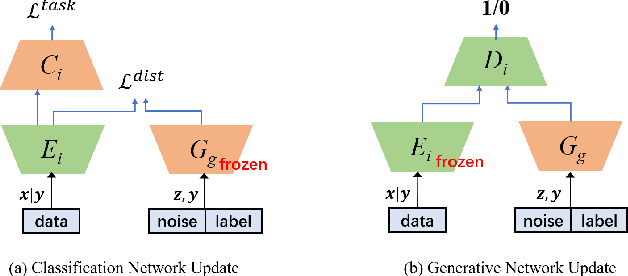

Federated learning (FL) aims to protect data privacy by enabling clients to collaboratively build machine learning models without sharing their private data. However, recent works demonstrate that FL is vulnerable to gradient-based data recovery attacks. Varieties of privacy-preserving technologies have been leveraged to further enhance the privacy of FL. Nonetheless, they either are computational or communication expensive (e.g., homomorphic encryption) or suffer from precision loss (e.g., differential privacy). In this work, we propose \textsc{FedCG}, a novel \underline{fed}erated learning method that leverages \underline{c}onditional \underline{g}enerative adversarial networks to achieve high-level privacy protection while still maintaining competitive model performance. More specifically, \textsc{FedCG} decomposes each client's local network into a private extractor and a public classifier and keeps the extractor local to protect privacy. Instead of exposing extractors which is the culprit of privacy leakage, \textsc{FedCG} shares clients' generators with the server for aggregating common knowledge aiming to enhance the performance of clients' local networks. Extensive experiments demonstrate that \textsc{FedCG} can achieve competitive model performance compared with baseline FL methods, and numerical privacy analysis shows that \textsc{FedCG} has high-level privacy-preserving capability.